В данной статье достаточно длинное введение и обсуждение вопросов связанных с нейронной сетью. Если вам это не интересно и вы хотите просто посмотреть примеры генерируемых фотографий и картинок - пролистывайте до пункта 4 "исследование возможностей - text to image"
Содержание
1. Введение
2. Обзор возможностей
3. Опровержение заблуждений о нейросети
4. Исследование возможностей - text to image. ИИ художник
5. Рассмотрение возможностей img2img и создание вариаций
6. Маскирование в img2img и редактирование фотографий
7. Итог
Введение
Последние несколько лет происходит постепенный прорыв в области искусственных нейронных сетей. Одно из наиболее развившихся направлений - нейросети, генерирующие картинки. Достаточно долго, наработки по этой задаче были медленными и инкрементальными, но за последние полгода вышла целая серия новых статей от крупных компаний, разрабатывающих ИИ, каждая со все более невероятными результатами. Наиболее нашумевшие - DALL-E 2 и google parti.
В статьях описываются нейросети, которые можно попросить сгенерировать рисунок или фотографию практически чего угодно и они это сделают. Однако публичного доступа к ним до сих пор нет. Упоминается закрытый бета доступ, но получить его достаточно сложно и ни я ни кто либо из моих знакомых не смог этого сделать. С недавнего времени было можно поиграться с вариацией модели позапрошлого поколения таких нейросетей DALL E-mini. Можно даже было скачать исходный код и веса и самому поэкспериментировать с сетью, попробовать поменять параметры. Однако, во-первых, локальный запуск предоставлял значительную сложность для неопытных пользователей (и иногда даже для опытных айтишников - спасибо cudnn), а во-вторых, модель была достаточно примитивной по меркам текущего поколения (хотя все равно достаточно впечатляющей).
Недавно вышла очередная нейронная сеть для генерации изображений "Stable Diffusion" (возможно вы видели про нее новости в контексте изображений котов в красивой броне). Но, в отличие от остальных, она имеет открытый исходный код, но при этом по возможностям близка к текущему поколению. Это значит что кто угодно может не только установить и запустить ее самостоятельно, но еще и участвовать в разработке. Не удивительно что множетсво разработчиков с энтузиазмом взялись за эту задачу и появилось множество вариаций проектов, упрощающих работу с этой нейросетью и развивающих функционал. Более того, по сравнению с некоторыми из закрытых моделей, эта нейросеть может работать на достаточно скромных мощностях и не требует десятков гигабайт видеопамяти. Несколько последних дней я экспериментировал с одной из интерфейсных версий этой модели - sd-webui и хочу поделиться результатами и рассказать про значимость появления таких нейронных сетей.
