Перевод статьи с Хабр: https://habr.com/ru/post/486466/
Если вы используете Apache Spark, у вас, вероятно, есть несколько приложений, которые потребляют некоторые данные из внешних источников и выдают некоторый промежуточный результат, который вот-вот будет использован некоторыми приложениями далее по цепочке обработки, и так далее, пока вы не получите окончательный результат.
Мы так считаем, потому что у нас есть похожий конвейер с множеством процессов, подобных этому:
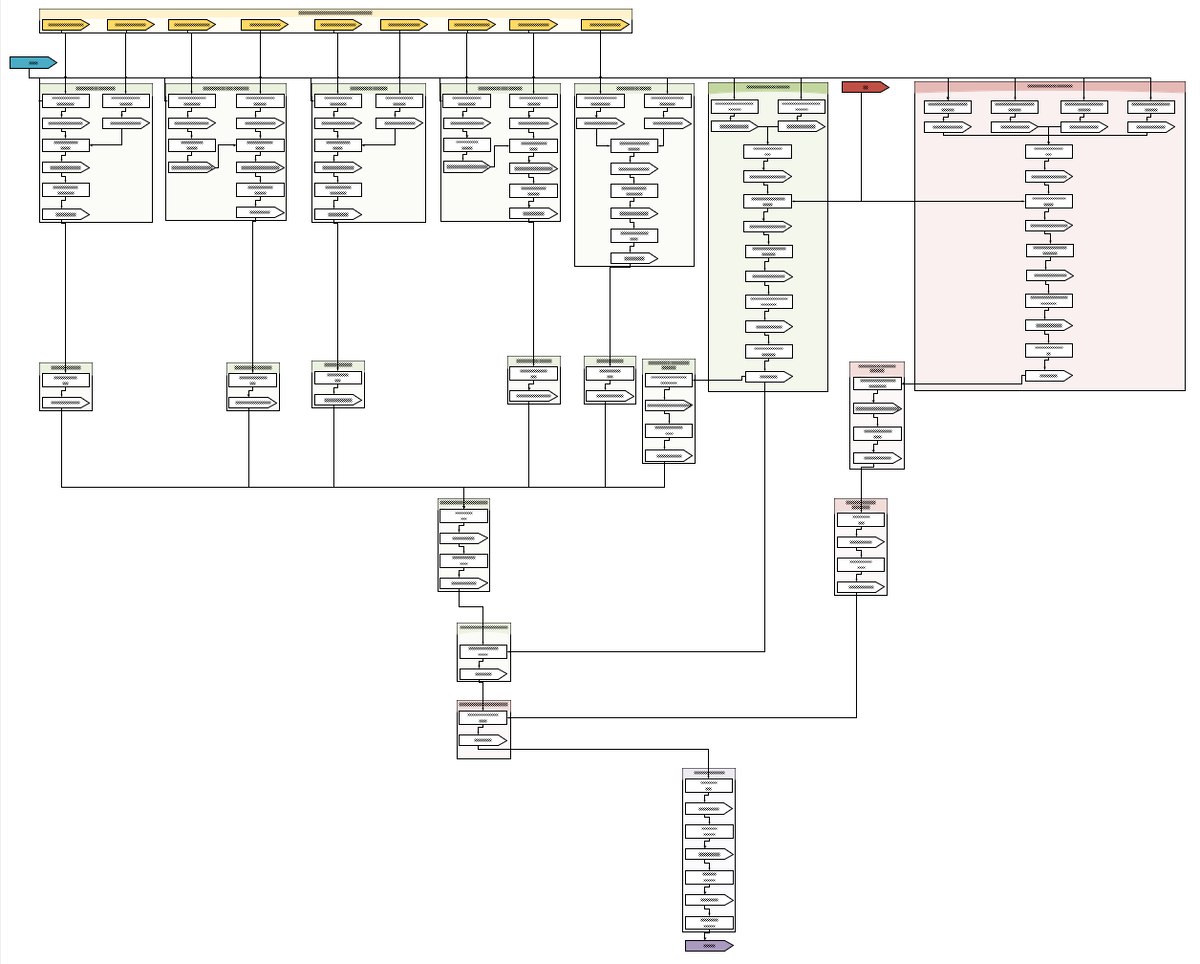
Каждый прямоугольник представляет собой приложение Spark с набором собственных параметров выполнения, а каждая стрелка представляет собой одинаково параметризованный набор данных (внешне сохраненный - выделен цветом; обратите внимание на количество промежуточных). Этот пример не самый сложный из наших процессов. И мы не собираем такие рабочие процессы вручную, мы генерируем их из шаблонов процессов (обозначенных как группы на этой блок-схеме).
