
Доброго, соратник!
Рекомендую прочитать сначала Часть 4 - Установка (или инсталляция) FreeBSD (и 1-6 части, вдруг кто не читал).
FreeBSD имеет несколько вариантов организации файловой системы.
Это важный момент: правильная организация дисковой подсистемы - это возможность долгой бе(з)проблемной жизни вашего сервера или рабочей станции, без судорожных поисков свободного места для пользовательских данных, программ или, к примеру, системных журналов (логов. каталог var/log/).
Есть некоторая известная "фряшная" особенность в организации дисковой подсистемы: slice - по-сути это раздел диска, который затем наделялся какой-либо файловой системой. Файловая система не может существовать вне слайса, но на слайсе файловых систем может быть несколько :), а может не быть вовсе :)... Данное понятие несколько удивляло неbsdшников, но так, как ниже будет говориться про файловую систему zfs, то slice вас удивлять не будет - будет другое понятие: zpool ! Это в общем даже и не раздел (хотя вполне может им быть), а организационная единица дискового пространства в идеологии zfs - может быть в общем, чем угодно в физическом плане: дисками, файлами, некими абстрактными облаками и... содержать внутри файловые системы. Zpool - это очень удачное решение, которое позволяет полностью абстрагироваться от физической природы носителя данных и организовать всю или все файловые системы в виде единого целого - при этом добавив и автоматическое резервирование, масштабирование и (опять же) автоматический контроль целостности данных и файловой системы. И много чего ещё. Тема о самой zfs довольно объёмная - может быть стоит и более подробно рассказать - ниже будет рассказано только основное - больше, чем "в двух словах", но без подробностей.
1. Файловая система zfs. Кратко.
Файловая система zfs фактически уже стала основной в FreeBSD и для многодисковых систем (в том числе и на SSD) я рекомендую именно её, особенно, если RAM (объём оперативной памяти) больше или равен 4Гб. Для систем с одним диском небольшого размера при RAM менее 4Гб лучше использовать ufs - она тут будет работать быстрее, но даже в однодисковом варианте и при RAM менее 4Gb вполне можно использовать zfs - надо только отключить prefetch data и RAM будет использоваться менее агрессивно - zfs вообще очень любит расходовать RAM, но благодаря этому даёт очень хорошую производительность. Это достигается даже при встроенном стандартном кешировании, а есть ещё в zfs "особенное": ZIL и l2arc - применяется для ускорения и повышения надёжности файловых операций в высоконагруженных системах - обычно для этого используют SSD или иные быстрые устройства. Для "домашней системы" или рабочего компьютера это избыточно. На эту тему лучше почитать специализированную документацию.
ZFS чрезвычайно устойчива к сбоям - максимум (если, конечно, не проводить сознательных диверсий), что вам грозит - это откат к предыдущей версии файла(ов). Так же есть штатная система сохранения состояний - snapshots - создаёте и в случе чего непредвиденного восстанавливаете предыдущее состояние - собственно save и undo, если по геймерски. (немного забегая вперёд):
Создать:
# zfs snapshot zpool0/yourfilesystem@name_snap
Восстановить:
# zfs rollback zpool0/yourfilesystem@name_snap
Клонировать:
# zfs clone zpool0/yourfilesystem@name_snap zpool0/youfilesystem_clone
и т.д.
Знайте, что это возможно и делается относительно просто - будем иметь ввиду, пока же начнём с начала.
Поработаем c zfs на примере варианта с ручной настройки файловой системы при инсталляции FreeBSD.
2. Организация файловой системы zfs на FreeBSD.
Есть несколько вариантов организации дисковой системы в целом: это MBR и GPT.
MBR рассматривать не будем - описано сотни раз, да и сейчас уже считается устаревшей, в силу различных причин.
GPT же "правильнее и лучше" - главное преимущество: не имеет ограничений на количество разделов (slice), тогда, как в MBR - всего 4 раздела.
В zfs есть вариант непосредственного использования дисков вообще без MBR или GPT - загрузчик ОС и саму fs можно разместить непосредственно на рабочую поверхность дисков не делая никакой разбивки на разделы - zfs сама разберётся, как организовать дисковое пространство - оно будет полностью отдано ей.
Стандартной файловой системой долгое время в FreeBSD была ufs.
В FreeBSD 7 в системе появилась zfs в качестве экспериментальной. Начиная же с FreeBSD 10 по-умолчанию предлагается именно zfs.
