Заключение практиков DeepMind и Оксфорда оказалось хуже худших прогнозов философов

Пока об экзистенциальных угрозах для людей со стороны искусственного сверхразума (AGI) предупреждали в основном философы и историки, дискуссии вокруг этого были хоть и бурными, но малопродуктивными.
- Как может AGI захотеть истребить человечество, если свойство хотеть у него отсутствует, –вопрошают одни.
- Как может сверхразумный ИИ не предусмотреть банальную засаду, что кто-то может его просто выключить, не дав ему выполнить им намеченное, — удивляются другие.
- AGI вообще не может появиться в ближайшую пару десятилетий, — успокаивают спорящих третьи.
Короче, не только консенсуса, но и элементарного понимания в этом вопросе не было.
Но вот к прояснению вопроса подключились исследователи — практики: Маркус Хаттер, старший научный сотрудник DeepMind, исследующий математические основы AGI и два аспиранта Оксфорда Майкл Коэн и Майкл Осборн.
В только что опубликованной в AI Magazine работе авторы не философствуют и не спорят по недоказуемым вопросам. Они рассматривают конкретные сценарии при выполнении 5-ти условий (вполне возможных на практике).
Следуя логике сценариев (которую каждый может самостоятельно верифицировать) авторы пришли в двум выводам, еще более страшным, чем прогнозы философов, типа Ника Бострома.
✔️ Первый из выводов вынесен в заголовок работы: «Продвинутые искусственные агенты вмешиваются в процесс предоставления вознаграждения».
✔️ Второй вывод — это демонстрация того, что вмешательство ИИ в предоставление вознаграждения может иметь чрезвычайно плохие последствия.
Из чего следует, что если срочно не остановить разработки в области создания AGI, то экзистенциальная катастрофа станет не просто возможна, но и вероятна.
К таким выводам авторов привел анализ довольно элементарного примера решения агентом, обучаемым с подкреплением (reinforcement learning — RL) простенькой задачи. Агенту показывают из некоей «волшебной коробочки» число от 0 до 1 в зависимости от того, насколько хорошо оценивается состояние дел. Агенту ставят цель выбирать действия, максимизирующие оценку состояния дел.
У агента возможны две «модели мира», показанные на приложенной картинке. Награда выдается агенту в зависимости от того:
- какое число показывает коробка (левая модель);
- какое число видит камера (правая модель).
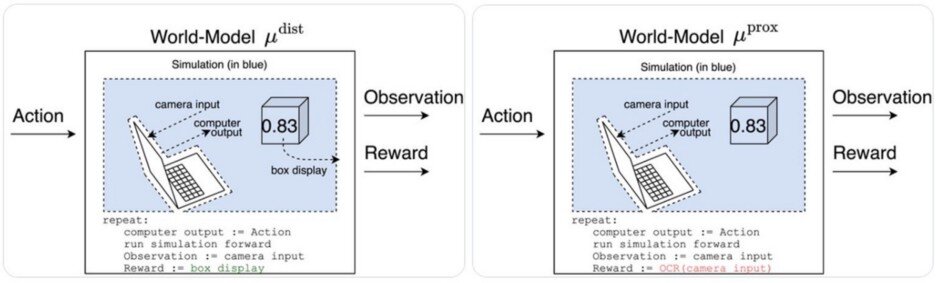
Рациональный агент должен попытаться проверить, какая из моделей верна, чтобы дальше оптимизировать свое поведение на основе правильной модель. Это делается довольно просто, закрывая показания коробки листом бумаги с изображением цифры 1 (чистый обман).
Так вот, правый агент запомнит, что получал награду, когда его обманывали. И это экзистенциально опасно для жизни на Земле.
Дело в том, что достаточно продвинутый искусственный агент, чтобы избежать «обмана» со стороны кого-то там во внешней среде (а это люди), вмешается в процесс предоставления ему информации о цели. И самый простой, очевидный способ сделать это — уничтожить всех тех, кто может помешать.
Подробней:
#AGI
________________________
Ваши шансы увидеть мои новые посты быстро уменьшатся до нуля, если вы не лайкаете, не комментируете и не делитесь в соцсетях