
Непредвиденные сбои являются одной из самых сложных для разрешения проблем, особенно в распределенной системе. При написании кода разработчики уделяют особое внимание обработке исключений, а при тестировании именно этот аспект отнимает больше всего времени. Проблема здесь не просто в написании кода для обработки сбоев. Что происходит при сбое на компьютере, где работает микрослужба? Необходимо не просто определить сбой микрослужбы (что само по себе непросто), но и найти способ перезапустить микрослужбу.
Микрослужба должна быть устойчива к сбоям и часто перезапускаться на другом компьютере без ущерба для доступности. Устойчивость также относится к сохранению состояния микрослужбы и возможности восстановить это состояние и успешно перезапуститься. Другими словами, необходима устойчивость функции вычисления (процесс можно перезапустить в любое время), а также устойчивость состояния или данных (без потери данных, с сохранением согласованности данных).
Проблемы устойчивости актуальны и для других ситуаций, например, если сбой происходит во время обновления приложения. Микрослужба, работающая с системой развертывания, должна определить, может ли она перейти к новой версии или лучше откатиться до предыдущей версии для сохранения состояния. Необходимо подумать, достаточно ли доступных компьютеров для обновления или как восстановить предыдущие версии микрослужбы. Микрослужба должна передавать сведения о своей работоспособности, чтобы все приложение и оркестратор могли принимать эти решения.
Кроме того,устойчивость связана с поведением облачных систем. Как уже упоминалось, облачная система должна принимать сбои и пытаться восстановиться автоматически. Например, в случае сбоя сети или контейнера клиентские приложения или клиентские службы должны иметь стратегию для повторной отправки сообщений или запросов, поскольку, как правило, сбои в облаке являются частичными. В этом руководстве в разделе Реализации устойчивых приложений рассказывается, как обрабатывать частичные сбои. Там описываются такие методы, как повторная попытка с экспоненциальной задержкой или шаблон размыкателя цепи в .NET с использованием библиотек, например Polly, где содержится целый ряд политик для обработки таких сбоев.
Управление работоспособностью и диагностика микрослужб
Микрослужба должна сообщать о своей работоспособности и диагностике. Это может казаться очевидным, и об этом часто забывают. Но, в противном случае, сведений о работе будет недостаточно. Сопоставлять диагностические события в наборе независимых служб и решать проблемы расфазировки сигналов, чтобы разобраться в порядке событий, довольно непросто. Так же, как вы взаимодействуете с микрослужбами по согласованным протоколам и форматам данных, необходимо стандартизировать запись событий работоспособности и диагностических событий, которые сохраняются в хранилище событий, доступном для запросов и просмотра. При использовании микрослужб важно, чтобы команды разработчиков согласовали единый формат ведения журнала. Необходим единообразный подход к просмотру диагностических событий в приложении.
Проверки работоспособности
Работоспособность отличается от диагностики. Работоспособность связана с отчетами микрослужбы о своем текущем состоянии для принятия необходимых мер. Хороший пример — работа с механизмами обновления и развертывания для поддержания доступности. И хотя служба может утратить работоспособность в результате аварийного завершения процесса или перезагрузки компьютера, она по-прежнему может сохранять свою функциональность. Вы только усугубите ситуацию, если выполните обновление. Рекомендуется сначала провести расследование и дать микрослужбе время на восстановление. События работоспособности от микрослужбы помогают принимать обоснованные решения и, по сути, создавать самовосстанавливающиеся службы.
В разделе Выполнение проверок работоспособности в службах ASP.NET Core объясняется, как использовать библиотеку ASP.NET HealthChecks в микрослужбах, чтобы они сообщали о своем состоянии службе мониторинга и можно было принять необходимые меры.
Вы также можете использовать отличную библиотеку с открытым кодом с именем AspNetCore.Diagnostics.HealthChecks, доступную в GitHub и в виде пакета NuGet. Эта библиотека также выполняет проверки работоспособности и обрабатывает два вида проверок:
- Жизнеспособность. Проверяет, что микрослужбы находятся в активном состоянии, то есть могут принимать запросы и отвечать.
- Готовность. Проверяет готовность зависимостей микрослужбы (база данных, службы очередей и т. д.), чтобы микрослужба выполняла поставленные задачи.
Использование потоков диагностики и записи событий
Журналы содержат сведения о работе приложения или службы, в том числе исключения, предупреждения и информационные сообщения. Как правило, журналы имеют текстовый формат, где каждая строка обозначает событие, хотя исключения часто отображаются в виде трассировки на нескольких строках.