Варианты GPT+zfs или zfs напрямую на диск? Что лучше?
- ZFS с GPT и ZFS без GPT?
Попробую сформулировать плюсы каждого способа. Да, положительные особенности одного метода вовсе не являются недостатками другого и наоборот.
ZFS без GPT:
- заметно меньше ручной работы.
- отпадёт необходимость правки файла монтирования файловых систем - zfs всё возьмёт на себя:
- простота работы с пулом
- нет возможности загрузиться с UEFI, только "Legacy BIOS"
ZFS с GPT:
- переносимость
- независимость от физических дисков - замена диска с присвоением ему такого же лейбла не потребует реорганизации пула, только манипуляций с синхронизацией
- возможность применение шифрации и традиционного подхода с fstab
- устойчивость к "перепутыванию" дисков - OS присваивает имена по мере обнаружения, тогда, как лейблы остаются независимы от очерёдности подключения дисков. Бывают настройки и конфигурации, когда это важно
- загрузка с UEFI;
В принципе варианты идентичны по надёжности. По моему же скромному мнению, вариант с GPT имеет несколько более гибкий вариант по возможностям расширения дискового пространства и так же по возможностям конфигурирования загрузки, организации системы подкачки и некоторых других возможностей. Но "прямой" вариант подкупает тем, что он проще и как-то целостнее что ли - не порождает "лишних" сущностей.
Итак, начнём.
Допустим, что у нас реальная железная система (для виртуальной разницы в общем не будет - разве, что названия устройств могут быть другими). Диски у нас в количестве 3 шт. HDD SATA одинакового размера, новые не размеченные - будем создавать дисковый пул типа raidz1 с избыточностью размером в один диск. То есть при убиении одного диска система не умрёт. Умрёт, только, если сразу два диска выйдут из строя. Если у вас два или более, то можно создать иную конфигурацию raid: stripe (объединение - любое количество дисков от одного), mirror (зеркало - два диска один уходит на избыточность) или raidz2 (массив с избыточностью - пять дисков - два на избыточность).
Для дисков SATA (как HDD, так и SSD) система присвоит имена устройств (находятся в разделе /dev) : ada0, ada1, ada2, (ada3, ada4 и т.д.). Если тиски типа SCSI/SAS (для флэш носителей тоже): da0, da1, da2, ... Для дисков SSD с интерфейсом nvme2: nvd0, nvd1, nvd2, ...
Соответственно, если у вас тип дисков иной, то в командах связанных с работой с непосредственно с устройствами, ниже все "ada" SATA устройства меняем на "da" или "nvd". Например посмотрим список устройств:
# ls -1 /dev/ada*
для nvme это будет команда
# ls -1 /dev/nvd*
Замечание: символ "решётка" # далее означает начало командной строки и права при выполнении команд от имени суперпользователя root - в этом случае команды - в том числе разрушительные для системы - выполняются беспрекословно. Будьте внимательны.
Загружаемся c флэшки-инсталлятора и делаем как тут.
Доходим до момента, когда нам предлагают создать файловые системы:
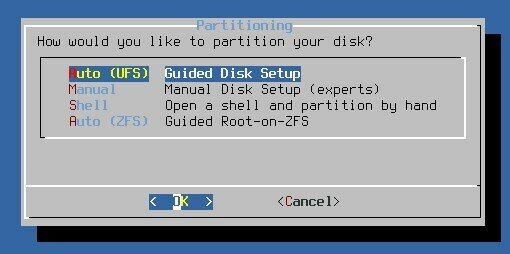
Нам нужен вариант полностью ручного создания - Manual - не совсем подходит - это тоже создание системы через программу инсталлятор, нам же надо полность ручное в режиме выдачи соответствующих команд. Поэтому выбираем 'Shell' и Оказываемся в shell... то есть командной строке.
Для начала выясняем, как у нас поименованы HDD/SSD - это можно увидеть в каталоге dev:
# ls -1 /dev/ada*
/dev/ada
/dev/ada1
/dev/ada2
Для работы с zfs и дисками в FreeBSD имеется набор утилит: gpart, zpool, zfs. Есть ещё старая, добрая утилита dd - которая позволяет работать с содержанием файлов, дисковых разделов - с любым объектом, которые содержат данные. Нам она понадобится для копирования разделов диска.
Очистка дисков.
На всякий случай очистим системные области дисков, которые обычно располагаются в самом начале. Кто его знает, что там на них, будь они и новые.