Итак, здесь появляется One Ring, платформа конвейерной обработки Spark с очень широкими возможностями настройки, которая упрощает составление и выполнение самого сложного процесса в виде одного большого задания Spark.
И мы только что открыли его исходный код. Возможно, вас заинтересуют подробности.
Давайте поговорим о приложениях Spark. В этом документе объясняется, как использовать...
- One Ring, чтобы объединить их всех,
- One Ring, чтобы объединить их,
- One Ring, чтобы связать их всех
- И облака в которых они обитают
...в параметризованных цепочках.
Каждое приложение в терминах One Ring представляет собой Операцию — объект со своим собственным конфигурационным пространством и потоками входных/выходных данных, описываемый минимальным набором метаданных. Эта абстракция позволяет разработчику гибко составлять сложные технологические конвейеры из набора стандартных подпрограмм без написания дополнительного кода, просто простая конфигурация в DSL. Или даже генерировать очень сложные из более коротких фрагментов шаблона.
Давайте начнем с описания того, как построить и расширить One Ring, затем перейдем к настройке и составлению процесов.
One Ring, чтобы объединить их всех
Чтобы собрать One Ring, вам нужен Apache Maven версии 3.5 или выше.
Убедитесь, что вы клонировали это хранилище со всеми подмодулями:
git clone --recursive https://github.com/PastorGL/OneRing.git
One Ring CLI
Если вы планируете выполнять вычисления в кластере EMR, просто перейдите в каталог OneRing и запустите Maven в профиле по умолчанию:
mvn clean package
Файл ./TaskWrapper/target/one-ring-cli.jar представляет собой исполняемый файл fat JAR, предназначенный для среды Spark, предоставляемой EMR версии 5.23.0.
Если вы планируете создать локальный артефакт с полным встроенным Spark, выполните сборку в "локальном" профиле:
mvn clean package -Plocal
Убедитесь, что результирующий JAR имеет размер около ~ 100 МБ.
Не рекомендуется пропускать тесты в процессе сборки, но если вы запускаете Spark локально на своей машине, вы можете добавить -DskipTests в командную строку Maven, чтобы они вам не мешали.
После того, как вы создали свой артефакт CLI, загляните в "./RESTWrapper/docs" для автоматически сгенерированной документации доступных пакетов и операций (в формате Markdown).
One Ring Dist
Файл ./DistWrapper/target/one-ring-dist.jar это исполняемый файл fat JAR, который генерирует сценарий dist-cp Hadoop или s3-dist-cp EMR для копирования исходных данных из внешнего хранилища (а именно S3) во внутреннюю HDFS кластера и обратно результат вычисления.
Это необязательный компонент, описанный чуть позже.
One Ring REST
Файл ./RESTWrapper/target/one-ring-rest.jar это толстый исполняемый файл JAR, который служит серверной частью REST для еще не реализованного, но очень желанного визуального редактора шаблонов. Он также обслуживает документы через выделенную конечную точку.
One Ring спроектирован с учетом возможности расширения.
Расширение Операций
Чтобы расширить встроенный набор операций One Ring, вы должны реализовать класс операций в соответствии с набором соглашений, описанных в этом документе.
Во-первых, вы должны создать модуль Maven. Поместите его на том же уровне, что и корневой pom.xml , и включите свой модуль в раздел <modules> корневого проекта. Вы можете свободно выбирать понравившиеся вам идентификаторы групп и артефактов.
