Скопируйте адрес нужной страницы и вставьте его на web.archive.org. Всё. Это уже результат. Если сервис нашёл архивные копии, перед вами откроется список дат, по которым можно перемещаться. Визуально. Без кода. Без плагинов. Без сложных мануалов.
Почему это вообще работает? Потому что кто-то когда-то запустил сканер, который периодически фотографирует страницы в интернете. Кто – отдельный вопрос. Важно другое: копии существуют, и их никто не удаляет. Что бы ни говорили маркетологи. Что бы ни стирал админ.
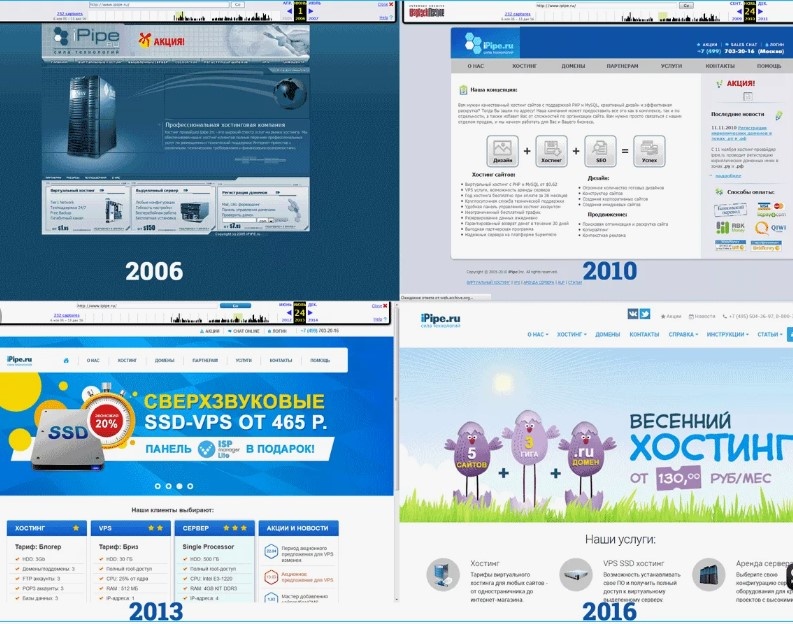
Сравните содержимое. Слово в слово. Пиксель в пиксель. Менялись ли цены? Были ли другие логотипы? Упоминался ли раньше партнёр, который теперь исчез? Всё это – не гипотезы, а конкретные факты. Архив фиксирует и внешний вид, и HTML-код. Иногда даже файлы стилей.
Ошибаетесь, если думаете, что это касается только больших порталов. Любой сайт, даже самый скромный блог, мог попасть в выборку. Один клик – и вы в прошлом. Вчера, позавчера, десять лет назад.
Почему это важно прямо сейчас? Потому что удалённая страница – не удалена. Потому что публичное заявление, которое исчезло, могло быть сохранено случайно. И потому что интернет, как ни странно, всё помнит. Но только если знать, где смотреть.
Не доверяете себе? Проверьте чужую страницу. Откройте архив за прошлый год. Сравните версию. Убедитесь. Потому что реальность может отличаться от того, что видите сегодня.
Где найти старые версии сайта в Wayback Machine
Сразу – web.archive.org. Не нужно копаться. Просто вбей адрес в строку – и всё. Магия начинается.
Появится график. Таймлайн. Массивный, местами хаотичный, но предельно честный. Годы, месяцы, дни. Снимки. Моментальные кадры прошлого. Иногда точные, иногда – обрывки. Но они есть. Это важно. Это... странно завораживает.
- Вводишь нужный URL – полностью, без сокращений.
- Жмёшь Enter. Ждёшь. Появляется календарь. Да, вот он, интерфейс архива.
- Наводишь курсор на нужную дату. Если дата кликабельна – щёлкай.
- Открывается старая версия. Да, прямо как машина времени. Только без блестящего кузова и Доктора Брауна.
Не все даты работают. Бывает, пусто. Бывает, ошибка 404, хотя снимок вроде есть. Почему? Архив не идеален. Он не робот. Он охотник. Он ловит, что может, когда может. Иногда случайно. Иногда – будто по наитию.