Разрешаем работу с дисками в системе "напрямую" (обычно стоит запрет), иначе получим ругань и отбой операции даже под root:
# sysctl kern.geom.debugflags=0x10
Выдадим команду dd, которая запишет нам нужную информацию для очистки на наши диски:
# dd if=/dev/zero of=/dev/ada0 bs=1M count=100
запишет же она из устройства /dev/zero, которое генерирует при вызове 0 (ноль) на устройство /dev/ada0 (наш первый по счёту диск) блок данных размером 1мегабайт в количестве 100 штук, которые гарантированно затрут на диске, всю информацию о его прошлой разметке. По выполнению команда выдаст отчёт о проделанной работе:
100+0 records in
100+0 records out
104857600 bytes transferred in 0.436933 secs (239985644 bytes/sec)
Повторяем команду для остальных двух дисков:
# dd if=/dev/zero of=/dev/ada1 bs=1M count=100
# dd if=/dev/zero of=/dev/ada2 bs=1M count=100
2. Создание разделов на дисках.
Далее работаем с gpart. Эта утилита используется для разметки диска.
Если выдать её на исполнение без параметров - получим справку:
# gpart
usage: gpart add -t type [-a alignment] [-b start] [-s size] [-i index] [-l label] [-f flags] geom
gpart backup geom
gpart bootcode [-b bootcode] [-p partcode -i index] [-f flags] geom
... (пропущено) ...
gpart load [-v]
gpart unload [-v]
Для нашей системы, обеспечивающей загрузку и хранение данных нам нужно создать четыре раздела на каждом диске:
1. загрузочный раздел EFI - тут расположится загрузчик OS для систем с поддержкой UEFI.
2. загрузочный раздел GPT - тут расположится загрузчик OS для систем с поддержкой BIOS.
3. раздел для устройства подкачки или свопинга - сюда система будет сбрасывать данные из оперативной памяти в случае её нехватки, - полезная штука в общем.
4. разделы собственно под zfs - тут будет всё остальное: Операционная система и всё наше добро.
Инициализируем на дисках схему разметки GPT:
# gpart create -s gpt /dev/ada0
# gpart create -s gpt /dev/ada1
# gpart create -s gpt /dev/ada2
Создаём сначала загрузочный раздел - он должен быть одинаковый на всех дисках - ведь при потере бойца его знамя подхватит следующий в очереди загрузки или тот, что вы назначите в "BIOS":
# gpart add -a 4k -s 250M -t efi -l efi0 ada0
# gpart add -a 4k -s 250M -t efi -l efi1 ada1
# gpart add -a 4k -s 250M -t efi -l efi2 ada2
Создаём загрузчик "Legacy BIOS":
# gpart add -a 4k -s 512k -t freebsd-boot -l boot0 ada0
# gpart add -a 4k -s 512k -t freebsd-boot -l boot1 ada1
# gpart add -a 4k -s 512k -t freebsd-boot -l boot2 ada2
-a 4k - выравнивание разделов по границам 4к, -s 512k - размер в килобайтах, -t тип, -l метка.
Метка или лэйбл - это важный момент, как выше я упоминал: с помощью этого параметра можно создать из любого диска, раздела, именованное псевдоустройство. Они будут находиться в /dev/gpt. Чем это удобно: можно, заменяя диск, задать новому такую же метку и система "не заметит" подмены, например, для дискового массива всё останется, как было - имя тоже, а значит всё ок. Правда, отсутствие данных систему удивит, но массив автоматически восстановится стоит лишь выдать соотв. команду.
Создаём раздел подкачки. Так, как у нас в системе 4096M RAM, то делим на 3 получаем ~1366Мб на каждый диск:
# gpart add -a 4k -s 1366M -t freebsd-swap -l swap0 ada0
# gpart add -a 4k -s 1366M -t freebsd-swap -l swap1 ada1
# gpart add -a 4k -s 1366M -t freebsd-swap -l swap2 ada2
Система потом эти три диска объединит в один swap раздел.
Создаём собственно раздел, где будет располагаться сама zfs:
# gpart add -a 4k -t freebsd-zfs -l zdisk0 ada0
# gpart add -a 4k -t freebsd-zfs -l zdisk1 ada1
# gpart add -a 4k -t freebsd-zfs -l zdisk2 ada2
Тут не нужен -s параметр - всё оставшееся свободное место на диске будет отведено под zfs раздел.
