
Pod – это объект Kubernetes, который является описанием атомарной единицы рабочей нагрузки. При создании объекта типа Pod, Kubernetes запускает один или несколько контейнеров на одной из рабочих нод. При удалении - завершает работу этого контейнера, или контейнеров.
Pod - является объектом или ресурсом Kubernetes. Но также Pod-ом (или в русском написании подом) называют и реально запущенные в контейнерной среде процессы, связанные с объектом типа Pod. Поэтому можно часто услышать о "подах, запущенных в namespace-е", или "под перестал работать", "потушить под" и т.д. В этих случаях речь идет о процессах, запущенных на рабочей ноде. Pod, как объект Kubernetes, является отражением реальных процессов, запущенных в кластере. Если объект типа Pod удален, значит, экземпляр сервиса потушен, если объект типа Pod имеет статус Running, то экземпляр сервиса работает и т.д.
Контейнеры, описанные в поде, Kubernetes запускает, удаляет и обновляет, как единое целое. Не стоит в рамках одного пода запускать несколько контейнеров, реализующих бизнес-логику. Т.е. под — это не аналог docker-compose. В одном поде обычно запускают один основной контейнер, в котором находится бизнес-логика, а остальные контейнеры предоставляют, связанные функции, такие как мониторинг, логирование, конфигурация. Например, запускается основное приложение и одновременно с ним запускается агент, который собирает метрики из основного приложения и отправляет их на центральный сервер. Запуск на одной ноде этих процессов позволяет избежать дополнительных хождений по сети, т.к. взаимодействие происходит по локальному интерфейсу.
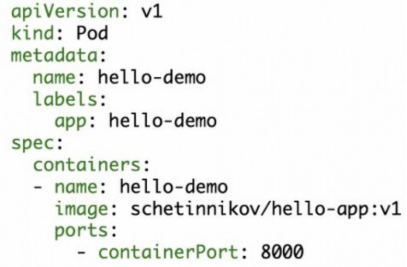
Давайте теперь посмотрим, как выглядит простейшее описание объекта типа Pod в yaml формате:
В spec находится спецификация пода. Pod - это набор контейнеров, поэтому в поле containers указывается массив с описанием контейнеров. В нашем случае контейнер один, для него укажем имя (name), образ (image) и доступные порты (ports)
Как только создается новый объект типа Pod, информация об этом событии через API Server передается всем заинтересованным в этом компонентам, в том числе встроенным контроллерам. Прежде всего информацию получает компонент kube-scheduler, и получив спецификацию пода он принимает решение о том, на какой ноде этот под будет реально запущен.
Если подов несколько, то для каждого будет приниматься отдельное решение.
Событие, что конкретный под был распределен на ноду, получает компонент kubelet и уже дальше самостоятельно, обращаясь к API конкретной системы контейнеризации, запускает контейнеры.
Как только конкретный под был распределен на конкретную ноду, он не может быть перераспределен куда-то еще. Перераспределение возможно, только если под был остановлен или удален. Тогда создается новый под, с таким же именем и спецификацией.
Под может пребывать в следующих фазах. Как только под был создан, он находится в фазе PENDING, до тех пор пока хотя бы один из контейнеров не запустится. Как только хотя бы один контейнер запустился, он переходит в состояние RUNNING. А когда все контейнеры завершатся, переходит либо в Succeeded, если завершение произошло успешно, либо Failed, если неуспешно. Так же есть отдельная стадия UNKNOWN, когда kubelet перестал сообщать статус пода в API Server.
Завершение пода
Поскольку поды представляют собой процессы, запущенные на ноде в кластере, крайне важно, чтобы эти процессы завершались корректно, в случае если они уже не нужны. Например, если послать процессу SIGKILL, он не получит возможности корректно завершиться: обработать до конца текущие запросы и задачи, сбросить кэш на диск, если нужно и т. д. С другой стороны, важно следить, чтобы процесс в конце концов заканчивался, а не висел бесконечно в фоне.
Для этого kubelet старается реализовать механизм постепенной деградации (graceful degradation).
Что происходит, если мы удалим под:
Под переводится в состоянии Terminating.
Различные компоненты и контроллеры получают событие о завершении пода и производят соответствующие действия: убирают под из балансировки трафика и т.д. Также событие получает kubelet и начинает завершение пода на ноде.
kubelet сначала посылает сигнал SIGTERM всем контейнерам пода и ждет некоторое время (т.н. graceful period), по умолчанию это 30 секунд. Если в течение этого времени, контейнер не завершился, то kubelet шлет SIGKILL и удаляет под с помощью API server-а. Время ожидания можно настроить, но это время не гарантировано Kubernetes-ом, и иногда возможны ситуации, когда контейнер убивается за меньшее время. Поэтому крайне желательно на уровне приложения предусматривать такие ситуации и уметь их корректно обрабатывать.
Проверки
Kubelet следит за состоянием контейнеров, относящихся к поду, и в случае проблем может предпринимать действия для их исправления.
Kubelet может периодически производить следующие проверки контейнеров, связанных с подом:
livenessProbe - проверка на то, что контейнер жив и приложение работает. Если проверка не прошла, то kubelet убивает контейнер и в зависимости от настроек, может перезапустить его.
readinessProbe - проверка на способность контейнера отвечать на запросы. Если проверка не прошла, то тогда под убирается из балансировки, и запросы к нему не идут.
startupProbe - проверка на то, запустился контейнер или нет. Если проверка не прошла, то тогда kubelet убивает контейнер и, в зависимости от настроек, может перезапустить контейнер.
Настройки и параметры проверок описываются в атрибутах livenessProbe, readinessProbe и startupProbe спецификации контейнера.
У kubelet-а есть 3 основных способа проверки:
ExecAction - выполнение команды внутри контейнера. Если команда завершилась с кодом 0, то проверка считается успешной
HTTPGetAction - выполнение http запроса по определенному порту и урлу. Если http статус код ответа больше или равен 200 и меньше 400, то тогда проверка считается успешно пройденной
TCPSocketAction - выполнение tcp запроса по определенному порту. Если порт открыт, то проверка считается успешно пройденной.
Ограничение вычислительных ресурсов
Одной из важных задач Kubernetes-а, как оркестратора, является изоляция процессов друг от друга. По умолчанию контейнеры могут использовать все доступные на ноде вычислительные ресурсы: CPU и оперативную память. С помощью квот на ресурсы администраторы могут установить общее ограничение на потребление ресурсов для всех объектов, привязанных к конкретному пространству имен (namespace). Но также можно ограничения установить и для конкретных контейнеров внутри пода.
Чаще всего ставятся ограничения на CPU и оперативную память.
Есть два типа ограничений:
· запросы (request) - запрашиваемые ресурсы. Это те ограничения по ресурсам, которые использует kube-scheduler для того, чтобы принять решение о том, на какую ноду можно распределить под. Также kubelet на ноде резервирует системных ресурсов для этого контейнера не меньше, чем указано в запросах.
· лимиты (limit) - максимально доступные ресурсы. Это те ресурсы, за которые не дает выйти kubelet и контейнерное окружение. Например, если контейнер попробует использовать больше памяти, чем у него указано в лимитах, ядро его может убить с ошибкой Out Of Memory. Если запрошенной памяти (requests) у контейнера 256 MiB, а лимиты (limits) по памяти - 4Gb, то у процесса будет гарантированно 256 MiB, и, если есть еще свободная память на ноде, она будет выделена при необходимости. Но не больше 4Gb, даже если свободная память есть на ноде.Ограничения указываются в спецификации контейнера в опциональном атрибуте resources.
Ресурсы описываются в следующих единицах:
CPU описывается в долях процессорного времени, выделенного для контейнера. 1 CPU- это эквивалентно 1 vCPU/Core для облачных провайдеров и 1 виртуальное ядро (гипертред) для железных серверов на архитектуре Intel. Допускается использование дробных значений. Например, можно указать 0.1 или 100m. Суффикс m означает милликор - 0.001 CPU. Т.е. записи 0.1 и 100m эквивалентны. Меньше 1m указать нельзя. Память по умолчанию описывается в байтах, но также можно использовать суффиксы K, М, G для указания кило, мега и гигабайт. Или в степенях двойки соответственно - Ki, Mi, Gi.
Ссылки:
#kubernetes #pod #container #devops