
С момента своего появления в 1999 году, Shazam использовался для идентификации песен более пятидесяти миллиардов раз. С точки зрения пользователя, все просто: ты запускаешь приложение, нажимаешь кнопку и даешь телефону прослушать песню. Через несколько секунд, несмотря на вероятный фоновой шум и искажения, оно сообщит тебе название трека и его исполнителя. Но как это работает? Разбираемся вместе с экспертами Caltat.
Говоря простым языком, процесс выглядит так:
- База данных приложения содержит огромную коллекцию «отпечатков пальцев» песен или небольших фрагментов данных об ее уникальных звуковых паттернах.
- Когда пользователь нажимает кнопку «Запись», приложение слушает музыку и создает отпечаток пальца на основе нескольких секунд услышанного звука.
- Этот отпечаток сверяется с базой данных других, уже существующих. Если твоя десятисекундная запись совпадает с имеющейся частью трека, ты получишь название песни и имя артиста. В обратном случае сервис выдаст ошибку.
Но самая интересная часть заключается в том, как добывается этот отпечаток пальца.
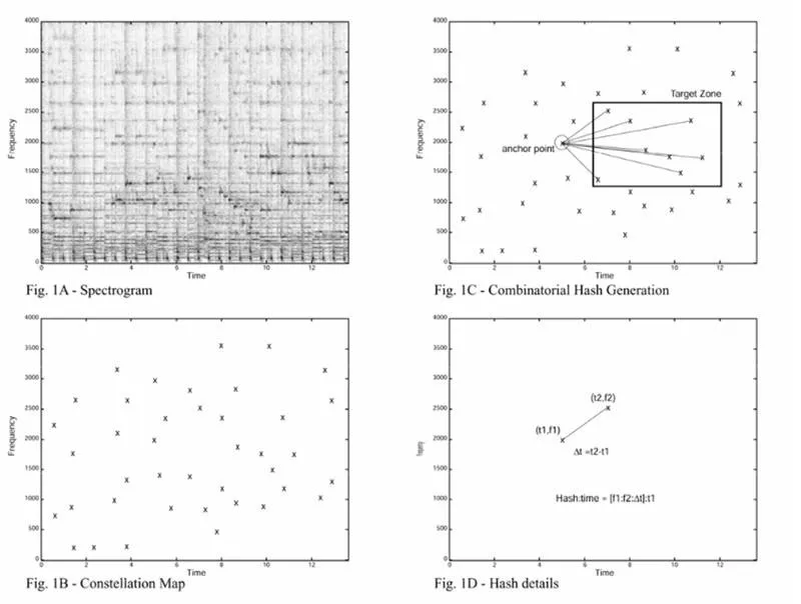
Все начинается со спектрограммы, подобной той на графике выше из статьи одного из основателей Shazam, Эйвери Ван. По сути, это график со временем на оси X (горизонтальной), частотой на оси Y (вертикальной) и амплитудой, представленной различными уровнями интенсивности цвета. Таким образом, любая последовательность звуков может быть преобразована в спектрограмму, и каждой из них присваивается уникальный набор координат. Точно так же ноты могут быть преобразованы в числа.
Большим прорывом в распознавании музыки стало осознание того, что ты можешь идентифицировать звуки всего по нескольким фрагментам данных: пикам или наиболее интенсивным частям. Избавление от большей части низкоэнергетических частей песни не только уменьшает размер спектрограммы, но и делает приложения менее восприимчивыми к идентификации глухого, последовательного фонового шума, как части целевых звуков. Представь себе горизонт города — его самые узнаваемые черты — что-то, что можно увидеть с самого дальнего расстояния.
Таким образом, каждая секунда песни урезана до нескольких самых интенсивных точек данных – все на горизонте города удалено, кроме самой верхушки. Но это все еще недостаточно эффективно, поэтому следующим шагом будет «хеширование» этой последовательности пиков. Хеширование просто берет набор входных данных, пропускает их через алгоритм и присваивает им целочисленный результат. В этом случае хэш генерируется путем взятия двух пиков высокой интенсивности, измерения времени между ними и сложения их частот.
Результатом является строка чисел, легко сохраняемая и доступная для поиска. Когда компьютер читает этот хэш, он распознает их как частоту и время-расстояние. Как только все пики в песне идентифицированы и хешированы, преобразование завершено: теперь песня имеет уникальный 32-битный номер, который служит ее идентификатором в базе данных. Что еще более важно, каждая секунда песни представлена цифрами.
Когда твой телефон слышит музыку, он выполняет именно этот процесс: он отфильтровывает все, кроме самых высоких точек, хеширует их и создает отпечаток пальца для нескольких секунд, которые он записал. Как только это будет завершено, твоему телефону просто нужно увидеть, где в базе данных появляются соответствующие строки чисел. Это позволит ему сопоставить обнаруженные частоты и время с правильной песней и вернуть их тебе в считанные секунды.