Углубившись в изучение ICMP, ping и traceroute, для написании этой статьи, я понял, что качественный фундамент, состоящий из знаний о функционировании компьютерных сетей, оказывает неоценимую помощь в моей работе. Если вы пользуетесь ping или traceroute, и хотите узнать немного больше о том, как они работают - эта статья для вас.
Я не буду описывать все нюансы, а затрону лишь несколько ключевых тем, знание которых, помогало мне лучше понимать проблематику и устранять неполадки в обслуживаемых мною сетях на протяжении многих лет.
ICMP и Ping
ICMP (англ. Internet Control Message Protocol — межсетевой протокол контролируемых сообщений)
Большая часть трафика в сети интернет инкапсулирована по правилам либо TCP, либо UDP протоколов. Однако, команда ping работает согласно протокола ICMP. ICMP — диагностический протокол, описывающий некоторое количество различных по типу сообщений, связанных с определенными специфическими событиями в сети, будь то ping request ( также называемый Echo Request ) или ping reply( называемый еще Echo Reply), или какое-либо другое диагностическое событие.
Тип любого сообщения, описанного ICMP, складывается из значений двух полей: Type , содержащее название типа сообщения; и поле Code , содержащие дополнительную информацию о событии. Полный список значений этих полей можно посмотреть здесь.
Вы, несомненно, столкнетесь с этими сообщениями во время использования ping. Если, например, я буду делать ping для устройства, IP-адрес которого отсутствует в таблицах моего маршрутизатора, то в ответ от него мы получим сообщение Destination host unreachable (ответ от 10.250.1.1 ниже).
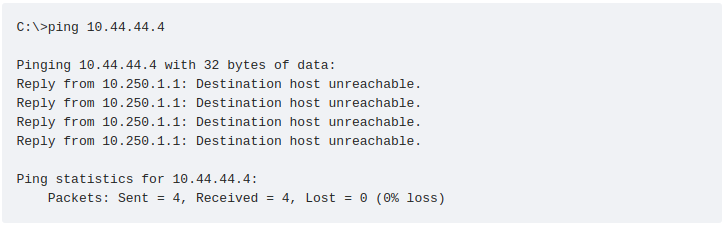
Если мы проверим теперь таблицу Контрольных Сообщений ICMP, например с помощью захвата программой Wireshark пакета с ответом маршрутизатора, мы увидим, что полям Type и Code сообщения Destination host unreachable соответствуют значения 3 и 1 .
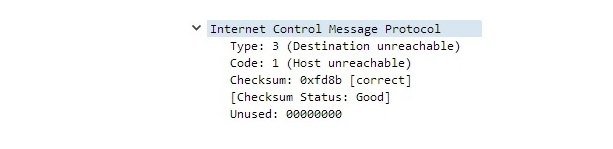
Вот, что происходит за кулисами: мой компьютер послал контрольное сообщение (так называемый Echo Request) на IP-адрес 10.44.44.4 со следующими значениями полей Type 8, Code 0 . Это сообщение достигло маршрутизатора, который является шлюзом по умолчанию в нашей сети, он проверил наличие указанного выше IP-адреса в своих таблицах маршрутизации, и, не найдя его, вернул ответ Destination host unreachable
Есть один нюанс, про который стоит упомянуть, если вы пробуете делать это дома — все вышесказанное, в первую очередь, применимо к корпоративным или бизнес сетям. Большинство обычных домашних маршрутизаторов настроено таким образом, чтобы пересылать весь трафик, для которого у них нет маршрута, дальше в сеть интернет, даже если адрес назначения пакета находится в частном адресном пространстве ( RFC1918 ). В этом случае ваш провайдер интернета ( ISP ) просто отбросит такие пакеты и вы получите ответ: Request timed out
Request timed out не соответствует ни одному типу контрольных сообщений, поскольку не является полноценным ICMP сообщением — это просто свидетельство отсутствия каких-либо возвращаемых данных.
Так почему же все это так важно для нас ?
Важно знать, что означают ICMP сообщения
Ответное ICMP-сообщение может предоставить нам необходимую информацию о том, что на самом деле происходит в сети. Destination host unreachable и Request timed out это две абсолютно разные ситуации. В первом случае полученное сообщение говорит нам от том, что пакет не может уйти по адресу, так как система не знает маршрута до адресата, во втором — пакет уходит по адресу, но адресат нам не отвечает.
