
Чистый код — это не только про аккуратное форматирование и понятные переменные. Настоящая "чистота" проявляется в том, насколько код устойчив к ошибкам, легко тестируется и автоматически проверяется на соответствие стандартам.
🔹 Это вторая часть статьи о чистом коде.
Если вы еще не читали первую часть — рекомендую начать с неё (доступна на моем канале). Там мы разбирали основы: именование переменных, принципы SOLID, DRY и KISS, работу с функциями и читаемость кода. А сейчас переходим к более продвинутым, но не менее важным темам.
В этой части мы углубимся в три ключевых аспекта профессиональной разработки:
- Обработку ошибок — почему try-except чаще лучше if-else, как правильно сообщать о проблемах и чем принцип EAFP выигрывает у LBYL.
- Тестирование — как тесты делают код чище, какие техники стоит применять и почему Pytestстал стандартом в Python.
- Инструменты автоматизации — как Flake8, Black и MyPy следят за качеством кода, а Gitпомогает поддерживать порядок в изменениях.
Эти практики экономят часы отладки, уменьшают количество багов и делают ваш код предсказуемым — как для вас, так и для других разработчиков. Давайте разбираться!
Типизация и аннотации
Python — язык с динамической типизацией, что делает его удобным, но также создаёт риски. Когда код разрастается, становится сложнее следить за тем, какие типы данных передаются в функции, а ошибки, связанные с некорректными типами, могут проявляться не сразу.
Аннотации типов помогают решить эту проблему, делая код понятнее и снижая вероятность ошибок.
Почему важно указывать типы?
Когда мы явно указываем, какие данные ожидает функция, это даёт три преимущества:
• Документированность — программисту (включая вас через полгода) сразу понятно, какие аргументы принимает функция и что она возвращает.
• Раннее выявление ошибок — статические анализаторы (например, mypy) могут предупреждать о несоответствиях.
• Автодополнение в IDE — современные редакторы кода лучше подсказывают, какие методы и свойства доступны для объекта.
Как работают аннотации?
Рассмотрим обычную функцию без аннотаций:
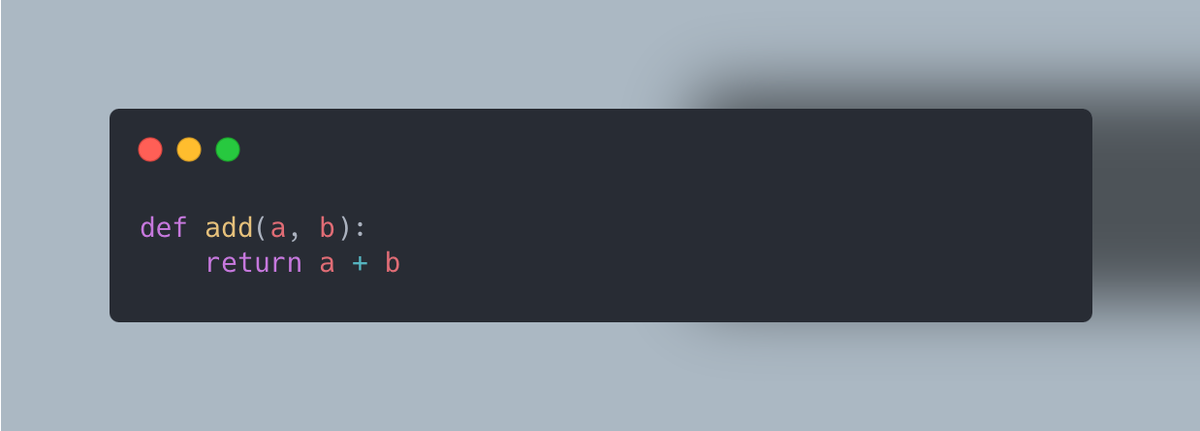
Проблема в том, что a и b могут быть чем угодно — числами, строками, списками. Это может привести к неожиданному поведению.
Используем аннотации:
Теперь понятно, что a и b должны быть целыми числами, а результат тоже будет целым числом.
Важно понимать: аннотации не заставляют Python проверять типы во время выполнения. Они работают только на уровне документации и статического анализа.
Типизация сложных структур
В простых случаях аннотации интуитивно понятны, но что если у нас сложные структуры данных?
Списки, множества и словари
Допустим, у нас есть функция, которая принимает список строк и возвращает множество уникальных значений:
Теперь любой разработчик сразу видит, что words — это список строк, а возвращаемое значение — множество строк.
Словари с разными типами данных
Если у нас есть словарь, где ключ — строка, а значение может быть int или float:
Здесь Union[int, float] означает, что значение может быть либо целым числом, либо дробным.
Работа с Optional и Any
Иногда параметры могут быть None, например, если функция возвращает результат только при определённых условиях. В таких случаях используем Optional:
Optional[str] означает, что функция может вернуть либо строку, либо None.
Если же мы вообще не знаем, какой тип будет у переменной, используем Any:
Но Any стоит применять осторожно — он убирает всю пользу от аннотаций.
Как проверять аннотации?
Поскольку Python сам не проверяет соответствие типов, можно использовать mypy:
1. Устанавливаем:
2. Проверяем код:
Если найдены несоответствия, mypy укажет на них.
Аннотации делают код понятнее и безопаснее. Они не замедляют программу, но помогают IDE и статическим анализаторам выявлять ошибки ещё до запуска. Даже если вы работаете в небольшом проекте, приучите себя использовать аннотации — это улучшит ваш код и облегчит его поддержку.