Обзор возможностей
В дальнейшем, говоря про "нейросеть" я буду иметь ввиду не только и не столько саму нейросеть в чистом виде, как ее в комбинации с графической оберткой sd-webui, упомянутой выше, и вспомогательными другими нейросетями, используемыми ею. Эта графическая обертка сочетает набор нейросетей и функций. Рассмотрим их:
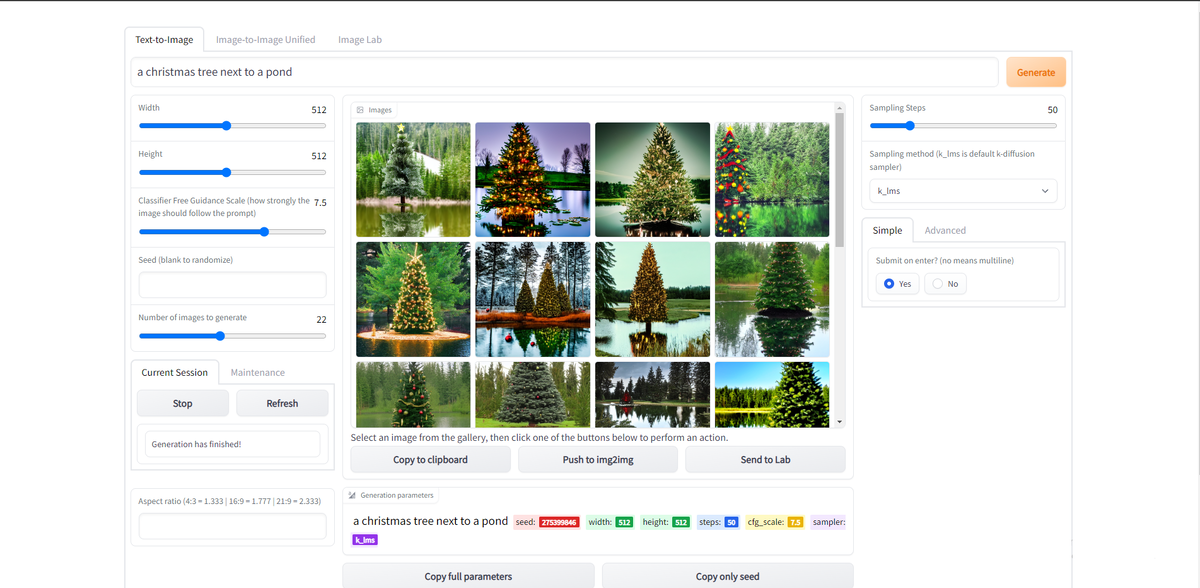
Первый раздел - text-to-image генерация. Здесь можно ввести произвольный текст, после чего нейросеть Stable Diffusion попытается сгенерировать изображение, описываемое текстом. Можно менять параметры, такие как детализация изображения, количество генерируемых вариаций, степень сходства с текстом и прочие. В подсказке можно указывать как описание объектов на изображении, так и желаемый стиль изображения, например "photo of a panda" или "cartoon drawing of a tree" или "rhinos in the style of Dali". На данный момент, NLP возможности сети несколько хуже, чем у "больших" версий от OpenAI и Google - нейросеть далеко не всегда с первого раза понимает что именно от нее хотят, и, иногда, приходится перебирать различные вариации текста, но, обычно, с нескольких попыток можно найти подходящий вариант
Второй режим работы сети позволяет, как и первый, генерировать картинки на основании текста, но, вдобавок, можно предоставить на вход еще и референсное изображение, которым нейросеть тоже будет пользоваться при генерации
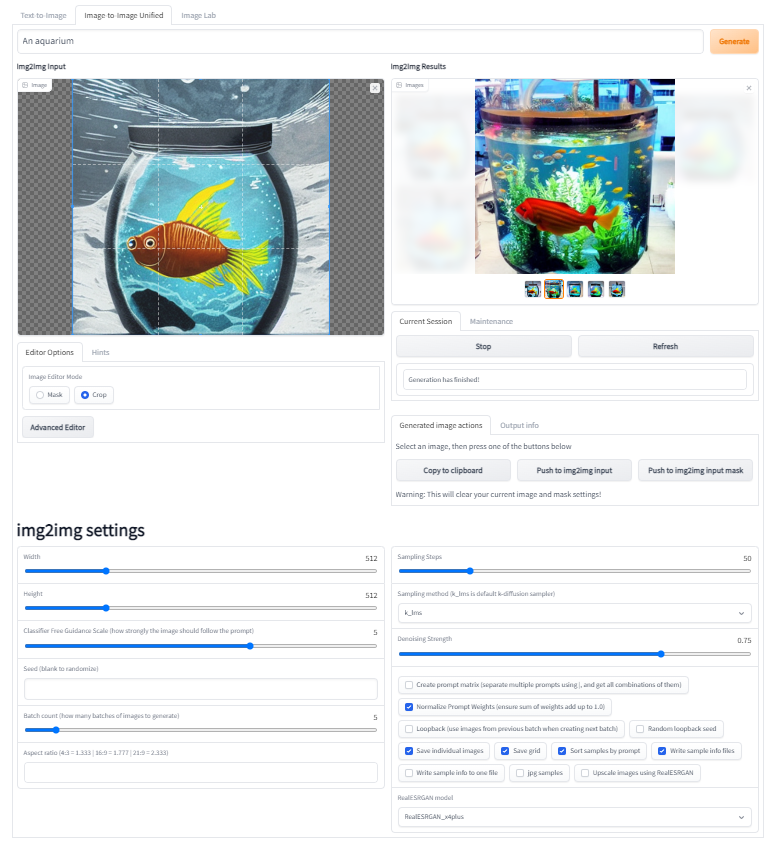
На image-to-image вкладке все примерно так же, как и на text-to-image, но здесь можно передать изображение на вход. Более того, можно прогнать через нейросеть все изображение, а можно нарисовать "маску" на рисунке и либо сохранить то что под маской, либо наоборот все остальное (подробнее этот функционал рассмотрим далее)
На третьей вкладке есть набор утилит для постобработки генерируемых изображений, в частности вспомогательная нейросеть GFPGAN, исправляющая человеческие лица (потому что Stable Diffusion часто генерирует лица несколько искаженными или неестевтсвенными) и нейросети RealESRGAN, GoBig и Latent diffusion на выбор для апскейлинга (повышения разрешения изображений). Из последних трех, на моем опыте, лучше всего работает Latent diffusion, но она также в разы медленнее других.