Хочешь точность? Используй календарь и график одновременно. Таймлайн подскажет, в какие годы снимков больше. Календарь покажет, в какие дни – чаще.
Иногда нужны детали? Жми правой кнопкой по ссылке – открывай в новом окне. Так проще сравнивать. Да, будет тормозить. Архив не любит спешку. Он работает по своим законам.
- Если нет снимков – проверь другую версию URL. С www и без. С http и https. Архив различает их.
- Используй фильтры. Да, они спрятаны, но есть. В адресной строке можно менять параметры. Экспериментируй.
- Ищи не только главную. Пробуй внутренние страницы. Категории. Посты. Часто они сохранены, даже если главная – пустая.
Это не каталог. Это не библиотека. Это не музей. Это хаос. Но в этом хаосе – структура. И если её понять, можно увидеть то, что давно исчезло. Или должно было исчезнуть.
Как сравнить разные снимки страницы для анализа изменений
Открой сразу два снимка. В разных вкладках. Пусть браузер стонет от нагрузки. Тебе нужно видеть всё. Сравнивай глазами – самый надёжный способ, когда нужны нюансы. Разметка, шрифты, баннеры, всплывающие окна. Видишь разницу? Вот и всё.
Но если вглядываться надоело – используй Diff-сервисы. Не текстовые, а визуальные. VisualPing, DiffChecker (Image Compare) или PageProbe. Загрузи два скриншота, получи чёткий отчёт. Где изменился цвет? Куда исчезла кнопка? Почему появился новый блок с формой подписки? Всё – как на ладони.
Ещё лучше – сравни HTML-код. Зачем? Потому что внешность обманчива. Внутри может прятаться JavaScript-троян. Используй code diff-инструменты: TextCompare, Meld, Kaleidoscope. Скачай исходники через DevTools, вставь в оба окна и смотри – вот он, новый трекер от Google. Раньше его не было.
А если нужно сразу много версий? Архивариус Wayback Machine умеет показывать снимки за годы. Открой вкладку “Changes” – график активности. Щёлкни на две разные даты, нажми “Compare”. И... магия. Красное – удалено, зелёное – добавлено. Ни одна строка не убежит от правды.
Фиксируй каждый шаг. Скриншоты, код, заметки. Создай свою картину – мозаику эволюции. Почему изменили текст? Почему убрали цену? Сравнение покажет мотивы. Иногда – пугающие. Иногда – гениальные.
Какие ограничения есть у веб-архива и как их обходят
Нельзя полагаться только на Wayback Machine – слишком много дыр. Первое: он не сохраняет всё подряд. Боты не ловят динамические страницы, контент за авторизацией, интерактивные элементы. Пустые оболочки вместо сути. JavaScript? Почти всегда мимо. Не видит – значит, не существует.
Решение? Использовать альтернативы: Archive.today, Perma.cc, Memento. Эти сервисы фиксируют снимки по-другому, иногда точнее, иногда – агрессивнее. Archive.today, например, обходит некоторые блокировки, игнорируя robots.txt. Да-да, то, что Wayback уважает, другие просто топчут.
Следующая проблема: удаление по запросу. Владельцы сайтов могут стереть нежелательные следы. Увидели компромат? А потом – ничего. Архив подчистили. Официально. Через форму на сайте. Без следов. Как бороться? Сохранять локальные копии. Скриншоты, сохранения в PDF, экспорт в WARC. Делать это сразу, не откладывая. Никто не гарантирует, что сохранённая версия проживёт больше суток.
Ограничение по дате – ещё одна головная боль. Некоторые страницы просто не архивировались годами. Провалы в хронологии. Что делать? Параллельный поиск в Google Cache, локальные поисковые системы, BitTorrent-снимки старых сайтов, CD-архивы энтузиастов. Да, звучит дико. Но работает. Иногда только так.
И, наконец, бан. Некоторые сайты полностью блокируют архиваторы. Прямым текстом. 403, капчи, редиректы. Выход – использовать прокси, VPN, TOR. Или вообще – ручной парсинг с эмуляцией браузера, headless Chrome, Puppeteer. Звучит как шпионский роман? Почти. Но иначе – никак.
Архив – не панацея. Это скорее теневая копия, слепок с размытым фокусом. Хотите точности – готовьтесь копать. Глубоко. Жестко. Бескомпромиссно.