Функции потерь являются ключевым компонентом алгоритмов Машинного Обучения. Они определяют цель, к которой должна стремиться модель, оптимизируя ее во время обучения. Другими словами, функции потерь сообщает модели, что она должна минимизировать или максимизировать, чтобы улучшить качество своих результатов.
Поэтому знание функций потерь имеет чрезвычайно важное значение. В таблице ниже показаны наиболее часто используемые функции потерь для задач регрессии и классификации:
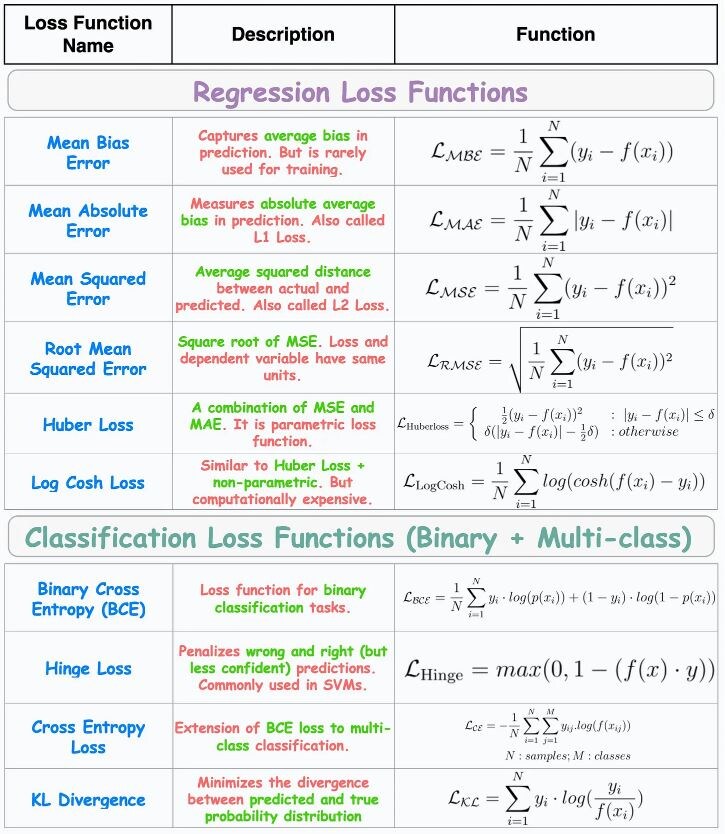
Регрессионные функции потерь
Mean Bias Error (MBE)
- Считает среднее отклонение в прогнозе
- Отрицательные ошибки могут аннулировать положительные ошибки, что приведет к нулевым потерям, и как следствие к отсутствию обновлений весов
- Редко используется в обучении ML-моделей, но является основополагающей математической конструкцией для более сложных регрессионных функций потерь, обсуждаемых ниже
Mean Absolute Error (MAE)
- Измеряет среднюю абсолютную разницу между прогнозируемым и фактическим значением
- Положительные и отрицательные ошибки не отменяют друг друга (поскольку любое число по модулю всегда положительно)
- Не чувствительна к выбросам, все ошибки будут взвешены по одной и той же линейной шкале, т.е. большие ошибки оказывают слабое влияние на конечную величину MAE.
Термин «чувствительна» – значит сильно влияет на конечную величину функции потерь, а значит более круто будут перестраиваться веса модели, «не чувствительна» – наоборот, не вносит большой вклад в конечную величину функции потерь
Mean Squared Error (MSE)
- Измеряет среднеквадратичное значение между прогнозируемым и фактическим значением
- Чувствительна к выбросам, т.к. более крупные ошибки вносят более существенный вклад, в общую величину MSE (большое число, возведенное в квадрат, кратно больше малого числа в квадрате - 3² = 9, а 10² =100), поэтому MSE «страдает» от больших выбросов, в то время как MAE - их игнорирует
- Одна из самых распространенных функций потерь для многих моделей регрессии
Root Mean Squared Error (RMSE)
- Функция потерь RMSE, по факту является MSE (среднеквадратичной ошибкой), но с квадратным корнем
- Работая с функцией MSE, приходится оперировать очень большими значениями (поскольку все возведено в квадрат), RMSE аннулирует данную проблему
- Наличие квадратного корня у RMSE, позволяет иметь одинаковые единицы измерения, как для значения потерь, так и для прогнозируемой величины. Например, у MSE, значение потерь имеет единицу измерения, возведенную в квадрат, а прогнозное значение нет (значение потерь MSE - руб², прогнозное значение – руб)
Huber Loss
- Huber Loss - комбинация средней абсолютной ошибки (MAE) и среднеквадратичной ошибки (MSE), поэтому она более устойчива к выбросам
- Для небольших ошибок используется MSE, которая не чувствительна к ним
- Для больших ошибок используется MAE, которая игнорирует их
- Основная сложность заключается в том, что добавляется еще один параметр (δ), который требуется определить
Log Cosh Loss
- Обладает всеми свойствами Huber Loss. При небольших ошибках Log Cosh стремиться к X²/2, т.е. квадратична (работает, как MSE), а при больших ошибках Log Cosh стремиться |x| - Log(2), т.е. линейна (работает, как MAE)
- Требовательна к вычислительным ресурсам
Классификационные функции потерь
Binary cross entropy (BCE) or Log loss
- Binary cross entropy - используется для задач бинарной классификации
- Измеряет с помощью логарифмической потери разницу между прогнозируемыми вероятностями и истинными бинарными значениями
Hinge Loss
- В основе лежит концепция границы, чувствительна к прогнозам вблизи границы (прогнозы возможно верные, но неуверенные) и за пределами границ (неверные прогнозы)
- Если классификация правильная и уверенная, то чувствительность низкая
- Широко используется для обучения опорных векторных машин (SVM)
Cross-Entropy Loss
- Расширение Binary cross entropy для задач многоклассовой классификации
KL Divergence
- Измеряет потерю информации, когда одно распределение аппроксимируется другим распределением
- Большие значения KL Divergence говорят о том, что распределения сильно отличаются друг от друга
- Малые значения KL Divergence, говорят о том, что модель хорошо соответствует данным
- Для задач классификации использование KL Divergance равносильно использованию минимизированной Cross-Entropy, поэтому, рекомендуется использовать Cross-Entropy напрямую / доказано ниже:
- При этом KL Divergence широко используется во многих других алгоритмах обучения, например - t-SNE
Для понимания сути работы функции потерь, читайте предыдущую статью «Функция потерь (Loss Function)»