Смотрим, что вышло:
# gpart show
=> 40 1000215136 ada0 GPT (477G)
40 532480 1 efi (260M)
532520 1024 2 freebsd-boot (512K)
533544 2805760 3 freebsd-swap (1.3G)
3339304 999681632 4 freebsd-zfs (477G)
=> 40 1000215136 ada1 GPT (477G)
40 532480 1 efi (260M)
532520 1024 2 freebsd-boot (512K)
533544 2805760 3 freebsd-swap (1.3G)
3339304 999681632 4 freebsd-zfs (477G)
=> 40 1000215136 ada2 GPT (477G)
40 532480 1 efi (260M)
532520 1024 2 freebsd-boot (512K)
533544 2805760 3 freebsd-swap (1.3G)
3339304 999681632 4 freebsd-zfs (477G)
Выдав команду с ключами -lp получим отображение по меткам и названиям физических устройств для файловой системы /dev:
# gpart show -lp
Ну вроде всё в порядке - разделы есть. Главное ничего не перепутать, а то потом переделывать всё с начала придётся.
3. Создание пула zfs.
"Для работы с zfs есть набор утилит", сейчас понадобится две из них:
zpool - управляет пулами zfs,
zfs - управляет файловыми системами zfs в пуле zfs... (ну, что делать такое вот либретто в этой пьессе другого нет...)
Если выдать команду zpool, то она как и gpart выдаст список подкоманд...
Создаём пул типа raidz1 - "три диска - размер одного на резервирование":
# zpool create -o altroot=/mnt zpool0 raidz1 /dev/gpt/zfs0 /dev/gpt/zfs1 /dev/gpt/zfs2
Если, хоть один из дисков был раньше в составе любого пула zfs, то команда завершится сообщением, что диск был в составе пула zfs и пул не создастся. Если вы уверены, что диск от "старой" системы точно не нужен, то для решения вопроса надо выдать команду с ключoм -f :
# zpool create -f -o altroot=/mnt zpool0 raidz1 /dev/gpt/zfs0 /dev/gpt/zfs1 /dev/gpt/zfs2
-f - указание о безусловном выполнении команды.
-o altroot=/mnt - указание смонтировать пул в в точку /mnt - инсталлятор будет работать при установке системы с ним.
zpool0 - название пула, может быть произвольным,
raidz1 - тип массива, (из общего объёма - объём равный одному диску уйдёт на избыточность),
/dev/gpt/zfs0 /dev/gpt/zfs1 /dev/gpt/zfs2 - устройства которые включаем в пул.
При создании пула производится автоматическое его монтирование в указанный каталог файловой системы, так же создаётся единственная файловая система zpool0, которую по некоторым идеологическим соображениям, не используют напрямую. Её надо в общем отмонтировать и задать свойства, которые не позволят ей быть использованной:
# zfs set canmount=off zpool0
Строго говоря, использовать её можно и вопросов как бы не возникает, но есть ещё одно соображение - при апгрейдах системы от этой файловой системы удобно создавать альтернативные начальные файловые системы для /.
В принципе, если ничего сверхоргинального от файловой системы не нужно - то на этом создание файловой системы в принципе завершено - можно вернуться в инсталлятор набрав exit и продолжить установку OS и... успокоиться. Но мы же всё делаем правильно? А у zfs столько интересных возможностей заложено, что иногда кажется, что её придумал гений... :). Поэтому в данном случае с исследовательской целью, а в принципе часто в системном администрировании требуется и реально сделать всё в ручную.
Полагаю, что мог возникнуть вопрос... А, где тут классическое "форматирование" диска? Дело в том, что "форматирование", как таковое - это не некая нарезка, как, например, на лазерном диске это реальный прожиг питов или структуры намагниченностей на древних дискетах, а указание соотв. областям жёсткого диска о том или ином характере использования его внутренней, заранее определённой устройством дисковой поверхности. Поэтому, как таковое форматирование в принципе для HDD не производится, а просто прописываются некоторые свойства на HDD и всё.
Проверяем:
# zpool list
NAME USED AVAIL REFER MOUNTPOINT
zpool0 147G 1,61T 40,0K /mnt
Корневая файловая система пула zpool0 будет использоваться, как "контейнер свойств" для остальных файловых систем, что будут расти из неё, - не придётся задавать одинаковые свойства каждой из файловых систем. Назначение на этой корневой файловой системе какого-либо свойства - его значение распространится, на наследуемые - автоматически.
