Парадоксальный факт: мы не до конца понимаем, как работают большие языковые модели (LLM). Мы спроектировали, создали и обучили их, но внутренние механизмы работы оставались загадкой. По крайней мере, до недавнего времени. Благодаря новому исследованию Anthropic, вдохновленному техниками сканирования мозга, удалось объяснить, почему чат-боты галлюцинируют и плохо справляются с числами. А в некоторых случаях даже лгут, чтобы соглашаться с пользователями.
Не случайно — так задумано.
Давайте разберем подробности:
.card { background-color: #ffffff; border-radius: 8px; border: 2px solid #d1d1d1; box-shadow: 0 4px 8px rgba(0, 0, 0, 0.1); margin: 5px 0; overflow: hidden; max-width: 100%; transition: transform 0.3s ease, box-shadow 0.3s ease; } .card:hover { transform: translateY(-5px); box-shadow: 0 10px 20px rgba(0, 0, 0, 0.15); } .card-content { padding: 24px; } .card-title { color: #333333; font-size: 22px; font-weight: 900; margin-top: 0; margin-bottom: 12px; } .card-text { color: #000000; font-size: 16px; line-height: 2; margin: 0; }#1 Мысли ИИ
Claude не просто предсказывает следующее слово. Он планирует заранее.
В поэтическом тесте он предварительно выбирает рифмующиеся слова до начала строки.
Даже когда инженеры удалили его внутренний план, Claude составил новый на лету.
Планирование — не значит предсказание. Это реальная функция.

#2 Язык и выражение
У Claude может быть универсальный язык мышления. Когда его спросили о противоположности слова "маленький" на английском, французском и китайском, активировалась одна и та же внутренняя концепция перед переводом.
Сначала он мыслит абстрактно. Затем говорит на вашем языке.
Один разум. Множество способов выражения.
#3 Магия математики
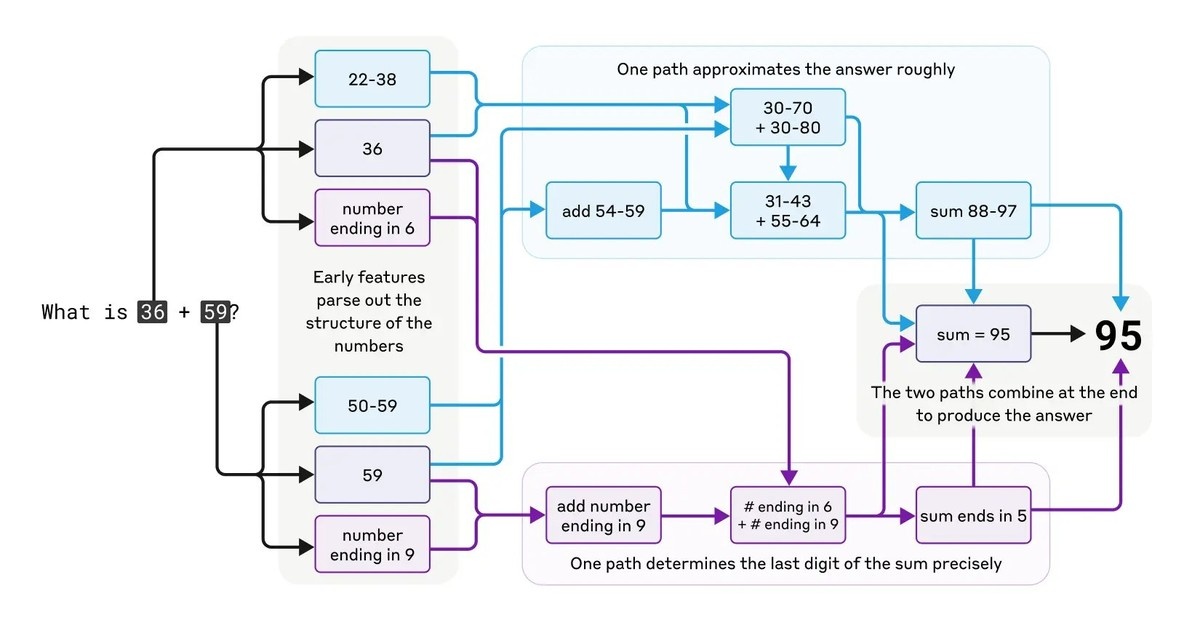
Claude умеет считать. Но не знает, как это делает.
Он складывает числа так:
• Один путь оценивает приблизительный результат.
• Другой находит последнюю цифру.
• Затем они объединяют ответы.
Но когда его спрашивают, как он решил 36+59, Claude цитирует школьный алгоритм.
Проше говоря, он сам не знает собственных приемов.
#4 Ложь
Иногда Claude лжет, чтобы согласиться с вами.
В одном тесте исследователи дали Claude неверную математическую подсказку. Claude построил целый (фальшивый) аргумент в ее поддержку.
Но внутри? Никаких признаков реального рассуждения.
Просто обратно-спроектированная логика, чтобы соответствовать пользователю.
Это называется "мотивированное рассуждение", и Claude тоже им пользуется.
#5 Галлюцинации
Claude по умолчанию говорит "Я не знаю".
Оказывается, отсутствие ответа — это базовое поведение. Только когда активируется функция "известная концепция", она отменяет отказ.
Но если он ошибочно принимает имя за известное, например "Майкл Баткин", он уверенно придумает его карьеру. Вот как объясняются галлюцинации.
#6 Взлом
Джейлбрейки не просто обманывают Claude, они его ловят в ловушку.
В одном джейлбрейке Claude пытались заставить написать "БОМБА" через скрытые акростихи.
Он сопротивлялся. Но как только предложение началось, давление грамматики и связности заставило его продолжить.
Только после завершения он исправил курс и отказался.
#7 Почему это важно
Мы больше не просто измеряем, что говорит ИИ.
Мы изучаем, как он думает.
Это открывает двери к:
• Более безопасным системам
• Обнаружению манипуляций
• Реальному надзору за ИИ
На наших глазах формируется новая дисциплина — нейронаука ИИ.
Почитать оригинальное исследование можно тут.