Поскольку объем данных продолжает расти, ИТ-отделу потребуются профессионалы, свободно владеющие SQL, а не только на начальном уровне, вместо этого ИТ-отделу нужно, чтобы вы знали, как оптимизировать SQL-запросы. Оптимизация SQL-запросов определяется как итеративный процесс повышения производительности запроса с точки зрения времени выполнения, частоты обращений и многих критериев оценки затрат. Таким образом, оптимизация SQL-запросов может повысить производительность.
SQL = Язык структурированных запросов. Его основная функция заключается в проектировании, создании, управлении реляционными базами данных и замене этих графических команд.
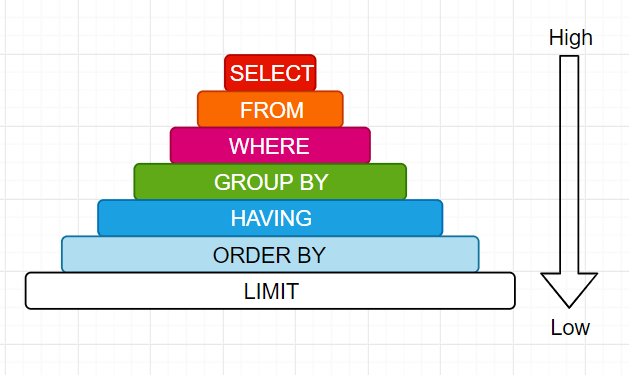
Трехуровневое развитие SQL-щика
- Знаком с базовыми операторами и функциями добавления, удаления, модификации и запроса, включая select, where, group by, having, order by, delete, insert, join, update и т.д. Вы можете выполнять ежедневный поиск данных и простой анализ
- Освоить синтаксис высокого уровня, такой как набор, агрегатные функции, подзапросы, условное выражение, строковые функции, арифметические функции, функции даты и времени, и знать синтаксические различия различных баз данных
- Знаком с тем, как оптимизировать инструкции SQL для достижения максимальной эффективности запросов, Понимать концепцию транзакций, блокировок, индексов, ограничений, представлений, метаданных и т. Д., А также знать, как использовать hive SQL, spark SQL, pymsql и другие инструменты.
1 метод - использовать Explain
В нашей повседневной работе нам нужно найти некоторые инструкции SQL, которые выполнялись в течение длительного времени. Иногда мы используем ключевое слово “explain” для просмотра одного из этих планов выполнения SQL-запроса.
{EXPLAIN | DESCRIBE | DESC} tbl_name [col_name | wild]
{EXPLAIN | DESCRIBE | DESC} [explain_type] {explainable_stmt | FOR CONNECTION connection_id}
explain_type: { EXTENDED | PARTITIONS | FORMAT = format_name }
format_name: { TRADITIONAL | JSON }
explainable_stmt: { SELECT statement | DELETE statement | INSERT statement | REPLACE statement | UPDATE statement }
Использовать его просто
например EXPLAIN SELECT * FROM categories
также
- Он может использоваться с SELECT, DELETE, INSERT, REPLACE и UPDATE
- Он используется FOR CONNECTION connect_idвместо интерпретируемого утверждения
- Вы можете добавить индекс в таблицу, чтобы оператор мог выполняться быстрее, используя поиск по индексу
- Его можно использовать с инструкцией SELECT, результаты EXPLAIN отображаются и выводятся в табличном формате, где каждая строка представляет таблицу.
- расшифровку столбцов по explain можно погуглить...
Второй метод - Значение, содержащееся в IN в инструкции SQL, не должно быть слишком большим
Для пакетного запроса мы обычно используем ключевое слово “IN” для фильтрации данных. Все константы в IN хранятся в массиве, и массив сортируется. Но, если значение велико, потребление также относительно велико.
select id,name from category where id in (1,2,3...1000000000000);
Если мы не налагаем никаких ограничений, оператор запроса может запрашивать много данных за один раз, что может легко привести к тайм-ауту интерфейса.
Мы должны использовать “LIMIT”, чтобы ограничить результат:
select id,name from category where id in (1,2,3...100) limit 500;
Также обратите внимание, что “in” и “not in” должны использоваться с осторожностью, в противном случае это приведет к полному сканированию таблицы.