Оптимизация кода: производительность и читабельность
Чистый код — это не только про стиль и удобство чтения, но и про эффективность. Хороший код должен работать быстро, используя минимально возможные ресурсы. Оптимизация важна не только в высоконагруженных системах, но и в повседневных задачах: экономия памяти и скорости исполнения делает программы более отзывчивыми и удобными.
Как найти узкие места?
Прежде чем оптимизировать код, нужно понять, где он тормозит. Оптимизация “вслепую” часто приводит к ухудшению читаемости без реальной пользы. Вот несколько инструментов для анализа производительности в Python:
1. timeit — полезен для измерения времени выполнения отдельных операций.
2. cProfile — показывает, какие функции занимают больше всего времени.
3. line_profiler — анализирует время выполнения отдельных строк кода.
Оптимизация использования памяти
Python удобен, но из-за динамической природы расходует больше памяти, чем строго типизированные языки. Чтобы минимизировать потери, стоит использовать:
• Генераторы вместо списков, если не требуется хранить все элементы в памяти.
Неоптимальный вариант:
Оптимальный вариант:
del и gc.collect(), если объект больше не нужен и его удаление критично для памяти.
• Списки вместо кортежей, если нужна изменяемая структура данных. Кортежи занимают чуть меньше памяти, но проигрывают в гибкости.
Работа с коллекциями
Python предлагает несколько структур данных, каждая из которых подходит для определённых задач.
• Списки (list) — удобны для хранения упорядоченных элементов, но поиск в них занимает O(n).
• Множества (set) — обеспечивают быстрый поиск (O(1)), но занимают больше памяти.
• Словари (dict) — оптимальны для хранения пар “ключ-значение”.
Пример: если нужно часто проверять, есть ли элемент в коллекции, лучше использовать set, а не list:
Избегаем лишних циклов
Циклы — один из главных источников замедления кода. Если их можно избежать, код станет быстрее.
Пример неоптимального кода:
Оптимальный вариант с list comprehension:
При этом не стоит забывать про функции map и filter, если они улучшают читаемость.
Оптимизация кода — это баланс между производительностью и читабельностью. Генераторы, правильный выбор структур данных и эффективное использование памяти позволяют писать быстрые и чистые программы. Главное — не оптимизировать раньше, чем это действительно нужно, и всегда проверять результат инструментами профилирования.
Автоматизация форматирования и линтинга
Даже самый чистый код становится проблемой, если в проекте нет единого стиля оформления. Разные отступы, пробелы, несогласованные кавычки и хаотичное именование переменных затрудняют работу в команде, а иногда приводят к неожиданным ошибкам. Решение — автоматизация форматирования и анализ кода с помощью специальных инструментов.
Почему автоматизация важна?
Представьте, что вы работаете над проектом с коллегами. Один использует табуляцию, другой — пробелы, кто-то ставит точку с запятой в конце выражений, а кто-то нет. Такой код быстро превращается в нечитаемую смесь стилей.
Когда форматирование выполняется автоматически, исчезают бессмысленные споры о пробелах и кавычках, а код становится единообразным. Более того, линтеры помогают находить потенциальные ошибки и улучшать качество кода.
Black — форматирование без компромиссов
Один из самых популярных инструментов автоматического форматирования в Python — Black. Его главная особенность — строгий стиль: у него нет настроек, он просто делает код единообразным.
Установка
Применение к файлу
После этого код будет отформатирован по стандартам PEP 8.
Пример работы Black
Было:
Стало:
isort — порядок импортов
Проблема многих проектов — хаотичный порядок импортов. isort автоматически расставляет их по категориям:
1. Системные модули
2. Сторонние библиотеки
3. Локальные импорты
Установка и использование
Пример работы isort
Было:
Стало:
Flake8 — линтер для поиска ошибок
Линтеры анализируют код и находят потенциальные ошибки, нарушения стиля и неиспользуемые переменные. Один из лучших инструментов — Flake8.
Установка
Запуск анализа
Пример ошибки, которую может выявить Flake8:
Pylint — более строгий линтер
Если нужна более жёсткая проверка, стоит использовать Pylint. Он анализирует код не только на соответствие стилю, но и на потенциальные баги.
Установка и запуск
Пример ошибки от Pylint
Ошибка: функция названа не в snake_case (Pylint ожидает my_function).
Автоматизация в IDE
Чтобы не запускать команды вручную, можно настроить форматирование и линтинг в IDE:
• В VS Code (settings.json):
• В PyCharm: форматирование Ctrl + Alt + L, встроенная поддержка Black и Flake8.
Автоматизация форматирования и линтинга экономит время, устраняет стилистические расхождения и помогает находить ошибки. Использование Black, isort, Flake8 и Pylint делает код чище и понятнее, а интеграция с IDE убирает рутинные задачи.
Чистый код — это баланс между функциональностью, читаемостью и поддерживаемостью. Исключения делают его устойчивым, тесты — надежным, а инструменты — единообразным. Но главное помнить: код пишется для людей. Даже если он работает идеально, коллега (или вы через полгода) должны быстро понять его логику.
Как применять эти принципы на практике?
- Начните с малого: добавьте Flake8 и Black в проект.
- Пишите тесты перед рефакторингом — это даст уверенность.
- Документируйте ошибки и допущения прямо в коде.
- Проводите регулярные код-ревью, обсуждая не только "работает/не работает", но и читаемость.
Код — это не просто инструкция для машины. Это сообщение разработчикам будущего, и стоит сделать его ясным и элегантным.