Чтобы заставить One Ring узнать ваш модуль, включите ссылку на его артефакт в pom.xml Taskwrapper-а как <dependencies>. Чтобы ваш модуль знал One Ring, включите ссылку на артефакт 'ash.nazg:Commons' в <dependencies> вашего модуля (и его область test-jar тоже). Для примера загляните в этот pom.xml .
Теперь вы можете приступить к созданию операционного пакета и описать его.
По соглашению, пакет Operations должен иметь имя your.package.name.operations и иметь package-info.java с комментариями @ash.nazg.config.tdl.Description. Эта аннотация требуется One Ring для распознавания содержимого your.package.name . Вот вам пример.
Если ваш модуль содержит несколько операций, которые используют одни и те же определения параметров, имена этих параметров должны быть помещены в общедоступный конечный класс your.package.name.config.ConfigurationParameters как общедоступные статические конечные строковые константы с одинаковыми аннотациями @Description для каждой. Операция может определять свои собственные параметры внутри своего класса, следуя тому же соглашению.
Определения параметров и константы их значений по умолчанию имеют имена в зависимости от их назначения:
- DS_INPUT_ - для ссылок на входные потоки данных (DataStream),
- DS_OUTPUT_ - для ссылок на выходные потоки данных(DataStream),
- OP_ - для параметра операции,
- DEF_ - для любого значения по умолчанию, а остальная часть имени должна соответствовать соответствующему OP_ или DS_,
- GEN_ - для любого столбца, сгенерированного этой операцией.
Ссылки на столбцы входных потоков данных должны заканчиваться суффиксом _COLUMN, а на списки столбцов - _COLUMNS.
Операция, по сути, представляет собой
public abstract class Operation implements Serializable {
public abstract Map<String, JavaRDDLike> getResult(Map<String, JavaRDDLike> input) throws Exception;
}
...но снабжена избыточными метаданными, которые позволяют One Ring гибко настраивать его и обеспечивать правильность и согласованность всех конфигураций операций в технологической цепочке.
Это зависит от вас, автора, предоставить все эти метаданные. При отсутствии каких-либо требуемых метаданных сборка будет преждевременно завершена ошибкой One Ring Guardian, поэтому неполный класс не приведет к сбою вашей расширенной копии One Ring CLI во время выполнения вашего процесса.
По крайней мере, вы должны реализовать следующие методы:
- абстрактный открытый строковый метод verb(), который возвращает короткое символьное имя для ссылки на ваш экземпляр операции в файле конфигурации, снабженный аннотацией a @Description,
- абстрактный общедоступный TaskDescriptionLanguage(), который определяет все пространство конфигурации операции в TDL2 (Язык описания задачи),
- GetResult(), который содержит точку входа вашего бизнес-кода. В него будут загружены все потоки данных, накопленные текущим процессом в момент вызова вашей операции, и он должен возвращать любые потоки данных, которые должна выдать ваша операция.
Также вы должны переопределить public void setConfig(OperationConfig config), вызывающий исключение InvalidConfigValueException, вызвать его super() в начале, а затем прочитать все параметры из пространства конфигурации в поля вашего класса Operation. Если какой-либо из параметров имеет недопустимое значение, вы обязаны выдать исключение InvalidConfigValueException с описательным сообщением об ошибке конфигурации.
Вам абсолютно необходимо создать тестовый пример для вашей операции. См. Существующие тесты для справки.
Существует множество примеров для изучения, просто загляните в исходный код потомков класса Operation. Для вашего удобства здесь приведен список наиболее заметных из них:
- FilterByDateOperation с большим количеством параметров разных типов, которые имеют значения по умолчанию,
- SplitByDateOperation — его дочерняя операция генерирует множество выходных потоков данных с именами подстановочных знаков,
- DummyOperation — этот должным образом ничего не делает, просто создает псевдонимы для своих входных потоков данных,
- SubtractOperation может потреблять и излучать как RDDs, так и PairRDDs в виде потоков данных,
- WeightedSumOperation генерирует множество столбцов, которые либо берутся из входных потоков данных, либо создаются заново,
- и пакет Proximity содержит операции, которые обрабатывают точечные и полигональные RDD в их потоках данных.