Устанавливаем значение atime=off в коневой файловой системе, чтобы не тратилось усилий на ненужные, в данном случае, нам постоянные отметки о последнем доступе к файлам. В домашней (да в общем-то и в большинстве серверных и рабочих конфигурациях и применениях) они не нужны и часто отключены по-умолчанию, но лучше сказать это конкретно:
# zfs set atime=off zpool0
Это сообщит файловым системам, что не надо фиксировать "время последнего обращения к файлам" так, как файлов много, то на эту отметку будет тратится лишняя работа. Иногда это правильный подход: в тех системах, где много файлов и к ним идёт интенсивное обращение, а вот если важно то можно поступить и наоборот.
Экспортируем и отключаем пул:
# zpool export zpool0
Импортируем пул снова, указывая для него в параметре altroot=/mnt точку монтирования в существующей файловой системе:
# zpool import -o altroot=/mnt zpool0
Кстати, если вам вдруг не нравится название пула zpool0, то задав в предидущей команде вместо zpool0 любое другое - вы сможете переименовать созданный пул... Только будьте внимательны далее во всех командах, где используется имя пула!.
# zpool import -o altroot=/mnt zpool0 newmynamepool
Ещё две полезные команды.
Просмотр всех свойств пула:
# zpool get all zpool0
Всех файловых систем всех пулов:
# zfs get all
4. Создание файловых систем.
Выдача команды zfs без параметров... да, да, да... выдаст набор подкоманд.
Создаём нужные файловые системы:
# zfs create -o mountpoint=none -o compression=off zpool0/ROOT
# zfs create -o mountpoint=/ -o compression=on zpool0/ROOT/default
# zfs create -o mountpoint=none -o compression=off zpool0/usr
# zfs create -o mountpoint=/usr/home -o compression=on zpool0/usr/home
# zfs create -o mountpoint=/usr/local -o compression=on zpool0/usr/local
# zfs create -o mountpoint=/usr/local/www -o compression=on zpool0/usr/local/www
# zfs create -o mountpoint=/usr/ports -o compression=on zpool0/usr/ports
# zfs create -o mountpoint=/usr/ports/distfiles -o compression=off /usr/ports/distfiles
# zfs create -o mountpoint=/usr/src -o compression=on zpool0/usr/src
# zfs create -o mountpoint=/usr/store -o compression=off zpool0/usr/store
# zfs create -o mountpoint=/usr/store/archive -o compression=off zpool0/usr/store/archive
# zfs create -o mountpoint=/usr/store/backups -o compression=off zpool0/usr/store/backups
# zfs create -o mountpoint=/usr/store/system -o compression=off zpool0/usr/store/system
# zfs create -o mountpoint=none -o compression=off zpool0/var
# zfs create -o mountpoint=/var/crash -o compression=on zpool0/var/crash
# zfs create -o mountpoint=/var/db -o compression=off zpool0/var/db
# zfs create -o mountpoint=/var/log -o compression=on zpool0/var/log
# zfs create -o mountpoint=/var/squid -o compression=off zpool0/var/squid
Вывести свойства конкретной файловой системы указанного пула:
# zfs get all zpool0/ROOT/default
Пара замечаний:
- Почему именно такой набор файловых систем? - У вас может быть любой набор по вашему желанию, но в данном случае это будет универсальный сервер под различные роли. И логика работы файловой системы zfs (и вообще идеология файловых систем unix) такова, что например, некоторые свойства можно назначить только на файловую систему, а не на каталог или файл. Например, предоставить в сетевой доступ посредством nfs (network file system) можно только именно файловой системе, например:
zfs set sharenfs="-alldirs -maproot=root network 172.23.64.0 -mask 255.255.255.0"
доступ посредством nfs - network file system.
Так же назначаются свойства компрессии, шифрации, дедупликации и пр.
