Работа с LLM накладывает значительные требования к вычислительным ресурсам, особенно при инференсе (выводе) на реальных данных. Для оптимизации процесса инференса были разработаны различные бэкенды, и одним из таких решений является VLLM.
Что такое VLLM?
VLLM (Vectorized Large Language Model) — это высокопроизводительный бэкенд для инференса больших языковых моделей, разработанный с акцентом на эффективное использование памяти и вычислительных ресурсов. VLLM использует векторизацию операций и оптимизацию памяти для ускорения вывода, что делает его особенно привлекательным для приложений, где требуется высокая пропускная способность и низкая задержка.
Основные особенности VLLM:
- Эффективное использование памяти: VLLM минимизирует объем памяти, необходимый для хранения промежуточных данных, что позволяет запускать более крупные модели на устройствах с ограниченными ресурсами.
- Векторизация вычислений: VLLM использует векторизованные операции для ускорения выполнения задач, что особенно важно при работе с большими объемами данных.
- Поддержка мультизадачности: VLLM поддерживает одновременную обработку нескольких запросов, что делает его подходящим для масштабируемых приложений.
- Простота интеграции: VLLM легко интегрируется с существующими стеками для работы с LLM, такими как Hugging Face Transformers.
Для чего используется VLLM?
VLLM используется для ускорения инференса больших языковых моделей в реальных приложениях. Это может быть полезно в следующих сценариях:
- Генерация текста: Ускорение работы моделей, таких как GPT, для создания контента в реальном времени.
- Диалоговые системы: Обеспечение низкой задержки при обработке пользовательских запросов.
- Масштабируемые сервисы: Поддержка высокой пропускной способности при обработке большого количества запросов.
- Ограниченные ресурсы: Запуск крупных моделей на устройствах с ограниченной памятью и вычислительной мощностью.
Сравнение VLLM с другими бэкендами для инференса LLM
Существует несколько популярных бэкендов для инференса LLM, таких как Hugging Face Transformers, FasterTransformer, ONNX Runtime и TensorRT. Давайте сравним VLLM с этими решениями.
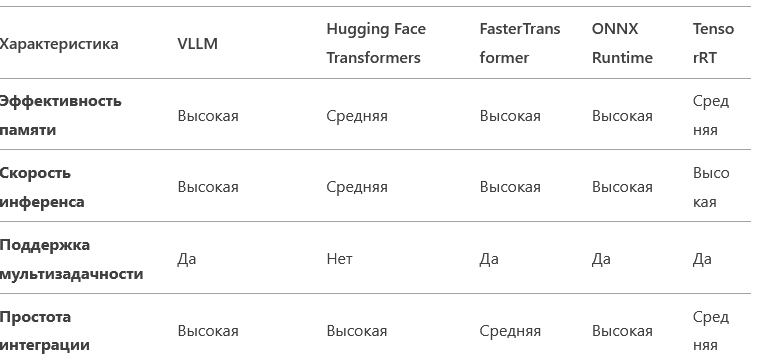
Основные преимущества VLLM:
- Эффективность памяти: VLLM превосходит Hugging Face Transformers и TensorRT в этом аспекте, что делает его идеальным для запуска крупных моделей на устройствах с ограниченными ресурсами.
- Скорость инференса: VLLM конкурирует с FasterTransformer и ONNX Runtime, предлагая высокую производительность при обработке большого количества запросов.
- Простота интеграции: VLLM легко интегрируется с существующими инструментами, такими как Hugging Face, что упрощает его внедрение в существующие проекты.
Docker-контейнер — это легковесная, автономная и переносимая среда выполнения, которая инкапсулирует приложение со всеми его зависимостями (библиотеки, конфигурации, системные инструменты и т.д.). Контейнеры создаются на основе образов, которые представляют собой шаблоны, содержащие все необходимое для запуска приложения.
Docker-контейнеры работают поверх гипервизора или операционной системы хоста, разделяя ядро с другими контейнерами, что делает их более эффективными с точки зрения использования ресурсов по сравнению с виртуальными машинами.
Docker-контейнеры удобно использовать
- Переносимость:
Приложение, запущенное в Docker-контейнере, будет работать одинаково на любой системе, где установлен Docker. Это упрощает развертывание и тестирование приложений. - Изоляция:
Контейнеры изолируют приложение и его зависимости от окружающей среды, что предотвращает конфликты между библиотеками и инструментами. - Простота управления зависимостями:
Все зависимости приложения упаковываются в образ, что избавляет от необходимости вручную устанавливать и настраивать библиотеки на каждой системе. - Масштабируемость:
Docker-контейнеры легко масштабируются, что делает их идеальным решением для создания распределенных систем и микросервисов. - Эффективное использование ресурсов:
Контейнеры используют ядро хостовой ОС, что делает их более легковесными и быстрыми по сравнению с виртуальными машинами. - Сообщество и экосистема:
Docker имеет огромное сообщество и обширную экосистему, включая Docker Hub, где можно найти готовые образы для различных приложений и инструментов.