Расширенные Адаптеры для хранения данных
Чтобы расширить One Ring с помощью пользовательского адаптера хранилища, необходимо реализовать интерфейсы InputAdapter и OutputAdapter. Они довольно просты, просто посмотрите существующий пример адаптера.
Например, вы могли бы создать адаптер для файлов Spark "parquet" вместо CSV, если ваши исходные данные хранятся таким образом.
Существует единственное ограничение: вы не можете установить свой адаптер в качестве резервного, так как он зарезервирован для адаптера Hadoop.
Надеюсь, этой информации будет достаточно для начала.
One Ring чтобы связать их
Теперь входим в пространство конфигурации.
Существует специфичный для предметной области язык с именем TDL3, который расшифровывается как One Ring Task Definition Language. (Существуют также DSL с именами TDL1 и TDL2, но они довольно тонкие.)
Объектную модель языка см. в разделе TaskDefinitionLanguage.java . Обратите внимание, что основная форма, предназначенная для использования человеком, - это не JSON, а простой несекционированный файл .ini (или Java .properties). Мы называем этот файл tasks.ini или просто config.
Рекомендуемой практикой является запись ключей в параграфах, сгруппированных для каждой операции, которым предшествуют ее Входные потоки данных, а за ними следуют группы ключей выходных потоков данных.
Слои пространства имен
Как вы могли видеть, каждый ключ начинается с префикса spark.meta.. One Ring может (и сначала пытается) считывать свою конфигурацию непосредственно из контекста Spark, а не только из файла конфигурации, и каждое свойство Spark должно начинаться с spark.prefix. Мы добавляем еще один префикс meta. (по соглашению; это может быть любой уникальный токен по вашему выбору), чтобы отличать наши собственные свойства от свойств Spark. Также один tasks.ini может содержать несколько процессов, если они имеют правильный префикс, просто запустите их ключи с помощью spark.process1_name., spark.another_process. и так далее.
Если вы запускаете One Ring в локальном режиме, вы можете указать свойства через файл .ini и опустить все префиксы. Давайте предположим, что мы удалили все префиксы Spark и теперь смотрим непосредственно на пространства имен ключей.
Конфигурация разделена на несколько пространств имен, и все имена параметров должны быть уникальными в соответствующем пространстве имен. Эти слои различаются, опять же, некоторым префиксом.
Внешние Слои
Первый уровень пространства имен - это distcp из One Ring DistWrapper. который предписывает этой утилите сгенерировать файл сценария для вызовов dist-cp:
distcp.wrap=both
distcp.exe=s3-dist-cp
Давайте обсудим это немного позже. Сам CLI игнорирует все внешние слои.
Переменные
Если ключ или значение содержат токен вида {ALL_CAPS}, он будет обработан CLI как переменная конфигурации и будет заменен значением, предоставленным через командную строку или файл переменных.
ds.input.part_count.signals={PARTS}
Если значение переменной не было указано, замена не будет произведена, если только переменная не содержит для себя значение по умолчанию в форме {ALL_CAPS:любое значение по умолчанию}. Значения по умолчанию могут не содержать символа '}'.
ds.input.part_count.signals={PARTS:50}
Существует несколько других ограничений на значения по умолчанию. Во-первых, каждое вхождение переменной имеет разное значение по умолчанию и не переносит его на всю конфигурацию, поэтому вы должны устанавливать их каждый раз, когда используете эту переменную. Во-вторых, если переменная после замены формирует ссылку на другую переменную, она не будет обрабатываться рекурсивно. Нам не нравится создавать Тьюринг-полную машину, из tasks.ini.
Примечательно, что переменные могут встречаться с любой стороны = в строках tasks.ini, и их количество не ограничено для одной строки и/или конфигурационного файла.