Становится все интереснее, давайте погрузимся еще глубже..
Ping в локальной сети
Что будет, если вы сделаете ping несуществующего адреса в вашей локальной сети? Каков будет ответ сети : Request timed out, Destination host unreachable, или еще какой-нибудь? Что происходит, когда узел сети существует, но ICMP блокируется межсетевым экраном. Можете ли вы объяснить разницу между несуществующим сетевым узлом и узлом, который просто отклоняет служебные запросы ICMP ?
Размышляя над этими вопросами, давайте сделаем ping устройства, настроенного таким образом, чтобы отвергать все запросы ICMP Echo Requests и посмотрим, что из этого выйдет:
А теперь давайте рассмотрим это через призму Wireshark:
Мы отослали 4 запроса ICMP Echo и получили в ответ Request timed out, собственно, что и ожидалось увидеть, в случае, когда межсетевой экран исследуемого узла, расположенного в локальной сети, настроен на блокирование ICMP запросов.
Однако, что если исследуемый узел находился бы вне локальной сети? Получили бы мы похожий результат? В этом примере я убрал исследуемый узел за пределы локальной сети:
A теперь посмотрим в Wireshark.
Да, ваши глаза вас не обманывают, похоже, что мы не отослали ни одного запроса ICMP Echo .
То, что произошло — связано с тем, как пакеты коммутируются внутри сегмента сети. Когда вы делаете ping удаленного узла ( вне локальной сети ), поле адреса второго уровня ( TCP/IP), передаваемого пакета, содержит MAC-адрес шлюза-маршрутизатора вашей сети. Однако, когда передача трафика происходит внутри локальной сети взаимодействие с маршрутизатором не требуется, а поле адреса второго уровня содержит MAC-адрес узла назначения. А как же наш компьютер узнает, каков MAC-адрес узла назначения? Он посылает широковещательный ARP запрос и ожидает ответа, содержащего MAC-адрес, а поскольку в сети нет устройства, которое бы ответило на ARP запрос, то и кадр ICMP Echo не может быть создан и отправлен.
Вот, что произойдет, если я настрою Wireshark на отображение ARP-трафика:
Мы рассылаем широковещательные ARP-запросы, но нет устройств, которые бы могли на них ответить. Давайте посмотрим на весь трафик ( ARP и ICMP) из предыдущего примера, где в локальной сети присутствует «живой» узел, отвергающий ICMP трафик.
Мы отправляем такой же ARP-запрос, и в ответ получаем MAC-адрес узла, который наш компьютер помещает в адресное поле ( второго уровня TCP/IP ) кадра запроса ICMP Echo, и, после этого, отправляет кадр адресату.
По сути, все это означает, что нам на самом деле не нужен ICMP для обнаружения узлов внутри локальной сети, если у нас есть запись ARP Cache, соответствующая искомому IP -адресу.
Несмотря на то, что мы не получили ответ на наш ping, мы все равно можем утверждать, что узел присутствует в сети, так как в ARP-таблице есть соответствующая ему запись. Или можно еще сказать, что адресат существует, так как мы можем посылать ему запросы ICMP Echo .
Подводя итог, можно вывести правило, что сообщение Destination host unreachable , полученное в локальной сети, будет означать, что искомый узел отсутствует, в то время как сообщение Request timed out будет означать, что узел присутствует в сети, но что-то блокирует ICMP.
Но, как говориться, для любого правила существуют исключения: ваш компьютер может иметь устаревшую кэшированную запись в своей ARP-таблице, используемой для генерации пакетов. В ОС Windows вы можете очистить ARP кэш с помощью команды arp -d . В этой операционной системе есть несколько интересных правил, руководствуясь которыми она обслуживает и чистит локальный кэш ARP.
Для демонстрации работы этих правил я снова включил в локальную сеть узел 10.250.1.5, и отключил правило межсетевого экрана, блокировавшее ICMP. После нескольких успешных попыток сделать ping этого узла, я снова удалил этот узел сети:
После удаления узла сети, MAC-адрес еще какое-то время остается в кэше нашего компьютера, поэтому мы получаем сообщения Request timed out в ответ на попытки сделать ping, через какое-то время ОС Windows очищает ARP-кэш, а новые широковещательные ARP-запросы больше не возвращают адрес удаленного узла, и мы не можем продолжать делать ping-запросы, поэтому сообщение Destination host unreachable не заставляет себя ждать.
telnet: Обнаружение закрытых портов
В некоторых случаях, когда межсетевой экран адресата настроен таким образом, что бы блокировать входящие подключения, мы получаем ICMP-сообщение , из которого можно сделать вывод, что сетевое подключение запрещено администратором ( Administratively Prohibited ) Очень простой способ проверить службу TCP — попытаться установить telnet подключение к целевому порту.
