Периодически я обращаюсь к зарубежным курсам и учебной литературе по математике и программированию из большого интереса к манере подачи материала. Очень многие курсы по алгоритмам великолепно преподаются в иностранных ВУЗах и мне кажется можно многое почерпнуть оттуда и для наших учащихся. Красиво завернуть концепцию и показать суть материала это большой труд, а хорошие и интересные задачи, объясняющие принципы анализа сложности всегда приятно разбирать. В сегодняшнем материале я сделаю попытку дать вольный пересказ очень красивой вводной задачи из замечательного курса MIT 6.006 (введение в алгоритмы, горячо рекомендую всем, материалы конечно же на английском). Тема о которой сегодня хочется поговорить это так называемый поиска пика. Как скоро станет ясно, пик можно понимать почти в том самом естественном смысле:

Мы рассмотрим двумерную и одномерную задачи. Суть их идентична: в одномерном или двумерном массиве из целых чисел необходимо найти любой пик, где под пиком мы понимаем такое значение в массиве (заданное индексом или парой индексов), что это значение является локальным максимумом (не меньше своих соседей). В одномерной задаче соседями считаются соседи слева и справа, а в двумерной задаче - сверху, снизу, слева и справа (без диагоналей).
Для понимания на рисунке я выделил несколько пиков для двумерной задачи в массиве случайных целых чисел от -100 до 100 размера 10 на 10:
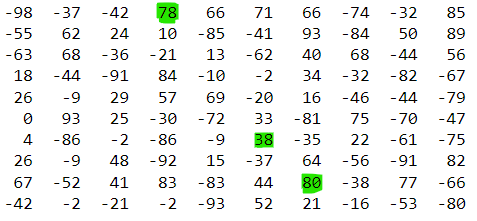
Заметим что максимумы нестрогие - то есть массив из одинаковых элементов мы считаем весь усеянным пиками (такая вот условность). Эта задача интересна тем, что ее легко объяснить новичку, и она позволяет прочувствовать разницу в сложности алгоритмов. Практический интерес у задачи тоже можно найти, особенно если мы занимаемся написанием какого-то движка для быстрого принятия решений исходя из статистических данных (можно считать что значения в массиве это некоторая стоимость позиции, и нам нужно быстро находить любой локально-оптимальный ход).
Начнем с одномерной задачи. Нам задан на вход массив из n целых чисел, и необходимо найти «локальный максимум», он же пик. Самая первая и банальная идея которая приходит на ум при решении такой задачи это сделать обычный линейный проход. Несложно понять что у этого подхода линейная временная сложность в худшем случае. Ниже представлен примерный вид решения и пара тестов, один из которых, как раз, пример худшего случая. Время указано в секундах.
Если нам не повезло со входными данными, то необходимо пробежаться по всему массиву до конца, для того чтобы обнаружить пик. Сложность в худшем случае O(n).
Немного подумав легко прийти к идее как спасти положение, ведь все мы обожаем «разделять и властвовать», это основа огромного числа замечательных алгоритмов и самый базовый кирпичик в курсах computer science. Суть подхода (именуемого бинарным поиском) проста: будем каждый раз бить задачу пополам и искать пик в подмассиве меньшего размера. Выбирая элемент для разбиения массива мы будем проверять его «на пик» и если элемент пиком не является будем двигаться в направлении роста значения. Вся игра здесь ведется вокруг того, что массив конечен, а значит и рост бесконечным быть не может. Пример кода ниже:
Как видно время намного лучше, и это ожидаемо, поскольку сложность такого алгоритма уже O(logn). Понять почему сложность такова предлагаю вам в качестве простого упражнения, а в качестве сложного можно подумать вот о чем: есть ли способ решить задачу быстрее чем за логарифм в худшем случае без всякой информации о структуре данных на входе? Напишите в комментарии что придет вам на ум.