Почему Docker идеально подходит для VLLM?
- Простота развертывания: Docker позволяет быстро развернуть VLLM в изолированной среде, не беспокоясь о конфликтах с другими библиотеками или зависимостями.
- Переносимость: VLLM, запущенный в Docker, будет работать одинаково на любом сервере или локальной машине.
- Масштабируемость: Docker упрощает масштабирование VLLM для обработки большого количества запросов.
Запуск VLLM через Docker
1. Использование готового Docker-образа
VLLM предоставляет официальный Docker-образ, который можно использовать для запуска сервера, совместимого с API OpenAI. Образ доступен на Docker Hub под именем vllm/vllm-openai.
Шаг 1: Загрузка Docker-образа
Для начала загрузите образ с Docker Hub:
docker pull vllm/vllm-openai:latest
Шаг 2: Запуск контейнера
После загрузки образа вы можете запустить контейнер с помощью следующей команды:
docker run --runtime nvidia --gpus all -v ~/.cache/huggingface:/root/.cache/huggingface --env "HUGGING_FACE_HUB_TOKEN=<secret>" -p 8000:8000 --ipc=host vllm/vllm-openai:latest --model mistralai/Mistral-7B-v0.1
Объяснение параметров:
- --runtime nvidia --gpus all: Указывает, что контейнер будет использовать GPU для ускорения вычислений.
- -v ~/.cache/huggingface:/root/.cache/huggingface: Монтирует локальный кэш Hugging Face в контейнер, чтобы избежать повторной загрузки моделей.
- --env "HUGGING_FACE_HUB_TOKEN=<secret>": Устанавливает токен доступа к Hugging Face Hub.
- -p 8000:8000: Пробрасывает порт 8000 контейнера на порт 8000 хоста.
- --ipc=host: Позволяет контейнеру использовать разделяемую память хоста, что важно для работы PyTorch.
- --model mistralai/Mistral-7B-v0.1: Указывает модель, которую нужно загрузить и использовать.
2. Сборка Docker-образа из исходного кода
Если вы хотите настроить VLLM под свои нужды, вы можете собрать Docker-образ из исходного кода.
Шаг 1: Сборка образа
Используйте предоставленный Dockerfile для сборки образа:
DOCKER_BUILDKIT=1 docker build . --target vllm-openai --tag vllm/vllm-openai
Дополнительные параметры:
- --build-arg max_jobs=8: Устанавливает максимальное количество параллельных задач при сборке.
- --build-arg nvcc_threads=2: Устанавливает количество потоков для NVCC (компилятора CUDA).
- --build-arg torch_cuda_arch_list="": Если вы хотите собрать образ только для текущего типа GPU, добавьте этот аргумент.
Шаг 2: Запуск собранного образа
После успешной сборки вы можете запустить контейнер:
docker run --runtime nvidia --gpus all -v ~/.cache/huggingface:/root/.cache/huggingface -p 8000:8000 --env "HUGGING_FACE_HUB_TOKEN=<secret>" vllm/vllm-openai <args...>
3. Настройка для версий v0.4.1 и v0.4.2
Для версий v0.4.1 и v0.4.2 Docker-образы должны запускаться от имени пользователя root, так как в процессе работы требуется загрузка библиотеки, расположенной в домашнем каталоге root. Если вы запускаете контейнер от имени другого пользователя, вам нужно изменить права доступа к библиотеке и указать её путь через переменную окружения:
docker run --runtime nvidia --gpus all -v ~/.cache/huggingface:/root/.cache/huggingface -p 8000:8000 --env "HUGGING_FACE_HUB_TOKEN=<secret>" --env "VLLM_NCCL_SO_PATH=/root/.config/vllm/nccl/cu12/libnccl.so.2.18.1" vllm/vllm-openai <args...>
4. Использование Docker Compose
Для упрощения управления контейнерами можно использовать Docker Compose. Создайте файл docker-compose.yml со следующим содержимым:
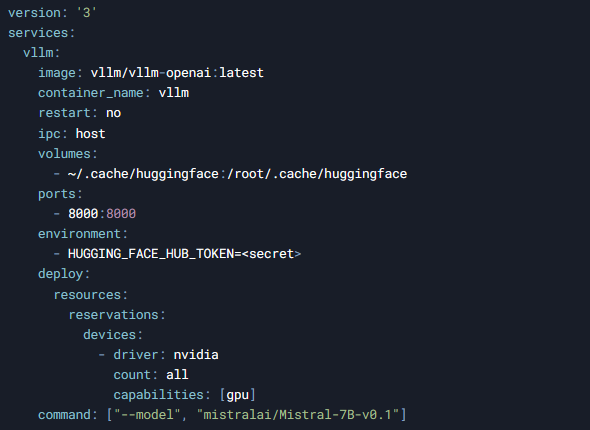
Запустите контейнер с помощью команды:
docker-compose up -d
5. Проверка работы
После запуска контейнера вы можете проверить, что сервер работает, отправив запрос через API:
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "mistralai/Mistral-7B-v0.1",
"messages": [
{"role": "user", "content": "Привет, как дела?"}
]
}'
Дополнительные аргументы работы vLLM: Улучшение производительности и функциональности
vLLM предоставляет широкий набор дополнительных аргументов, которые позволяют настроить и оптимизировать работу сервера для удовлетворения конкретных потребностей. Эти аргументы можно использовать для улучшения производительности, настройки поведения модели и добавления дополнительных функций.