CLI-задача процесса
Следующий уровень - task., и он содержит свойства, которые настраивают сам интерфейс командной строки для текущего процесса в качестве задания Spark или задачи CLI.
task.operations=range_filter,accuracy_filter,h3,timezone,center_mass_1,track_type,type_other,track_type_filter,remove_point_type,iron_glitch,slow_motion,center_mass_2,aqua2,map_by_user,map_tracks_non_pedestrian,map_pedestrian,map_aqua2,count_by_user,count_tracks_non_pedestrian,count_pedestrian,count_aqua2
task.input.sink=signals
task.tee.output=timezoned,tracks_non_pedestrian,pedestrian,aqua2,count_by_user,count_tracks_non_pedestrian,count_pedestrian,count_aqua2
task.operations (обязательно) - это разделенный запятыми список имен операций, которые необходимо выполнить в указанном порядке. Любое их количество, но не менее одного. Имена должны быть уникальными.
task.input.sink (тоже требуется) - это входной приемник. Любой поток данных, упомянутый здесь, рассматривается как поток, полученный из внешнего хранилища, и будет создан адаптерами хранилища CLI (обсуждается позже) для использования операций.
task.tee.output (также требуется) - это Т-коннектор. Любой поток данных, упомянутый здесь, может использоваться операциями как обычно, но также будет перенаправляться адаптерами хранения CLI во внешнее хранилище.
Экземпляры операций
Операции совместно используют слой op., и он имеет довольно много подслоев.
Операция с определенным именем - это определенный класс Java, но мы не любим вызывать операции по полным именам классов и вежливо спрашиваем их, как бы они хотели, чтобы их называли коротким именем.
Итак, вы должны указать такие короткие имена для каждой из ваших операций в цепочке, например:
op.operation.range_filter=rangeFilter
op.operation.accuracy_filter=accuracyFilter
op.operation.h3=h3
op.operation.timezone=timezone
op.operation.center_mass_1=trackCentroidFilter
op.operation.track_type=trackType
op.operation.map_by_user=mapToPair
op.operation.map_pedestrian=mapToPair
op.operation.count_pedestrian=countByKey
op.operation.count_aqua2=countByKey
Вы видите, что у вас может быть любое количество вызовов одного и того же класса операций в вашем процессе, все они будут инициализированы как независимые экземпляры с разными ссылочными именами.
Operation Inputs and Outputs
Теперь мы переходим к операционному пространству имен op. подуровни.
Первый - это op.inputs. это определяет, какие потоки данных операция собирается использовать как именованные. Их имена присваиваются самой операцией внутренне. Кроме того, операция может принять решение об обработке произвольного числа (или даже подстановочных знаков) потоков данных, расположенных в порядке, указанном op.inputs. слое.
Пример конфигурации:
op.inputs.range_filter=signals
op.input.accuracy_filter.signals=range_accurate_signals
op.inputs.h3=accurate_signals
op.inputs.timezone=AG
op.input.center_mass_1.signals=timezoned
op.input.track_type.signals=if_step1
op.inputs.type_other=tracks
Обратите внимание, что опции заканчиваются просто именем операции в случае позиционных вводов или "именем операции" + "." + "ее внутреннее имя ввода" для именованных. Эти уровни являются взаимоисключающими для данной операции.
Все то же самое относится и к op.output. и op.outputs. слоям, описывающим потоки данных, которые собирается создать операция. Примеры:
op.outputs.range_filter=range_accurate_signals
op.output.accuracy_filter.signals=accurate_signals
op.outputs.h3=AG
op.outputs.timezone=timezoned
op.output.center_mass_1.signals=if_step1
op.output.track_type.signals=tracks
op.outputs.type_other=tracks_non_pedestrian
op.output.track_type_filter.signals=pedestrian_typed
Ссылка на поток данных с подстановочным знаком определяется следующим образом:
op.inputs.union=prefix*
Он будет соответствовать всем потокам данных с указанным префиксом, доступным в момент выполнения, и будет автоматически преобразован в список без определенного порядка.
Параметры операций
Следующий подуровень предназначен для определения параметров операции, op.definition.. Имена параметров занимают остальную часть op.definition.. А первый префикс имени параметра - это название Операции, к которой он принадлежит.