- Почему компрессия назначена в одном случае и отменена в другом? - Тоже довольно простой принцип: зависит от характера данных, которые преимущественно будут храниться в этих конкретных каталогах в этой файловой системе. Рассмотрим на конкретном примере:
/usr/ports - здесь располагается, так называемая система портов freebsd - набор всего имеющегося в FreeBSD ПО, которое поставляется в исходных кодах. port, скачивается из сетевого репозитория, производится его сборка (компиляция) из исходных кодов - и уже бинарный код устанавливается в систему. Некоторые говорят, что это устаревший и архаичный способ установки ПО. Да, в чём-то это так, но установка таким образом, позволяет иметь всегда актуальную версию ПО, собранного только с нужными ВАМ опциями, под ВАШУ, конкретную, систему и, при необходимости, Вы сами сможете добавить правки в исходный код, внести нужные вам изменения. Да, некоторое ПО собирается значительное по длительности время и даже несколько суток. Некоторое вообще не сможет собраться, тут уж никуда не денешся всякое бывает... Исходные коды представляют собой, как правило преимущественно текстовые файлы и очень хорошо могут быть сжаты утилитами сжатия или, в данном случае, сжаты самой zfs. В этой же файловой системе будет производиться и сама сборка и промежуточное хранение собираемого ПО, которое так же, как правило, хорошо "сжимается". Выгода бывает часто от 50% и выше: экономится дисковое пространство, а для SSD ещё и продлевает время жизни ячеек хранения - они имеют конечное время циклов перезаписи
А вот, например /usr/ports/distfiles не имеет установленного атрибута компрессии - она там попросту не нужна. Это специальный каталог в системе портов, куда перед компиляций выбранного ПО скачивается из репозитория (обычно из Интеренет) в виде архивов исходных кодов. Как правило, они заранее упакованны gzip, bzip2, xz или другими архиваторами... То, есть данная файловая система, имея атрибут включённой компрессии, пыталась бы сжать уже сжатые данные, а это явно лишнее - эффективность такого действия может быть крайне малой или даже иметь обратный эффект, а вот затраты вычислительных ресурсов всегда н аэту операцию будут значительными.
Параметр compression=lz4 - означает применить алгоритм lz4 - на сегодня это самый быстрый и эффективный алгоритм сжатия. Можно указать compression=on - будет задействован алгоритм по умолчанию - какой именно зависит от версии zfs на сегодня по умолчанию применяется именно lz4.
Таким вот простым подходом можно сравнительно просто оптимизировать свободное пространство на дисковой системе.
Есть ещё одно похожее свойство: "дедупликация".
Параметр dedup обеспечивает включение этого свойства. Оно позволит исключить, по мере возможности, наличие одинаковых последовательностей блоков в файловой системе в целом, независимо от принадлежности их к тому или иному файлу. Например, помещённый в пределах одной файловой системы - один и тот же файл, но в разных каталогах? Логично иметь одну физическую копию пока они инентичны.
А вот, если содержимое в одной из его ипостасей изменится, к примеру будут добавлены строки при редактировании, то zfs произведёт их автоматическое разделение на количество байт, что стало различным и вторая копия будет содержать только РАЗЛИЧИЯ от первого.
Или другой вариант: в полностью разных файлах, есть одинаковая и значительная по размеру последовательность байт - она в одном из файлов будет заменена "ссылкой" на фрагмент в другом. Это ещё даст экономию свободного пространства. Вариантов такого перекрёстного "содержания" байтовых последовательностей довольно много.
Но dedup, при всей своей привлекательности, всё-таки имеет некоторую неочевидность и алгоритмическую сложность. При определённых ситуациях может быть значительно ресурсозатратен, как вычислительно, так и по отношению к пространству диска и может иметь так же обратный ожидаемому эффект. Это надо оценивать по конкретной ситуации. Если у вас есть, например, много видеофайлов, которые вы редактируете - очевидно, что у вас будет много копий одного и того же или варинатов одного и того же фрагмента, или реадактированного материала, то в этом случае dedup даст нужный эффект, а вот, если много мелких и различных файлов или совершенно различных больших, то вряд ли оценка даст нужный эффект, а вот вычислительных ресурсов будет потрачено много. Наверное алгоритм этого как-то будет изменяться в будущих версиях zfs и в эру полного ИИ будет учтён каждый байт, но пока оценить целесообразность этой операции нужно вам. Попробовать нам ничего не мешает.
Последнее, что надо сделать в этом пункте - назначить корневую файловую систему:
# zpool set bootfs=zpool0/ROOT/default zpool0
Она будет содержать OS со всем её содержимым и это будет точка откуда будет начинаться дерево файловой иерархии системы и ей будет присвоена точка монтирования - каталог "/".
Теперь, рассмотрим вариант, как сделать файловую систему без GPT :) - непосредственно на дисках без создания специализированых разделов.
4. Дисковый массив zfs. Вариант без GPT разметки.