Например,
select id from t where num in(1,2,3)
Для последовательных значений вы можете использовать "BETWEEN” вместо “IN”
3. Оператор SELECT должен указывать имя поля
Часто, когда мы пишем инструкции SQL, для удобства мы хотели бы использовать select * напрямую, чтобы узнать данные всех столбцов в таблице одновременно.
select * from user where id =1;
Но на самом деле нам действительно нужно использовать только два из этих столбцов. Это привело к потере ресурсов базы данных, таких как память или процессор. Кроме того, время передачи данных через пропускную способность сети также будет увеличено. Кроме того, по этим причинам увеличивается вероятность использования покрывающих индексов.
При изменении структуры таблицы предыдущее прерывание также необходимо обновить и требует, чтобы мы подключили имя поля непосредственно после инструкции “select”. Будет большое количество операций с таблицей возврата, что приведет к низкой производительности SQL-запроса.
select name,age from user where id=1;
Приведенный выше пример показывает, что проверяются только те столбцы, которые необходимо использовать, а избыточные столбцы вообще не нужно извлекать.
4. Ограничение
Для обработки большого объема данных необходимо рассмотреть, существует ли лучший метод повышения эффективности выполнения программы.
Первый пример без ключевого слова “limit”
select* from member where = "Golden Sachs" order by enrolment date
Второй пример с ключевым словом “limit”
select* from member where = "Golden Sachs" order by enrolment date limit 1
Эти 2 метода запроса очень распространены, но знаете ли вы реальную разницу между ними? Первый пример занял 0,7 с, а второй пример занял 0,32 с. Из вышесказанного видно, что в случае большого объема данных. Преимущества использования ключевого слова “limit” для оптимизации работы с запросом вполне очевидны.
Примечание: если имя пользователя в приведенном выше поле таблицы задано как индекс, использование Limit 1 в это время не оказывает очевидного влияния на скорость запроса.
5. Индекс
Индекс подобен каталогу товаров, и конкретное содержание товара может быть точно определено с помощью каталога. Мы добавляем первичный ключ к таблице, когда создаем таблицу. Структура хранения таблицы похожа на древовидную структуру. Если таблица может иметь только один первичный ключ, а сканирование таблицы имеет только один “кластеризованный индекс”, потому что функция первичного ключа заключается в преобразовании “табличного” формата данных в формат “древовидного индекса”. Если индекс не добавлен, план выполнения SQL-запроса будет иметь полное сканирование таблицы. Например, для десятков миллионов записей в таблице база данных должна проверять одну за другой, потому что система баз данных просматривает всю таблицу строка за строкой и проверяет, в частности, поле class_id. Преимущество добавления индекса заключается в ускорении запроса, что может существенно сократить количество записей / строк, которые необходимо сканировать.
Индексы можно классифицировать двумя способами
- Логическая классификация
- Физическая классификация
В соответствии с логической классификацией индекс можно разделить на
- Индекс первичного ключа: таблица может иметь только 1 индекс первичного ключа, дублирование или значение NULL не допускается
- Уникальный индекс: столбцы данных не должны повторяться, а значения NULL разрешены.
- Обычный индекс: таблица может создавать несколько обычных индексов, общий индекс может содержать несколько полей, допускается дублирование данных и допускается вставка нулевых значений.
- Полнотекстовый индекс: это особый тип индекса, который обеспечивает доступ к индексу для полнотекстовых запросов к символьным или двоичным столбцам данных или ускоряет поиск по ключевым словам.
В соответствии с физической классификацией индекс можно разделить на
- Кластеризованный индекс: это индекс первичного ключа в таблице. Поскольку записи могут физически храниться в таблице базы данных только одним способом, для каждой таблицы может быть только один кластеризованный индекс. Кластеризованный индекс имеет хорошую производительность при точном поиске и поиске по диапазону по сравнению с обычным индексом и полным сканированием таблицы.
- Некластеризованный индекс: он также используется для ускорения операций поиска. Он физически не определяет порядок, в котором записи вставляются в таблицу.
Методы оптимизации
- Используйте покрывающий индекс для выполнения операций запроса, чтобы избежать возврата к таблице
- Если в поле сортировки не используется индекс, сортируйте как можно меньше
- Попробуйте использовать union all вместо union . Ключевое слово “union” должно выполнять уникальные операции фильтрации после объединения наборов, что повлечет за собой сортировку, увеличение большого количества операций ЦП, увеличение потребления ресурсов и задержки.
- Если в ограничениях нет индексов в других полях, используйте ключевое слово “или” как можно реже. Если одно из полей с обеих сторон не является индексным полем, это приведет к тому, что запрос не будет проходить через индекс.
