Заполнение пропущенных значений является во многом творческой задачей. Наиболее популярными кандидатами, как правило, являются среднее, медиана, ноль. Однако в этой статья расскажу про более продвинутый и в то же время такой же легкий способ - заполнение по среднему среди наиболее похожих точек. Рассмотрим датафрейм:

Для заполнения воспользуемся классом KNNImputer из модуля sklearn.impute:
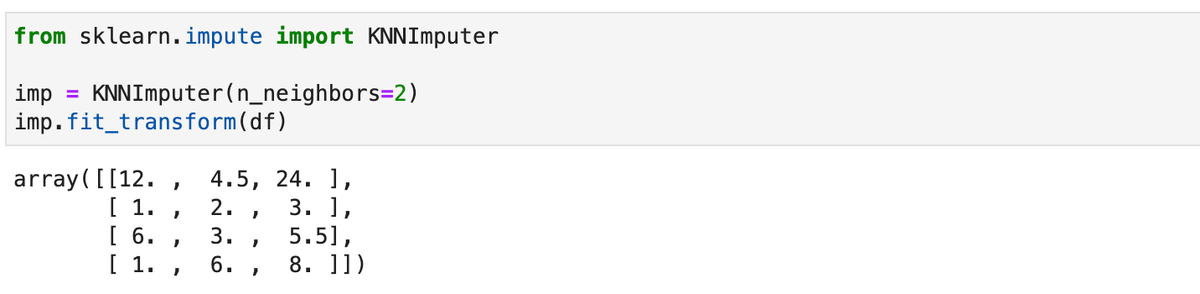
В качестве метрики для вычисления ближайших точек используется nan_euclidean (подробнее описывал здесь). Первое значение заполнено 4.5, так как это среднее между вторыми координатами для второй и третьей точек:
А 5.5 - это среднее между третьими координатами первой и третьей точек:
Не забывайте, что корректное определение ближайших соседей напрямую зависит от предобработки данных, поступающих в евклидову метрику. В частности, требуется преобразование категориальных переменных и шкалирование числовых. О том, как это делать писал ранее:
Масштабирование:
1. RobustScaler
Кодирование категорий: