Модель (от лат. modulus «мера, аналог, образец») - это предварительно обученный файл, в случае с графическими нейросетями, для генерации определенных изображений.
Например, если модель натренировали генерировать собак, то она будет создавать только изображения собак. Поэтому существует большое количество различных моделей, каждая из которых специализируется на определенной тематике или стиле.
❗️ Если у вас нет ни одной установленной модели, вы ничего не сможете генерировать.
Естественно, по причине многообразия моделей, их сгруппировали по типам:
1. Checkpoint (в переводе "контрольная точка") - это основные (базовые) модели, которые широко натренированы в различных областях. Например, DreamShaper v.8. Размер чекпоинтов чаще всего составляет в районе 2 Гб, но есть и модели размером больше 20 Гб.
В жизни при употреблении слов "модель" и "checkpoint" подразумевают одно и то же.
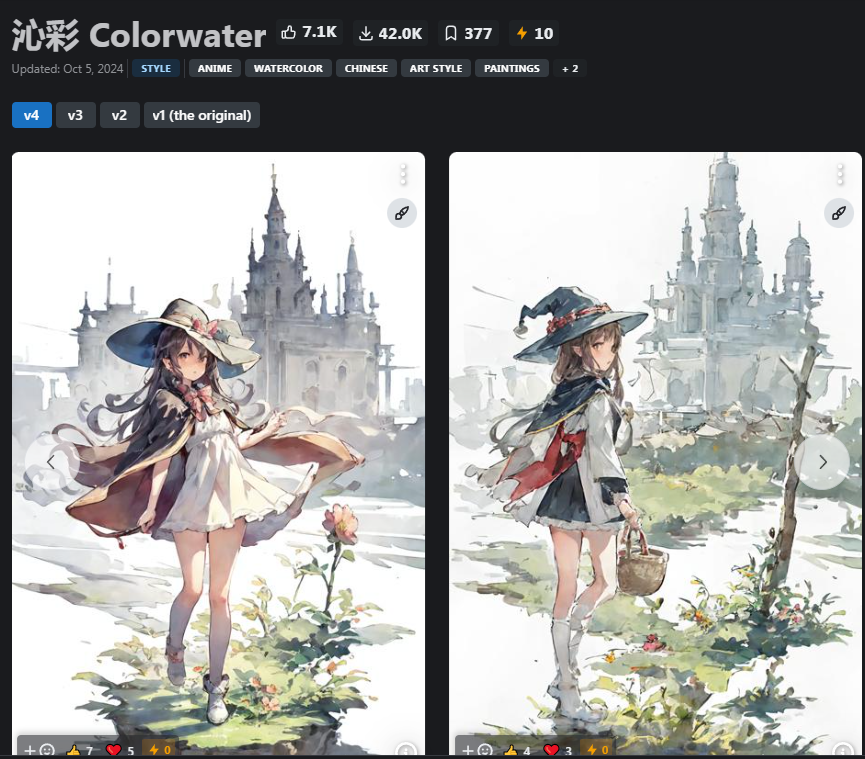
2. LoRA (расшифровывается как "Low-Rank Adaptation") - это небольшие модели, помогающие нашей основной модели (чекпоинту) восполнить пробелы связанные с различными аспектами генерации изображений. Например, создание определённого персонажа, костюма или стиля. Например, Colorwater v.4 - изображения будут нарисованы акварельными красками.
3. ControlNet (дословно в переводе "управляющая сеть") - это расширения к основной модели, которые обеспечивают больший контроль при создании изображений. Чаще всего именно ControlNet используют для редактирования или улучшения имеющихся изображений. Например, с его помощью мы можем сделать другую одежду на человеке.
4. Upscaler (в переводе upscale "увеличить масштаб, повысить уровень") - это модели, натренированные на увеличение разрешения изображений, тем самым повышая качество картинки. Например, можно увеличить изображение с 512х512 пикселей до 4K и больше.
5. VAE (расшифровывается как "Variational autoencoder") - это часть модели, которая улучшает качество изображения, делает ее более четкой и реалистичной, убирает различный шум.
6. IP-adapter (расшифровывается как "Image Prompt adapter") - это по сути модели ControlNet, которые берут за основу заданное изображение и на ее основе создают новое, при этом перенимая цвет, стиль, расположение и тд.
Все типы моделей используются и применяются к одной конкретной базовой модели нейросети (называется "Base Model").
В Invoke (как его установить здесь - https://dzen.ru/a/Z0S6eKSegl_brRZk) сейчас используются следующие Base Model:
1. Stable Diffusion 1.5 (SD 1.5)
2. Stable Diffusion XL (SDXL)
3. FLUX.1 (F.1)
4. Stable Diffusion 3.5 (SD 3.5)
Резюме: мы сперва должны для себя решить какую Base Model будем использовать сейчас для генерации, затем выбираем подходящий Checkpoint и можем писать Prompt. Дополнительно, если необходимо, добавляем LoRA и т.д.