Основные дополнительные аргументы
- --dtype:
Указывает тип данных для вычислений. Поддерживаемые значения: auto, half, float16, bfloat16, float, float32.
Пример: --dtype auto — автоматически выбирает наиболее подходящий тип данных для текущей модели. - --max-model-len:
Определяет максимальную длину контекста модели. Это полезно для моделей с ограниченной памятью.
Пример: --max-model-len 4096 — устанавливает максимальную длину контекста в 4096 токенов. - --chat-template:
Указывает путь к файлу или строку с шаблоном чата. Этот аргумент необходим, если модель не предоставляет встроенного шаблона чата.
Пример: --chat-template ./path-to-chat-template.jinja — использует указанный шаблон для обработки чатов. - --api-key:
Устанавливает API-ключ для сервера. Это позволяет ограничить доступ к серверу.
Пример: --api-key token-abc123 — задает ключ доступа к серверу. - --enable-auto-tool-choice:
Включает автоматический выбор инструментов для обработки запросов.
Пример: --enable-auto-tool-choice — позволяет модели автоматически выбирать инструменты для выполнения задач. - --tool-call-parser:
Указывает парсер инструментов. Поддерживаемые значения: mistral, hermes и другие.
Пример: --tool-call-parser hermes — использует парсер Hermes для обработки инструментов. - --quantization:
Включает квантование модели для уменьшения использования памяти.
Пример: --quantization bitsandbytes — использует квантование через библиотеку bitsandbytes. - --gpu-memory-utilization:
Устанавливает уровень использования GPU. Значение в диапазоне от 0 до 1.
Пример: --gpu-memory-utilization 0.8 — использует 80% памяти GPU. - --max-num-batched-tokens:
Ограничивает максимальное количество токенов, обрабатываемых за один запрос.
Пример: --max-num-batched-tokens 2048 — ограничивает количество токенов в одном запросе до 2048. - --enable-chunked-prefill:
Включает обработку входных данных по частям, что может улучшить производительность при работе с большими объемами данных.
Пример: --enable-chunked-prefill — включает обработку данных по частям.
Пример использования дополнительных аргументов
Пример команды для запуска сервера с использованием нескольких дополнительных аргументов:
vllm serve NousResearch/Meta-Llama-3-8B-Instruct --dtype auto --max-model-len 4096 --chat-template ./path-to-chat-template.jinja --api-key token-abc123 --enable-auto-tool-choice --tool-call-parser hermes --quantization bitsandbytes --gpu-memory-utilization 0.8 --max-num-batched-tokens 2048 --enable-chunked-prefill
Эта команда запускает сервер с автоматическим выбором типа данных, ограничением длины контекста, использованием шаблона чата, API-ключом для доступа, включением автоматического выбора инструментов, квантованием модели, уровнем использования GPU и ограничением количества токенов в запросе.
При работе с vLLM на системах с несколькими GPU может потребоваться увеличение объема разделяемой памяти (/dev/shm) для обеспечения стабильной работы и улучшения производительности. По умолчанию Docker выделяет только 64MB для разделяемой памяти, что может быть недостаточно для интенсивных вычислений, таких как инференс больших языковых моделей.
Зачем нужно увеличивать --shm-size при работе с несколькими GPU?
- Оптимизация обмена данными между GPU:
При использовании нескольких GPU данные часто передаются через разделяемую память. Увеличение её объема до 2GB или более позволяет избежать ошибок, связанных с нехваткой памяти, и ускорить выполнение задач. - Поддержка больших моделей:
Крупные модели, такие как Mistral-7B или LLaMA-2, требуют значительного объема памяти для хранения промежуточных данных. Увеличение /dev/shm помогает избежать переполнения памяти. - Улучшение стабильности:
При интенсивной работе vLLM с большим количеством запросов увеличение разделяемой памяти снижает вероятность сбоев и повышает стабильность системы. - Эффективное использование ресурсов:
При работе с несколькими GPU разделяемая память используется для обмена данными между устройствами, что особенно важно для распределенных вычислений.
При запуске vLLM через Docker добавьте параметр --shm-size=2gb в команду docker run:
docker run --runtime nvidia --gpus all -v ~/.cache/huggingface:/root/.cache/huggingface -p 8000:8000 --ipc=host --shm-size=2gb vllm/vllm-openai:latest --model mistralai/Mistral-7B-v0.1
Этот параметр выделяет 2GB разделяемой памяти для контейнера, что обеспечивает стабильную работу vLLM, особенно при использовании нескольких GPU.