Данные не говорят сами за себя - центральную роль здесь играет наш опыт и наше суждение.
Д. Шпигельхалтер
В этой статье я попробую это доказать.
Очень многие, кто знаком с анализом данных, да что тут скрывать и я тоже, используют ряд методов, которые зачастую приводят нас к ошибочным выводам. А некоторые из них этим еще и пользуются. Например СМИ, когда публикуют результаты опросов.
Рассмотрим на примере датасета шоколадных батончиков.
Скажем спасибо flavorsofcacao.com за предоставленные данные
Данные взяты отсюда https://flavorsofcacao.com/chocolate_database.html
Допустим перед нами стоит следующая цель.
Необходимо выяснить, имеют ли шоколадные батончики с самыми высокими рейтингами какие-либо характеристики, которые могут помочь вам сузить поиск поставщиков (например, процентное содержание какао, страна происхождения бобов и т.д.).
Что есть из данных?
- "id" - идентификационный номер отзыва
- "производитель" - название производителя батончика
- "местоположение компании" - местонахождение производителя
- "просмотренный год" - с 2006 по 2021 год
- "bean_origin" - Страна происхождения какао-бобов
- "bar_name" - название шоколадного батончика
- "cocoa_percent" - содержание какао в батончике (%)
- "num_ingredients" - количество ингредиентов
- "ингредиенты" - B (бобы), S (сахар), S * (подсластитель, отличный от сахара или свекловичного сахара), C (какао-масло), (V) ваниль, (L) лецитин, (Sa) соль
- "обзор" - краткое изложение наиболее запоминающихся характеристик шоколадного батончика
- "рейтинг" - 1,0-1,9 плохо, 2,0-2,9 разочаровывает, 3,0-3,49 рекомендуется, 3,5-3,9 настоятельно рекомендуется, 4,0-5,0 – превосходно
так как просят проанализировать влияние лецитина на рейтинг, то сразу выделим компоненты из столбца "ингредиенты" и закодируем наши переменные.
Ну а дальше любимое многих.... барабанная дробь.... Парные графики.
На самом деле очень полезная штука. Позволяет выявить визуально зависимость числовых переменных. Но например в нашем случае это особо не помогло. Просто потому, что связь переменных с рейтингом мала
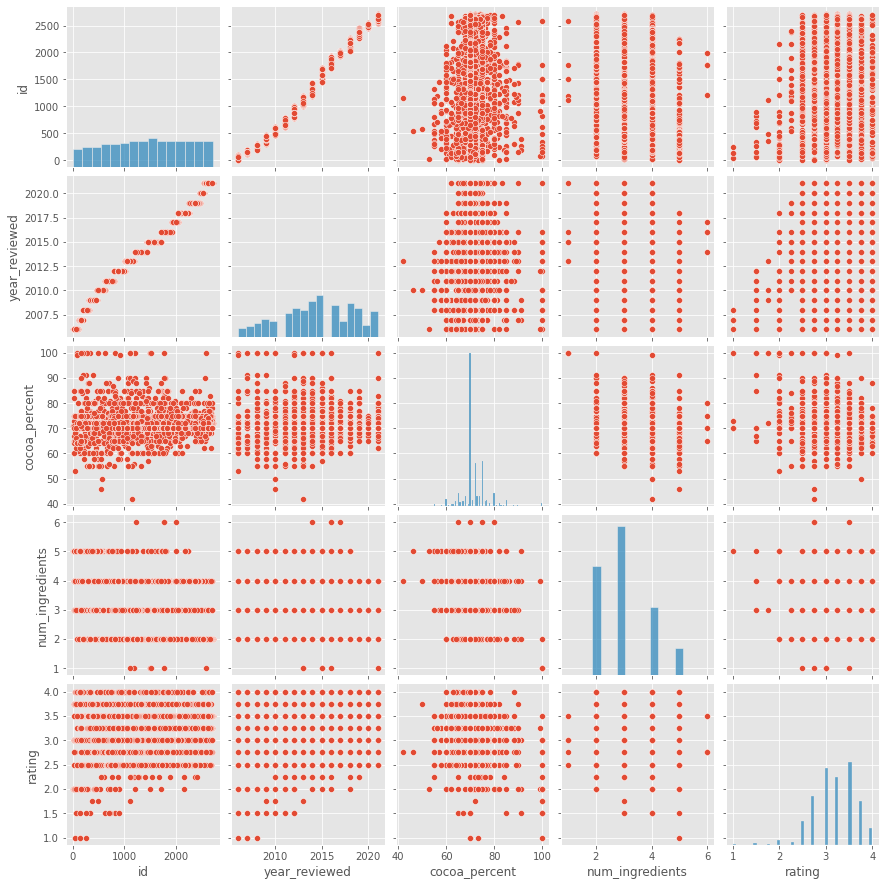
Ну и в догонку посмотрим на значение коэффициентов корреляции Пирсона
Как видно коэффициенты очень очень маленькие и связей переменных с рейтингом нет. Значит все, расходимся?
Многие тут и заканчивают свой анализ.
И это первый обман.
На графике показано распределение рейтинга относительно содержания какао бобов в батончике. Без всяких тестов видно, что батончики с содержанием какао от 60 до 80 % имет высокий рейтинг.
Но почему при малом коэффициенте корреляции (-0,077), который говорит что связи нет, связь все таки есть?
Ответ - Нелинейность.
Коэффициент корреляции Пирсона учитывает линейные взаимосвязи между переменными. Для коэффициента Пирсона она выглядит примерно вот так...
Но на самом дела она вот такая.
Какие можно сделать выводы?
Ну во первых с подозрением относиться к тем кто говорит, что между переменными есть корреляционная зависимость или что ее нет.
Во вторых, проверять данные на наличие нелинейных связей.
#аналитика #analytics