В примере, приведенном ниже, я попытаюсь подключиться с помощью telnet к 80 порту на своем маршрутизаторе, хотя точно знаю, что порт заблокирован:
Oк, telnet сам по себе нам ничего не дал, а как на счет Wireshark?
Бинго! Мы видим ответ маршрутизатора: Communication administratively filtered. Становится ясно, что отправленный нами пакет проделал весь путь до маршрутизатора ( так, что можно уверенно говорить, что он не был блокирован каким-либо другим сетевым устройством, или программным обеспечением для управления сетью) и устройство само говорит нам, что целевой порт не доступен для использования.
Мы можем снова посмотреть тип и код ICMP-сообщения с помощью Wireshark:
Самое удобное в таком подходе, то, что мы можем точно узнать какое устройство блокирует соединение. Теперь я настроил свой межсетевой экран таким образом, чтобы блокировался весь трафик на 80 порт любого адресата. Давайте посмотрим, что произойдет, когда я попытаюсь подключиться с помощью telnet на 80 порт google.com
Мы можем видеть, как мой ПК (10.250.1.100) посылает инициализирующий пакет TCP SYN на IP-адресc 216.58.203.110, ассоциированный с google.com, однако, ответное сообщение ICMP приходит с IP-адреса локального межсетевого экрана- 10.250.1.1, сообщая нам, что подключение к целевому ресурсу отклонено. Этот процесс повторяется несколько раз, поскольку мой компьютер упорно пытается подключиться к google.com, но результат остается неизменным.
Это очень упрощенный пример, однако в крупных корпоративных сетях такой подход может быть весьма полезен, так как они имеют сложную топологию, и поиск блокирующих сетевые подключения систем, может быть затруднен.
Здесь нужно заметить, что многие межсетевые экраны часто возвращают фиктивный TCP RST пакет, вместо ICMP сообщения Communication administratively filtered . Это в первую очередь относится к системам веб-фильтрации или IPS, подключенным через SPAN/mirror порт.
Значение времени ожидания
Очень часто, программа ping используется не только для определения доступности узла, но также для исследования причин различного рода задержек(latency) происходящих на пути следования пакетов. И хотя высокие показатели задержки, как правило, говорят о проблемах в сети - это не всегда так. Давайте рассмотрим такой случай: большинство современных корпоративных маршрутизаторов и коммутаторов осуществляют пересылку пакетов с помощью ASIC, специальных интегральных схем, призванных ускорить процессы маршрутизации и коммутации пакетов внутри устройства, что у них хорошо получается. Подавляющее большинство пакетов, проходящих через такой маршрутизатор, обрабатывается ASIC. Пакеты, не требующие дальнейшей маршрутизации, а предназначенные непосредственно для подобного маршрутизатора , обрабатываются его центральным процессором и не проходят через ASIC. Как правило, помимо обработки пакетов предназначенных для маршрутизатора, его центральный процессор выполняет массу рутинных задач ( обновление таблицы маршрутизации, фрагментация пакетов и тд. ), поэтому возможен такой сценарий, по которому у маршрутизирующего устройства может возникнуть нехватка ресурсов собственного центрального процессора, но при этом он продолжит выполнять маршрутизацию проходящих через него пакетов с обычной скоростью, за счет использования специализированной интегральной схемы ASIC.
Такую ситуацию можно выявить, когда высокие показатели задержки, проявляющиеся на промежуточном устройстве, оказываются вполне приемлемыми для конечного узла.