Делаем так же, как выше, но не используем gpart. То есть пункт
"2. Создание разделов на дисках." - пропускаем полностью. То есть у нас "чистые диски без какой-либо разметки".
Создаём пул указывая сразу диски, а не созданные, как ранее, разделы:
# zpool create -o altroot=/mnt zpool0 raidz1 /dev/ada0 /dev/ada1 /dev/ada2
Всё остальное без изменений - создаём файловые системы, так же, как и выше.
Создаём, теперь уже иначе, область подкачки:
# zfs create -V 4G -o compression=off -o checksum=off zpool0/swap0
-V 4G - размер утройства подкачки.
-o compression=off -отключение компресии
-o checksum=off - отключение контрольных сумм - в этой специфической файловой системе и так всё надлежащим образом контролируется.
Кстати, в варианте с GPT можно было поступить так же и не создавать отдельных разделов swap.
Указываем, что это именно устройство подкачки:
# zfs set org.freebsd:swap=on zpool0/swap0
При загрузке OS и монтировании пула, подключение устройства произойдёт автоматически. Прописывать подключение, как раньше в случае отдельного раздела под него в файле /etc/fstab ненужно.
Копируем загрузчик OS непосредственно на дисковые устройства:
# dd if=/boot/zfsboot of=/dev/ada0 count=1
# dd if=/boot/zfsboot of=/dev/ada0 iseek=1 oseek=1024
# dd if=/boot/zfsboot of=/dev/ada1 count=1
# dd if=/boot/zfsboot of=/dev/ada1 iseek=1 oseek=1024
# dd if=/boot/zfsboot of=/dev/ada2 count=1
# dd if=/boot/zfsboot of=/dev/ada2 iseek=1 oseek=1024
Всё повторяем за исключением того, что в /mnt/etc/fstab - файл описания монтирования файловых систем, ничего не добавляем.
5. Завершаем настройку.
Отключаем пул:
# zpool export zpool0
Подключаем с указанием, где создать кеш пула:
# zpool import-o cachefile=/tmp/zpool.cache -o altroot=/mnt zpool0
Далее набираем:
# exit
и выходим в инсталлятор FreeBSD установка автоматически продолжится.
Затем выйдя на заверщающий диалог инсталлятора:
Попадаем снова в shell (Alt-F4). Работаем как root. Пароль запрошен не будет - сразу перейдёте в приглашение командной строки.
Напоминаю, что наша будущая система находится в /mnt - это сейчас наш рутовый путь для свежеустановленной системы. В / - находится рутовая система инсталлятора. Не перепутайте! Делайте правки используя правильные пути файловой системы!
Так же обращаю внимание, что комманды gpart и dd являются низкоуровневыми - то есть вносят изменения непосредственно на диски и невнимательность к точности в задании параметров может привести к неработоспособности системы.
Помещаем в загрузочные разделы код загрузчика.
Для UEFI:
Cоздаем файловую систему fat для efi0 (ada0p1), efi1 (ada1p1), efi2 (ada2p1),
# newfs_msdos /dev/ada0p1
# mkdir -p /mnt/boot/efi0
# mkdir -p /mnt/boot/efi1
# mkdir -p /mnt/boot/efi2
# mount_msdos /dev/ada0p1 /mnt/boot/efi0
# mkdir -p /mnt/boot/efi0/efi/boot/
# mkdir -p /mnt/boot/efi0/efi/freebsd/
Этих загрузчиков в /boot несколько. Смотрим какие у нас есть загрузчики:
# ls -1 /boot/loader*
/boot/loader.efi
/boot/loader_4th.efi
/boot/loader_lua.efi
/boot/loader_simp.efi
- можно выбрать любой - отличаются картинками при загрузке.