Давайте теперь обдумаем двумерный случай, он наверное не должен быть существенно сложнее. Пусть на входе массив размера n на m из целых чисел, и надо также отыскать любой пик. Те же одномерные пики только в профиль. Правда здесь у нас много направлений для движения (4 вместо 2), ну и ладно. Давайте для начала выберем жадную стратегию - просто стартуем от произвольной точки в массиве и двигаемся в сторону наибольшего роста. Несложно понять что так мы всегда до пика доползем, но довольно быстро придет понимание что в худшем случае придется проползти чуть ли не весь массив, а это очень неприятно, это временная сложность O(nm). Пример худшего случая я приведу ниже на картинке (здесь начальная точка это левый верхний край, и идти мы будем всегда в направлении наибольшего роста):
А ниже пример такого жадного подхода и тест с худшим случаем:
Можно возразить что я просто плохо выбрал начальную точку, в связи с чем предлагаю вам подумать и доказать что при любом выборе начальной точки можно всегда придумать аналогичный худший случай с асимптотикой O(nm).
Может нас и здесь сможет спасти бинарный поиск? Вдруг это универсальная отвертка? Конечно же это не совсем так, но в данном случае он нам и правда поможет. Однако по сравнению с предыдущим случаем здесь нам придется делить задачу пополам либо по столбцам либо по строкам, и необходимо очень аккуратно поразмышлять на тему того, в какую сторону двигаться после деления задачи пополам.
Предположим что мы выбрали центральную строку в массиве в ходе деления пополам, что нам с ней делать, какой элемент из неё принимать для анализа? После некоторых размышлений (к которым вас призываю) я уверен вы скоро догадаетесь, что необходимо взять максимальный элемент из строки, и проверить его на «пик». Если он уже локальный максимум - отлично, можем взять с полки пирожок (их там два, надо будет взять средний, согласно принципу бинарного поиска). Но если нет мы сможем двигаться в сторону роста и алгоритм все равно корректно сойдется к решению. Я оставлю этот момент на подумать - это тонкая вещь и ее надо осознать. Попробуйте для понимания подумать над тем, что будет если брать не максимум, а пик (локальный максимум) в строке. Утверждается что корректность алгоритма нарушится, попробуйте привести пример. А пока приводите, вот код описанного подхода с поиском максимума в строке:
Время стало существенно лучше, потому что у этого алгоритма асимптотика уже будет O(n*logm). Это гораздо быстрее наивного подхода. Попробуйте доказать что сложность будет именно O(n*logm) (если не получается, подсмотрите в курс).
А теперь на закуску самое интересное - на самом деле можно сделать еще лучше. В случае квадратных матриц n на n мы можем добиться линейной сложности, то есть O(n). Авторы курса 6.006 об этом тоже говорят и даже приводят пример в упражнениях, до которых добираются, увы, не все. Я хочу оставить это утверждение вам на подумать, но дам подсказку (в которую можно не заглядывать, если не хотите портить себе удовольствие):
Выиграть мы можем за счет чередования процесса деления пополам - достаточно сначала выбирать центральную строку, делить по строке, и если размер задачи уменьшился - делить теперь по центральному столбцу. Таким образом будем локализовывать пик с двух сторон, и поиск максимума будет становиться постепенно «дешевле». Однако просто так добавить деление пополам по другому измерению будет некорректно - можно привести пример, когда выбирая направление роста в таком подходе при последовательных делениях мы в пик не придем. Дело в том, что после деления в ортогональном измерении нам необходимо понять, действительно ли мы идем в сторону пика, или уходим в своеобразный тупик (так сказать 2пик) - для этого необходимо помнить предыдущее наилучшее значение в сторону которого мы начали движение, и если текущее направление роста меньше по значению чем предыдущее, то, возможно, нам нужно будет уходить в смежную подматрицу, а не в ту, куда указывает текущее направление роста. Эта хитрость лучше всего осознается на примере, попробуйте изобразить такую квадратную матрицу, что после деления по строке, а потом по столбцу вы случайно уйдете не в сторону пика, а упретесь в ту строку, по которой изначально делили, но это не будет локальным максимумом.
На этом у меня сегодня все, спасибо что дочитали до конца! Подписывайтесь на канал и не забывайте заниматься самообразованием!
Желаю вам всегда стремиться к новым вершинам и достигать их (и любых и самых высоких)!