Многие осведомлены об искусственном интеллекте, активно используют AI-инструменты в работе и обычной жизни, но мало кто знает, как именно нейросети обучаются. Сегодня я подробно разберу этот процесс и расскажу, какие вызовы стоят перед разработчиками. Поехали!

Обо мне:
Всем привет! На связи Константин Лачихин, финансовый инженер, аналитик, бизнес-консультант по внедрению блокчейн и крипто-технологий, майнинга, платежных решений, а также автор официальных образовательных программ по Web3 и DeFi для ведущих российских вузов.
Основа работы нейронных сетей
Почему мы в целом говорим о нейросетях в контексте ИИ? А потому что нейронные сети — это основа современного искусственного интеллекта, и их обучение представляет собой сложный, многоэтапный процесс, требующий не только технических знаний, но и глубокого понимания данных, на которых они тренируются. Но, обо всём по порядку!
Начнём с того, что нейронные сети — это математические модели, которые имитируют работу человеческого мозга. Они состоят из слоев нейронов, связанных между собой, и способны выявлять закономерности в данных. Однако, в отличие от человеческого мозга, нейросети не обладают интеллектом в привычном понимании. Их «знания» — это результат анализа огромных массивов данных. Например, если попросить нейросеть написать стихотворение, она проанализирует тысячи уже существующих стихов, выявит закономерности и создаст что-то новое на основе этих данных.
Этапы обучения нейронных сетей
В целом процесс обучения нейросетей можно разделить на несколько ключевых этапов, каждый из которых требует внимательного подхода, больших вложений и времени.
Сбор данных
Первый этап — это создание базы данных, на которой будет обучаться нейросеть. Эти данные должны быть репрезентативными и качественными. Например, для обучения модели, которая будет распознавать изображения, необходимы тысячи или даже миллионы меток с изображениями. Если данных недостаточно или они низкого качества, нейросеть будет давать неточные результаты.
Откуда берутся данные?
Открытые датасеты
Многие организации и исследовательские институты предоставляют открытые датасеты для обучения моделей. Например:
- ImageNet — набор данных с миллионами изображений, классифицированных по категориям;
- Kaggle — платформа с тысячами датасетов для различных задач;
- Common Crawl — огромный архив веб-страниц, который используется для обучения языковых моделей.
Собственные данные
В некоторых случаях компании собирают свои данные, которые лучше отражают их специфические потребности. Например, медицинские учреждения собирают данные о пациентах, а ритейлеры — о покупках клиентов.
Синтетические данные
Если реальных данных недостаточно, можно генерировать синтетические данные. Например, для обучения модели распознавания лиц можно создать искусственные изображения с помощью компьютерной графики.
Разработка промптов
Следующий шаг — это написание хорошего промпта. Промпт (prompt) — это запрос, на основе которого нейросеть генерирует ответ. Разработка качественных промптов — это целое искусство. Например, чтобы научить нейросеть решать задачи по физике, необходимо создавать запросы, которые охватывают различные аспекты этой науки. А для написания хорошего продающего текста необходимо добавить в промпт реальные маркетинговые приёмы. Так что, написать качественный промпт уже пол дела!
Я решил попросить ИИ сделать таблицу с качественным и некачественным промптом для решения задачи по математике. Давайте смотреть!