И даже, если ЦП устройства не испытывает повышенные нагрузки, на нем все равно могут возникать задержки отклика на ping-запросы, связанные с текущими настройками политики QoS. Эти политики используются для ограничения влияния процесса обработки некритического трафика, вроде ICMP-пакетов, на критически важные службы системы, такие как обновление таблицы маршрутизации или управление доступом, или каких-либо других. В некоторых случаях ICMP-пакеты вовсе отбрасываются, если был достигнут лимит, определенный действующей на устройстве политикой QoS, тогда это будет выглядеть, как будто они потерялись, однако, на пакеты, следующие через устройство транзитом, действия подобных политик обычно не распространяются. Поэтому не всегда можно быть уверенным в том, что если устройство, находящееся на пути следования пакетов, не отвечает на ping-запросы или отвечает с перебоями, является причиной плохой проходимости пакетов по сети в целом.
Круговая задержка и асимметричная маршрутизация
Что же мы на самом деле подразумевается под цифрами значений задержек в выводе программы ping ? Это время, которое потребуется, для формирования и отправки ping-запроса с вашего устройства, приема этого запроса адресатом, его обработки, формирования и отсылки ответа, приема и обработки ответа вашим устройством.
Интернет устроен весьма сложно. И соглашения о пиринге между провайдерами интернета во многом определяют тот маршрут, который пакет с данными проходит через сеть Интернет до адресата. Нет никаких гарантий, того, что маршрут посланного вашим устройством пакета с запросом на удаленный узел совпадет с маршрутом ответного пакета от удаленного узла на ваше устройство.
Рассмотрим следующую диаграмму, изображающую сервер, размещенный в некоем ЦОД, подключенном к сети Интернет через сети двух разных провайдеров:
Вследствие договоренностей о пиринге, провайдер, обслуживающий ЦОД, предпочитает отправлять трафик по маршруту, обозначенному на диаграмме зеленым цветом. Но он не может повлиять на маршрут, который выберет ваш провайдер для отправки трафика на сервер, находящийся в ЦОД. В результате складывается ситуация, когда эхо-запрос ICMP на удаленный сервер будет отправлен по маршруту, обозначенному синим цветом, а эхо-ответ ICMP вернется к вам по маршруту, обозначенному зеленым цветом.
Что если в месте, обозначенном красной стрелкой на диаграмме, возникнет перегрузка или обрыв? В ответ на ваш ping-запрос вы увидите высокие показатели задержки, но задержка эта не будет иметь ничего общего ни с ЦОД ни с удаленным сервером.
Это, что касается ping. Но давайте теперь рассмотрим асимметричную маршрутизацию через призму traceroute.
Traceroute
«Повторение - мать учения» или как работает traceroute
Очень важно, чтобы мы, общаясь на тему traceroute, говорили на одном языке, так что давайте быстро пробежимся по ключевым моментам.
Итак, traceroute отправляет конечному пункту назначения серию ICMP-пакетов, с каждым шагом увеличивая значение поля TTL («время жизни») на 1, до тех пор, пока не будет получен ответ от целевой системы. TTL - это специальное поле в заголовке IP пакета, значение которого уменьшается на 1 ( единицу ) каждым устройством 3 уровня модели OSI, через которое проходит пакет на своем пути к адресату. Когда это значение становится равным 0 ( нулю ), пакет перестает пересылаться, генерируется сообщение об ошибке и возвращается отправителю внутри ICMP-пакета. Это означает, что поскольку traceroute с каждой новой серией пакетов увеличивает значение их TTL на 1 ( единицу ), то на каждом переходе (hop), на пути к адресату будут пакеты, значение поля TTL которых будет уменьшено до 0 ( нуля ), и следовательно, будут отправлены ответные ICMP-сообщения Time to live exceeded in transit , чей ICMP-тип и ICMP-код будут 11 и 0 соответственно.
Упорядоченный поток из этих ICMP-сообщений позволяет нам представить себе карту маршрута до удаленного узла. Вот пример traceroute от моего ПК до узла с IP-адресом 1.1.1.1
Давайте посмотрим как первая и вторая строки будут выглядеть в Wireshark:
Вот несколько замечаний:
- Во-первых пункт назначения для пакетов, отправленных с моего ПК (10.250.1.1) всегда 1.1.1.1.
- Мы отправляем 3 эхо-запроса ICMP до каждого промежуточного устройства, прежде чем увеличить значение TTL. Это хорошо видно по значениям поля задержки в выводе команды.
- По умолчанию, в ОС Windows traceroute использует ICMP-пакеты, в то время как в ОС Linux используется UDP протокол. (Хотя здесь этого не видно)
Итак мы освежили наши знания traceroute, теперь давайте вернемся к асимметричной маршрутизации.