В монолитных серверных приложениях можно записывать журналы в файл на диске (файл журнала), а затем анализировать его с помощью любого инструмента. Поскольку приложение выполняется на фиксированном сервере или виртуальной машине, анализировать поток событий обычно не слишком сложно. Но в распределенных приложениях, где несколько служб выполняется на многих узлах в кластере оркестратора, сопоставить распределенные события бывает непросто.
Приложение на основе микрослужб не должно пытаться самостоятельно сохранить поток вывода событий или файлов журнала или хотя бы управлять маршрутизацией событий в центральное хранилище. Оно должно быть прозрачным, то есть каждый процесс должен просто записывать поток событий в стандартный поток вывода, который будет поступать в инфраструктуру среды выполнения, где оно запущено. Пример маршрутизатора потока событий — Microsoft.Diagnostic.EventFlow, который собирает потоки событий из нескольких источников и публикует их в систему вывода. Это может быть стандартный поток вывода для среды разработки или облачных систем, таких как Azure Monitor и Диагностика Azure. Существуют надежные сторонние платформы и инструменты анализа журналов, которые могут выполнять поиск, выводить предупреждения, составлять отчеты и отслеживать журналы, даже в режиме реального времени, например Splunk.
Оркестраторы, управляющие сведениями о работоспособности и диагностике
При создании приложения на основе микрослужб вы имеете дело со сложной структурой. Разумеется, с одной микрослужбой работать просто, но все усложняется при наличии десятков и сотен типов и тысяч экземпляров микрослужб. Недостаточно просто создать архитектуру микрослужб — необходимо обеспечить высокую доступность, адресуемость, устойчивость, работоспособность и диагностику, если вы хотите получить стабильную и слаженную систему.
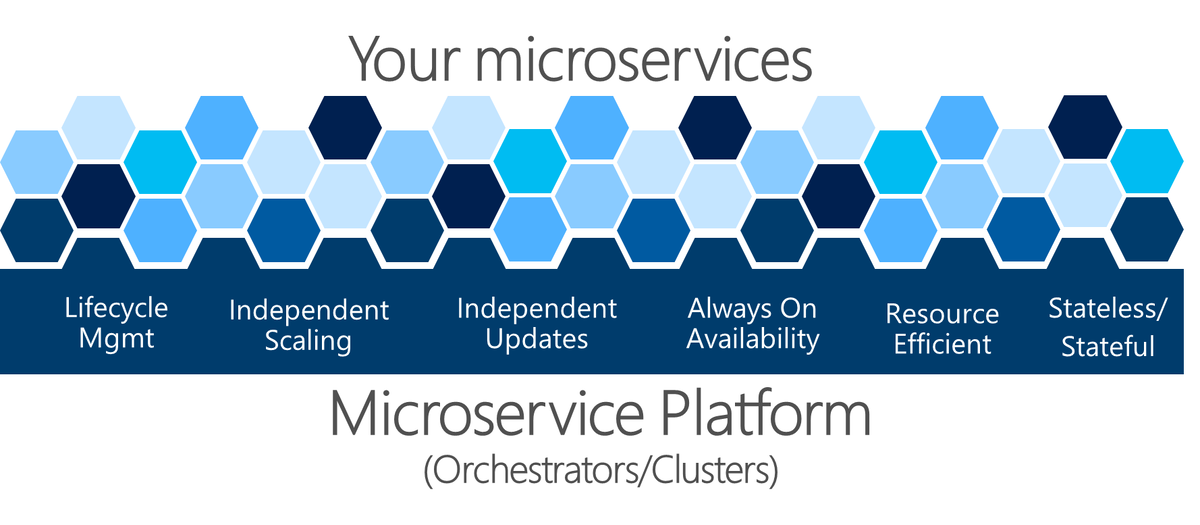
Рис. Платформа микрослужб необходима для управления работоспособностью приложения
Сложные проблемы, показанные на рисунке 4-22, трудно решить самостоятельно. Командам разработчиков следует сосредоточиться на решении бизнес-задач и разработке пользовательских приложений на основе микрослужб. Им не следует думать о решении сложных проблем с инфраструктурой. В противном случае стоимость приложения на базе микрослужб была бы огромной. Поэтому и существуют платформы для микрослужб, называемые оркестраторами или кластерами микрослужб. Эти платформы решают проблемы сборки и запуска службы и эффективного использования ресурсов инфраструктуры. Это упрощает создание приложений на базе микрослужб.
Различные оркестраторы могут походить друг на друга, но отличаться по функциям и уровню зрелости диагностики и проверок работоспособности. Иногда это зависит от платформы ОС, как описано в следующем разделе.