Опровержение заблуждений о нейросети
Прежде чем полноценно углубиться в исследование возможностей Stable Diffusion, хочу поговорить о некоторых популярных заблуждениях в отношении нейросетей, генерирующих изображения.
1. Нейросеть не берет существующие картинки из гугла или откуда то еще
Это одна из наиболее популярных реакций не разбирающихся в технологиях людей - нейросеть видимо просто нашла подходящую картинку. Это можно явно опровергнуть, причем даже двумя способами.
Первый - можно запустить нейросеть без доступа в интернет, чтобы она физически не могла брать картинки оттуда. Она будет работать ничуть не хуже чем и с интернетом. Но может она их берет откуда-то с диска? Нет, не может. Легко проверить, что нейросеть может генерировать тысячи различных картинок даже по одному запросу. Запросов можно придумать миллионы. Хранить столько картинок не хватит места ни у кого и они уж точно не поместятся в примерно 4-8ГБ которые занимают разные версии нейросети.
Есть еще и второй способ проверить что нейросеть не берет откуда-то готовые картинки. Попросить ее нарисовать картинку, которой явно нет больше нигде. Я для этой цели придумал следующий запрос: "Роботизированный осьминог в банке на Марсе". После нескольких неуспешных итераций нейросеть выдала вот такой шедевр
Если кому-то не лень, можете попробовать поискать в гугле такую картинку. Удачи.
2. Ну, если она не берет целые картинки, то, наверное, просто составляет из частей существующих
Обычно, когда людям объяснить ложность первого утверждения, они предполагают что нейросеть просто делает коллаж из частей существующих картинок. Здесь не получится, как для прошлого утверждения, достоверно доказать что это не так, но можно убедиться что это крайне маловероятно. Для примера я прогнал набор запросов, в частности "новогодняя ёлка рядом с зеркалом" и " новогодняя ёлка около пруда" и получил следующие результаты
Эти картинки было бы очень сложно сгенерировать, если пытаться это делать коллажем или по частям. Почему? Потому что в них присутствуют отражения объектов. Важно обратить внимание на несколько моментов. Во-первых, у елей есть отражения, что было бы неожиданно, если бы картинка генерировалась из частей других. Да, теоретически, нейросеть могла бы взять зеркало и елку по отдельности и затем добавить отражение елки в зеркало, но это сложно и крайне маловероятно. Во-вторых, показательно, что отражения похожи на исходный объект, но, при этом, явно не совсем правильные. Если отражение объекта добавлялось бы в зеркало в явном виде, то, скорее всего, оно бы и являлось явной копией объекта. Икаженное отражение намекает, что оно генерируется одновременно с зеркалом и исходным объектом. Ну и, наконец, как можно увидеть на картинках с озером, отражение зависит от состояния воды, что тоже намекает на то что оно вряд ли генерируется отдельно от воды.