Копируем:
# cp /mnt/boot/loader.efi /mnt/boot/efi0/efi/boot/bootx64.efi
# cp /mnt/boot/loader.efi /mnt/boot/efi0/efi/freebsd/loader.efi
# umount /mnt/boot/efi0
Для второго и третьего (и т.д.) диска просто продублируем этот раздел с первого на второй и третий (и т.д.):
# dd if=/dev/ada0p1 of=/dev/ada1p1 bs=1M
# dd if=/dev/ada0p1 of=/dev/ada2p1 bs=1M
Для классической "BIOS" (или варианта загрузки "Legacy BIOS" в современной UEFI):
# gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 ada0
# gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 ada1
# gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 ada2
(Кстати, если используется UFS, то загрузчик надо использовать другой: gpart bootcode -b /boot/pmbr -p /boot/gptboot -i 1 ada0)
И так же копируем кеш нашей zfs:
# cp /tmp/zpool.cache /mnt/boot/zfs
# zpool export zpool0
Проверяем, что в /mnt/boot/loader.conf, есть нужные строки для активизации zfs:
# cat /mnt/boot/loader.conf | grep zfs
Если строка zfs_load="YES" есть, то всё хорошо, нет добавляем - это модуль ядра для работы с zfs:
# echo 'zfs_load="YES"' >> /mnt/boot/loader.conf
Так же надо указать, что должна быть активирована при загрузке в /etc/rc.conf:
# echo 'zfs_enable="YES"' >> /mnt/etc/rc.conf
Внести записи в /mnt/etc/fstab о разделах подкачки swap:
# echo "/dev/ada0p3.eli none swap sw 0 0" >> /mnt/etc/fstab
# echo "/dev/ada1p3.eli none swap sw 0 0" >> /mnt/etc/fstab
# echo "/dev/ada1p3.eli none swap sw 0 0" >> /mnt/etc/fstab
Так же можно смонтировать области efi загрузки каждого диска:
# echo "/dev/ada0p1 /boot/efi0 msdosfs rw 0 0" >> /mnt/etc/fstab
# echo "/dev/ada1p1 /boot/efi1 msdosfs rw 0 0" >> /mnt/etc/fstab
# echo "/dev/ada2p1 /boot/efi2 msdosfs rw 0 0" >> /mnt/etc/fstab
В общем случае это монтирование не обязательно. Это, если хочется поработать с разными загрузчиками. Не забывайте про правильное именование файлов - они должны быть правильными.
В системе есть утилита, которая может изменить список загрузки в UEFI efibootmgr. Запуск без параметров выдаёт список существующих записей.
Добавить запись можно так:
# efibootmgr -a -c -l /boot/efi0/efi/boot/bootx64.efi -L FreeBSD
В общем всё. Перезагрузка:
# reboot
В качестве заключения.
ZFS очень интересная файловая система и замечательным набором свойств, возможностей и инструментов для работы, встроенных и автоматических средств защиты и восстановления. Гиганский запас по "прочности" и запросам на будущее.
Наверное многие сталкивались с тем, что "диск закончился и надо переносить систему на другой больший диск" - операция хоть и не сложная, но требует значительных усилий.
В случае же организации дисковой подсистемы на zfs всего лишь и надо будет:
1. подключить диск.
2. выяснить его имя в системе, если применяется gpt, то создать соотв. разделы, задать лейбл.
3. В зависимости от применённого типа пула, а в простейшем случае с одиночным диском /dev/ada0 при создании пула если создаётся пул типа sprite и добавленным /dev/ada1:
# zpool add zpool0 /dev/ada1
Подключится к пулу новый диск и пройдёт операция синхронизации - в фоне и незаметно для пользователя. (но тем не менее старайтесь не выполнять в этот момент ничего сурово ресурсоёмкого). Подключаемый диск может быть любого размера и/или их может быть несколько, в принципе сколько поддерживает материнская плата и дополнительные контроллеры, что в принципе можно воткнуть в слоты плат расширений. И вы получаете много свободного места в дисковой системе: на размер подключённого диска, чем было - OS при этом вообще никак не заметит изменений, кроме, естественно, увеличившегося свобобного дискового пространства - обо всём автоматически позаботятся внутренние механизмы zfs. Но... как обычно в этой цисцерне мёда есть и ложка дёгтя. В пуле типа stripe при выходе одного физического диска из строя весь пул умрёт и второе... добавить диск можно, а вот убрать - нет. Но Тут резервное копирование, хотя бы важных данных - наше всё. Это не лишне и при отказоустойчивых типах массивов mirror, raidz. Резервирование и копирование важной информации вообще хороший навык - тем более многое можно делать вообще бесплатно - yandex, google - предоставляют бесплатно объёмы, которые вполне могут хранить настройки ОS и важные данные.
И в заключение всё-таки, хочется сказать, словами коммивояжера: "и это ещё не всё!.. Вместе с этим вы получаете замечательные...". Но... наверное хватит, а, то говорить можно долго ещё.
Спасибо за внимание.
Пишите комменты и если, что не понятно или найдёте ошибки - буду рад ответить на вопросы.