Асимметричная маршрутизация с точки зрения traceroute
Одна из наиболее важных концепций, которую следует понимать глядя на данные, предоставленные traceroute, заключается в том, что вы видите только один маршрут — маршрут от исходного устройства, где выполняется команда traceroute, до целевого устройства. Каким маршрутом проследуют ответные пакеты от удаленного узла, мы узнать не сможем.
Давайте это продемонстрируем, проведя небольшую лабораторную работу. У меня есть следующая конфигурация GNS3
Конфигурация довольно проста, мы используем два маршрутизатора для эмуляции ПК и сервера . Пакеты от ПК к Серверу идут по нижнему пути через PC -> R1 -> R2 -> R3 -> Server, а пакеты от Сервера к ПК идут по верхнему пути через Server -> R3 -> R4 -> R5 -> R6 -> R1 -> PC.
Давайте с помощью traceroute посмотрим, как эта конфигурация работает, для начала на участке от ПК до Сервера. Формат вывода команды будет слегка отличаться от предыдущего, так как на этот раз мы используем Cisco IOS CLI, но нам не составит руда в нем разобраться. Показатели задержек в выводе traceroute сейчас для нас не имеют какого бы то ни было значения, так как сгенерированы ненастоящими сетевыми устройствами, по этому мы их проигнорируем.
Здесь мы видим именно тот маршрут, который был описан нами несколькими строками выше. А как на счет участка от Сервера до ПК?
Произошло как раз то, что мы и ожидали - маршруты абсолютно разные! Будучи использованной на одном конце интернет-соединения, traceroute не дает информации о маршруте, выбираемом пакетами, следующими с другого конца. Если бы диагностируемая нами проблема в сети возникала на пути следования пакетов от, скажем, Сервера, то использование traceroute со стороны ПК, мало бы нам помогло. Давайте представим, что произошел обрыв соединения между R5 и R6. Как бы выглядел вывод команды traceroute со стороны ПК
Несмотря на разрыв соединения на R5, в выводе traceroute мы этого заметить не можем, более того некоторые могут подумать, что на самом деле проблема возникла на R2 , так как мы не видим, что отправленные нами пакеты идут дальше. Вот, что здесь происходит : каждое устройство дальше R2 ( начиная с R3 ) выбирает для отправки ответных пакетов верхний маршрут, который не может обеспечить движение трафика из-за обрыва соединения.
Если теперь мы выполним traceroute на стороне Сервера, то увидим более объективную картину происходящего:
Символ !H в синтаксисе Cisco IOS означает Host Unreachable ( узел недоступен ), что в свою очередь означает, что R5 больше не имеет возможности передавать пакеты для нашего ПК ( 10.250.1.100 )
По этой причине, при диагностике неполадок сети для получения объективных данных очень важно иметь возможность получить вывод traceroute на всех конечных узлах соединения.
Давайте двигаться дальше, и рассмотрим любопытные побочные эффекты, наблюдаемые с помощью traceroute в сетях MPLS
Traceroute и MPLS
В случае обычной сетевой маршрутизации каждое устройство на пути следования пакета само решает по какому маршруту пересылать данные. Адрес узла назначения извлекается из IP-заголовка, производится поиск по таблице маршрутизации, и пакет пересылается дальше через интерфейс, который маршрутизатор посчитает наилучшим для достижения пакетом сети назначения.
В сетях MPLS (англ. multiprotocol label switching — многопротокольная коммутация по меткам) весь маршрут определяется самым первым маршрутизатором, а последующие маршрутизаторы бездумно придерживаются предложенного им плана.
Поэтому даже пакеты с диагностическими сообщениями, такие, например, как сообщения о завершении времени жизни (TTL) пакета, все равно продолжат свой путь по маршруту до конечного узла, прежде чем вернуться к отправителю.
А теперь представьте себе, что маршрутизаторы в подобных сетях могут быть географически удалены друг от друга на громадные расстояния. Поэтому выполняя traceroute для таких сетей ( или участков сетей ) мы столкнемся с очень высокими показателями задержки из-за того, что диагностическим сообщениям о завершении времени жизни пакета ( TTL Expired) приходится проделывать полный путь до конечного узла, прежде чем вернуться к отправителю.
Вот и все, надеюсь статья окажется вам полезна.
Автор: xkln.net