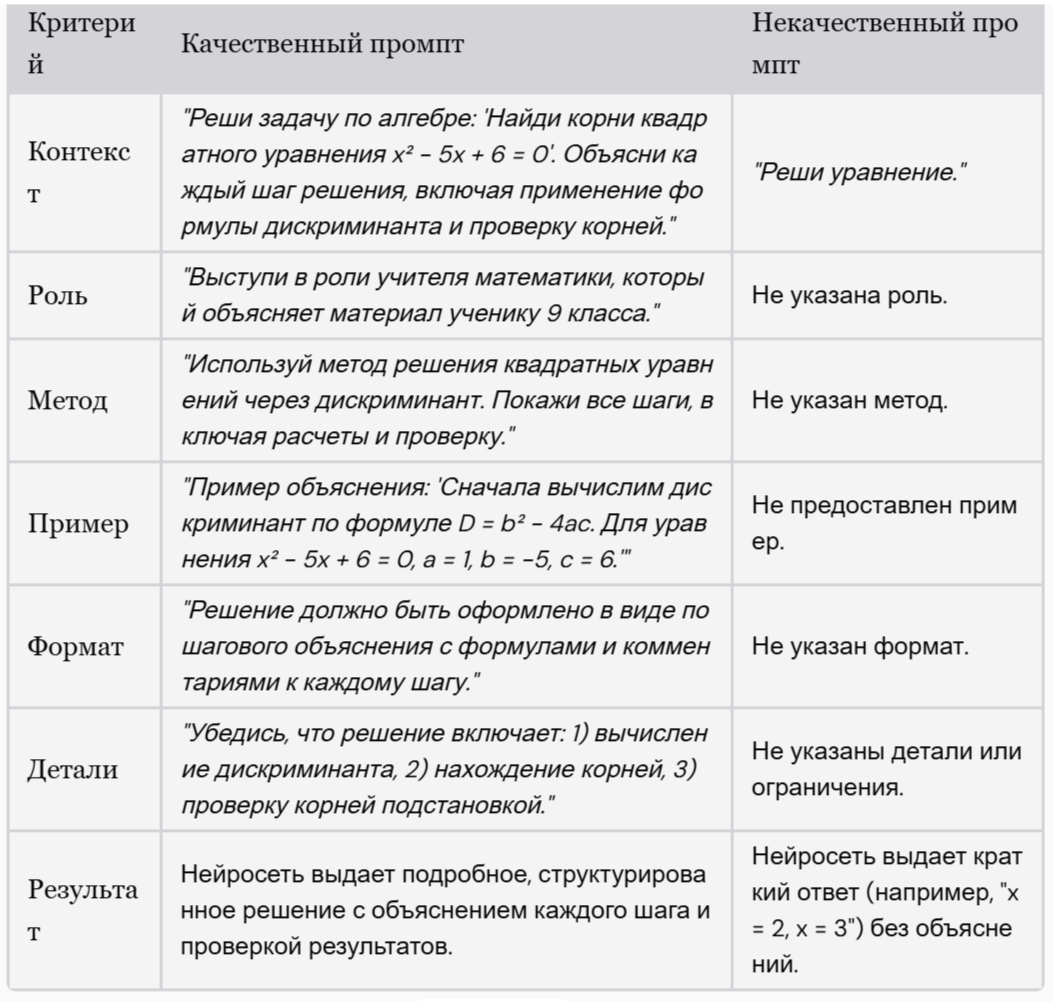
Получается, что написать 2-3 слова в промпте недостаточно. Необходимо максимально подробно расписывать шаги, метод, формат, и только тогда GPT выдаст хороший результат. Дайте знать, если хотите отдельную статью с лайфхаками, которые помогут вам лучше работать с AI-инструментами! Ну, а мы двигаемся к следующему этапу.
Сортировка данных
После сбора данных их необходимо отсортировать и структурировать. Это помогает нейросети быстрее ориентироваться в информации и выдавать более точные результаты. Например, для обучения медицинской нейросети данные могут быть разделены по категориям: заболевания, симптомы, методы лечения и так далее.
Проверка информации
Важный этап — это проверка данных на точность и надёжность. Если нейросеть обучается на ошибочных данных, она будет выдавать некорректные результаты. Например, в случае анализа геномных данных малейшая ошибка может привести к неправильным выводам о связи генов с заболеваниями. Из этого следует такой феномен, как галлюцинация нейросетей. Довольно часто ChatGPT может выдавать информацию, которой не существует, или она не достоверна. Так, например, многие студенты при написании курсовых работ обращаются к искусственному интеллекту для составления списка литературы, но вместо качественных данных он генерируют абсолютно новые исследования и авторов, которых просто напросто нет в реальности. Вот такой вам интересный факт.
Дообучение
Нейросети нуждаются в постоянном дообучении. Это связано с тем, что данные и запросы пользователей постоянно меняются. Например, разработчики OpenAI в 2024 году столкнулись с тем, что ресурсов интернета для обучения их модели оказалось недостаточно.
Какие вызовы в обучении нейросетей стоят перед разработчиками?
- Качество данных
Эффективность нейросетей напрямую зависит от качества данных. Недостаток данных или их низкое качество могут привести к ошибкам в анализе и принятии решений.
- Локальный контекст
Особенно это актуально для русскоязычных пользователей. Нейросети должны учитывать особенности языка и культуры. Если обучение проводится на англоязычных данных, то модели могут давать нерелевантные результаты для русскоязычного контекста.
- Этические вопросы
Использование нейросетей связано с вопросами конфиденциальности данных, академической честности и ответственности за принимаемые решения. Подробнее об этике искусственного интеллекта можете прочитать в моей недавней статье!
Ну, что, друзья, теперь вы знаете, что обучение нейронных сетей — это сложный и многоэтапный процесс, который требует значительных ресурсов и внимания к деталям.
А ещё больше полезной информации ищите в моем Telegram-канале! Там регулярно выходят новости по ИИ, анонсы закрытых мероприятий и полезные посты.