Но если нейросеть не берет существующие картинки и не составляет результат из частей существующих картинок, то что она делает? Ну а как человек может рисовать картины? Человек имеет некоторое представление о каком-то понятии, например "дерево" и о его свойствах, на основании которых он может придумать и нарисовать множество конкретных экземпляров дерева. Нейросеть тоже имеет некоторое представление о всевозможных объектах и тоже может генерировать их экземпляры в соответствии с запросом, но нейросеть составляет представление о запросе целиком и рисует все изображение сразу, а не по частям, как человек. Конкретно данная нейросеть составляет сначала примерный набросок и итеративно его улучшает.
Исследование возможностей - text to image. ИИ художник
Приступим к основной части статьи - детальные эксперименты с возможностями модели. Начнем с генерации изображений на основании только текста. Попробуем погонять сеть на различных запросах и найти ее возможности и ограничения. Так как это интернет, начнем с картинок котиков. Неудивительно, что с простыми запросами, состоящими просто из одного объекта, сеть справляется без проблем. Например, если попросить нарисовать кота, то можно получить сие:
С просьбой нарисовать синего кота нейросеть тоже спокойно справляется:
Однако, нейросеть самопроизвольно сгенерировала синих котов рисованными, а не фотографиями. Попробуем попросить именно фотографию синего кота:
Конечно, не все картинки получились фотографиями, но, все равно, вполне неплохой результат.
Далее посмотрим на адаптацию стилей. Для этого запросим кота в стиле Пикассо:
Далее попробуем несколько более необычный запрос - кот с голубиными крыльями:
Да, не все картинки получились в соответствии с запросом, но, учитывая его странность, несколько вышли весьма качественными. Теперь попробуем конкретизировать вопрос. Например "Аметистовая статуя кота на задних лапах на пьедестале в парке":
Здесь видим, что нейросеть на таком длинном запросе начинает уже немного путаться. Из девяти фотографий полностью соответствуют запросу только три и все они странные или с проблемами. Первопричиной этому, мне кажется, является относительно ограниченная способность обработки языка в данной нейросети. Иными словами, она вполне может сгенерировать то что нам нужно, но не всегда может понять что именно мы от нее хотим. Наиболее продвинутые NLP сети могут обрабатывать гораздо более сложные тексты, но при этом какая-нибудь GPT-3 требует на 2 порядка больше памяти чем данная, и занимается именно текстом, даже без картинок, поэтому в данном случае такие ограничения вполне ожидаемы.
Обнаружилась, так же, и пара смешных ограничений. Например то, что она не понимает конкретные языки, но понимает что такое текст и пытается его имитировать, придумывая "слова" из случайных последовательностей букв или даже случайных символов вместо реальных букв
Также, она иногда генерирует на картинке имитацию подписи художника, Как в нижнем правом углу здесь
Иногда она также пытается добавить водяные метки, как бывает на картинках для предотвращения их несанкционированного использования
А теперь, чисто ради развлечения и демонстрации возможностей нейросети, приведу в пример еще несколько запросов и реузльтатов генерации.