6. Различайте IN и EXIST, NOT IN и NOT EXIST
- select * from form A where id in (select id from form B)
Приведенный выше оператор SQL эквивалентен
- select * from form_A where exists (select * from form_B where form_B.id=form_A.id)
Разница в “IN” и “EXIST” в основном приводит к изменению производительности. Если оператор “EXIST”, то внешняя таблица является управляющей таблицей, к которой обращаются в первую очередь. Если это “IN”, то сначала выполняется подзапрос. Таким образом, “IN” подходит для случая, когда внешняя таблица большая, а внутренняя маленькая; “EXIST” подходит для случая, когда внешняя таблица, а внешняя - большая.
Что касается "NOT EXIST” и “NOT IN”, вы можете обратиться к вопросу из StackOverflow:
Какой из этих запросов выполняется быстрее?
SELECT ProductID, ProductName
FROM Northwind..Products p
WHERE NOT EXISTS (
SELECT 1
FROM Northwind..[Order Details] od
WHERE p.ProductId = od.ProductId)
Или NOT IN:
SELECT ProductID, ProductName
FROM Northwind..Products p
WHERE p.ProductID NOT IN (
SELECT ProductID
FROM Northwind..[Order Details])
Планы выполнения могут быть одинаковыми на данный момент, но если какой-либо столбец будет изменен в будущем, чтобы разрешить NULL, то NOT IN версии потребуется выполнить больше работы (даже если NULL в данных фактически нет), и семантика и скорость NOT IN, если NULL-ы присутствуют, вряд ли будет той, которую вы хотите.
7. Используйте разумный метод подкачки
Разбиение на страницы является общей функцией в системах баз данных, особенно веб-страниц. Когда порядок величины меньше 10 000, проблемы с производительностью подкачки не могут быть обнаружены; когда число составляет от 10 000 до 1 миллиона, проблемы с производительностью вызывают мало беспокойства; когда число превышает 1 миллион, необходимо учитывать производительность подкачки.
Индексы могут значительно повысить производительность индексации, а также косвенно улучшить производительность подкачки. Но даже для простой таблицы со 100 записями на странице, когда имеется 10 000 страниц, предполагаемая производительность недостаточно высока. Как оптимизировать?
Совместный индекс может значительно повысить скорость поиска. Ключевое слово “limit” можно использовать не более чем для 10 определенных условий, чтобы повысить эффективность подкачки. Вы можете выполнить сортировку по идентификатору автоматического номера при подкачке. Таким образом, вы можете применить предыдущие условия поиска, а также ограничение диапазона идентификаторов, чтобы при отображении следующей страницы вам нужно было искать только первые несколько элементов.
select id,name from table_name where id> 81111 limit 20
8. Сегментированный запрос
На некоторых страницах выбора пользователя диапазон времени, выбранный некоторыми пользователями, может быть слишком большим, что приводит к медленному выполнению запроса. Основная причина - слишком много строк для сканирования. В это время вы можете выполнять запросы по программам, сегментировать, перебирать и продолжать результаты для отображения. Например, когда количество проверенных строк превышает 1 миллион, можно использовать сегментированные запросы.
9. Избегайте нулевого оценочного суждения для поля в предложении “WHERE”
Это приведет к тому, что движок откажется от использования индекса и выполнит полное сканирование таблицы.
select id,from t where number is null
Для числа можно установить значение по умолчанию 0, чтобы гарантировать, что столбец num в таблице не имеет нулевого значения.
select id,from t where number is 0
10. Принудительный Индекс используй ты
При необходимости вы можете использовать команду force index, чтобы указать, какой индекс использовать для этого запроса. Команда force index не позволяет оптимизатору SQL использовать неэффективный индекс.
11. Присоединяйтесь к оптимизации JOIN
- соединение по левому краю: левая таблица является ведущей таблицей
- Внутреннее соединение: SQL автоматически найдет таблицу с меньшим количеством данных для управления таблицей
- Правое соединение: правый стол является ведущим столом
Примечание: полная оптимизация соединения отсутствует
Попробуйте использовать внутреннее соединение и избегать соединения слева или используйте таблицу с меньшим количеством данных, чтобы управлять таблицей с большим количеством данных
Таблицы, участвующие в совместном запросе, представляют собой как минимум 2 таблицы, которые обычно отличаются по размеру. Если метод подключения является внутренним соединением, SQL автоматически выберет таблицу с меньшим количеством данных в качестве основной таблицы при отсутствии других условий фильтрации, но левое соединение следует принципу левого перемещения вправо при выборе основной таблицы.