Зачастую модели машинного обучения обучаются на наборах векторов, характеризующих однотипные объекты в разные промежутки времени. Например, это может быть история потреблений товаров в филиалах организации. То есть датасет может быть фактически разделен на группы по относимости к филиалу. В этих случаях требования к валидации модели могут быть усилены не просто оценкой прогнозов на будущие периоды (логично модель обучать на прошлых периодах), но и стабильностью работы на новых объектах (которых в обучающей выборки не было). Для этих целей в библиотеке Scikit-learn существует специальный сплиттер GroupKFold.
Создадим демонстрационный датафрейм:

Для разбиения датасета на две группы по колонке id, создадим объект класса GroupKFold с параметром n_splits=2, а затем вызовем его метод split, в параметре groups которого зададим колонку разбиения:
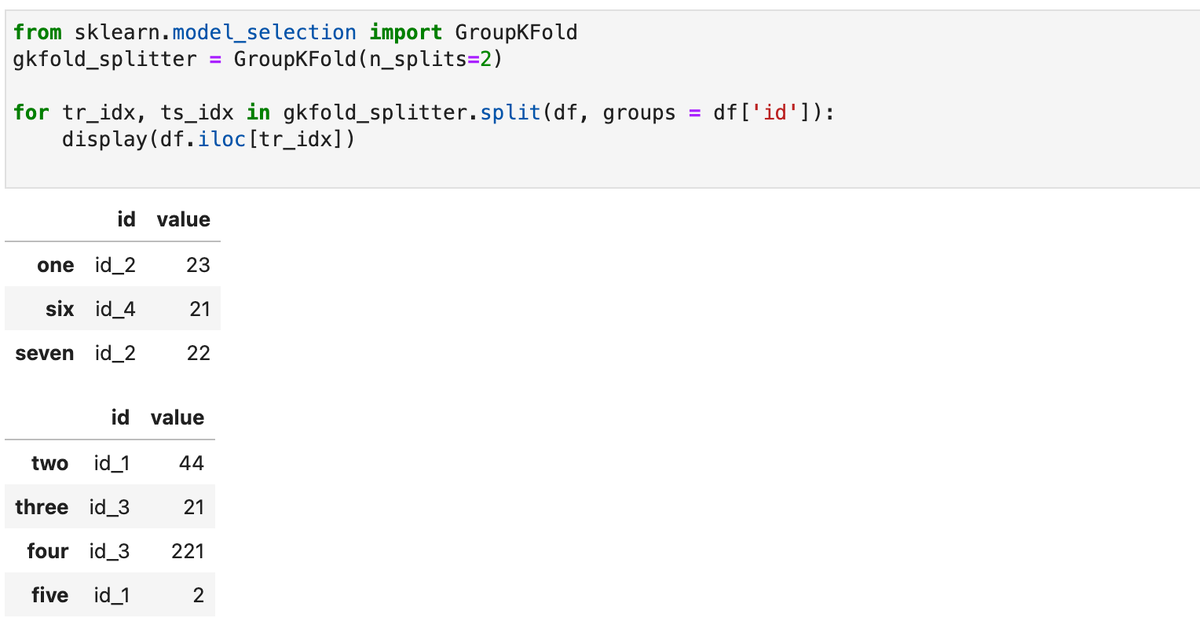
Как видим, группы в получившихся наборах не пересекаются.