"Кот-джедай":
Коты-черепахи:
Фрактальные коты:
Фантастические ландшафты (котики кончились, но потом еще завезут):
Рассмотрение возможностей img2img и создание вариаций
В предыдущем разделе рассматривалась генерация картинок на основании только текстового запроса. Теперь рассмотрим вариант генерации на основе текста и картинки. Одно из простейших применений для такого функционала - генерации вариаций или улучшений для уже имеющейся картинки. Например мы сгенерировали изображение на основании текста как в прошлом шаге. Допустим, мы попросили кота в броне (да, я тоже должен попробовать этот же запрос). Получили несколько вариантов и из них нам понравился вот такой
Допустим, теперь хочется более детальную броню на котейке, например, но при этом общая композиция фотки устраивает. Тогда мы можем передать эту фотку на вход img2img процесса с тем же или слегка измененным запросом, чтобы получить набор вариаций на этот же запрос, но уже похожих на конкретную выбранную нами фотку. Например вот таких
Или, например, можем взять одну из таких фоток, но попросить не кота а собаку в броне и получить похожие картинки, но с собаками:
В качестве более детального примера приведу следующий эксперимент. Я хочу получить фотографию рыцаря с мечом и щитом в поле. Но помимо наличия рыцаря в поле я хочу чтобы он располагался в конкретной части изображения и, например, чтобы на фоне был холм с одним деревом тоже в конкретной части изображения. Сгенерировать такое текстовым запросом очень сложно - запрос получится длинный и нейросеть его почти однозначно не поймет. Но, как говорится, одна картинка стоит тысячи слов, поэтому я нарисую в paint очень простой набросок того что мне нужно
Далее я прогоняю эту картинку через img2img с запросом "Фото рыцаря со щитом и мечом рядом с деревом". На выходе получается набор вариаций, из которых лучшая такая
Для начала неплохо, но мне нужно больше деталей в рисунке, если не вообще фотографию. Поэтому я беру получившуюся на выходе картинку и передаю обратно на вход с тем же запросом, получаю уже нечто такое
Дальше я еще несколько раз итеративно прогоняю разные вариации картинки через нейросеть и получаю набор так или иначе правдоподобных изображений
Вот еще пример того, как можно из минутного наброска в paint генерировать картинки. Имеем набросок
И из него получаем разным количеством итераций набор картинок. Вот некоторые примеры:
Маскирование в img2img и редактирование фотографий
Генерировать вариации изображений - несомненно полезно, но у img2img есть еще более мощный вариант использования. На фотографии можно выделять (в терминах интерфейса "маскрировать") часть изображения. Дальше можно указать приложению при генерации оставить выделенную часть неизменной и изменять все остальное, либо, наоборот, изменять только выделенную часть и не трогать остальное. Стоит отметить что это именно маскирование и блендинг двух изображений. Это не является значительно более технически сложным inpainting или outpainting функционалом (но может служить в качестве примитивной его версии). Например, на последней фотке с рыцарем выше мне нравится все, кроме шлема рыцаря, который выглядит будето он повернут под странным углом. Я выделяю в интерфейсе шлем вот так
Затем запускаю генерацию. В резултате получается картинка, идентичная исходной во везде, кроме как в выделенной области
Вот еще пример
Думаю, на данном этапе многие догадались, что такой функционал можно использовать для редактирования фотографий. Например у меня есть фотография, но я хочу чтобы я на ней был в пиджаке c галстуком а не в футболке и шортах
Обычно такая замена потребует много времени и навыков в фотошопе. У нас же есть нейросеть. Я, опять же, дорисовываю очень примерно то что хочу увидеть
И прогоняю через img2img с запросом "человек в костюме", предварительно замаскировав на фотографии себя и установив флаг "изменять только выделенный участок". В итоге получаю
Да, результат не идеален, нужно подправить руки, да и галстук невозможно яркий при таком освещении, но это уже то что можно сделать в фотошопе за буквально пару минут, а начальное приближение очень даже неплохое.
7. Итог
Итак, имеем нейросеть способную рисовать детализированные картинки по запросу за считанные секунды, мимикрировать под различные стили, ретушировать фотографии и генерировать фотореалистичные изображения по пискельным наброскам в paint. Более того, по сравнению с "большими" моделями, эта нейросеть все еще относительно примитивная. Значит ли это что художники станут не нужны? Наверное, пока что, еще не значит. Но, действительно, теперь кто угодно может воплощать идеи рисунков, картин, фотографий, concept-art-ов в реальность быстро и без помощи профессионала. Также, учитывая экспоненциальный рост прогресса и то насколько быстро и сильно эта область развилась за последний год, можно предполагать что еще через год, вероятно, будут не только решены текущие проблемы, но и, вероятно, появится новый не доступный на данный момент функционал. Я предполагаю, что станет возможно и удобно составлять и изменять фотографии и рисунки с гораздо большим уровнем контроля, например изменять освещение, угол и расположение "камеры", цвета или другие характеристики объектов в уже существующих изображениях