Каждое определение параметра передается в CLI самой операцией через интерфейс TDL2 (Язык описания задач), и они строго типизированы. Таким образом, они могут иметь значение любого числа-потомка, строки, перечисления, String[] (в виде списка, разделенного запятыми), и логические типы.
Некоторые параметры могут быть определены как необязательные, и в этом случае они имеют значение по умолчанию.
Некоторые параметры могут быть динамическими, в этом случае они имеют фиксированный префикс и переменное окончание.
Наконец, существует множество параметров, которые конкретно относятся к столбцам входных потоков данных. Их имена должны заканчиваться на .column или .columns по соглашению, а значения должны ссылаться на допустимый столбец или список столбцов или на один из столбцов, сгенерированных операцией. По соглашению сгенерированные имена столбцов начинаются с символа подчеркивания.
Посмотрите на несколько примеров:
op.definition.range_filter.filtering.column=signals.accuracy
op.definition.range_filter.filtering.range=[0 50]
op.definition.h3.hash.level=9
op.definition.timezone.source.timezone.default=GMT
op.definition.timezone.destination.timezone.default={TZ}
op.definition.timezone.source.timestamp.column=AG.timestamp
op.definition.type_other.match.values=car,bike,non_residential,extremely_large
op.definition.track_type_filter.target.type=pedestrian
op.definition.track_type_filter.stop.time=900
op.definition.track_type_filter.upper.boundary.stop=0.05
op.definition.map_pedestrian.key.columns=pedestrian.userid,pedestrian.dow,pedestrian.hour
op.definition.map_aqua2.key.columns=aqua2.userid,aqua2.dow,aqua2.hour
Параметр filering.column операции с именем range_filter указывает на точность столбца из сигналов потока данных, а также source.timestamp.column - это ссылка на временную метку столбца AG. И ключ map_pedestrian. ссылается на список столбцов для пешеходов.
Параметр hash.level для h3 имеет тип Byte, значение match.values для type_other равно String[], а значение upper.boundary.stop для track_type_filter равно Double.
Чтобы установить необязательному параметру значение по умолчанию, вы можете вообще опустить этот ключ или, если вам нравится полнота, закомментировать его:
op.definition.another_h3.hash.level=9
Для получения исчерпывающей таблицы параметров каждой операции найдите документы в вашем каталоге RESTWrapper/docs (при условии, что вы успешно создали проект, в противном случае он будет пустым).
Параметры потоков данных
Следующий уровень - это ds. пространство имен конфигурации потоков данных и его правила совершенно разные.
Во-первых, потоки данных всегда типизированные. Существуют различные типы:
- CSV (текстовый RDD на основе столбцов со свободно определенными, но строго привязанными столбцами)
- Fixed (CSV, но порядок и формат столбцов считаются фиксированными)
- Point (объектно-ориентированный, содержит координаты точек с метаданными)
- Polygon (объектно-ориентированный, содержит контуры полигонов с метаданными)
- KeyValue (RDD с непрозрачным ключом и значением на основе столбцов, таким как CSV)
- Plain (RDD генерируется CLI как просто непрозрачный текст Hadoop, или это может быть пользовательский типизированный RDD, обрабатываемый операцией)
Каждый поток данных может быть сконфигурирован как входной сигнал для ряда операций и как выходной сигнал только для одной из них.
Имя потока данных всегда является последней частью любого ds. . И набор параметров потока данных фиксирован.
ds.input.path. ключи должны указывать на некоторые абстрактные пути для всех потоков данных, перечисленных в task.input.sink. Формат пути всегда должен включать спецификацию протокола и проверяться адаптером хранилища CLI (Адаптеры обсуждаются в последнем разделе этого документа).
Например, для потока данных с именем "signals" существует путь, распознанный прямым адаптером S3:
ds.input.path.signals=s3d://{BUCKET_NAME}/key/name/with/{a,the}/mask*.spec.?
Обратите внимание на использование глобальных выражений. токен '{a, the}' не будет обрабатываться как переменная, но он будет расширен до списка каталогов 'a' и 'the' внутри каталога '/key/name/with' с помощью адаптера.
То же самое верно и для ds.output.path. ключи, которые должны быть указаны для всех потоков данных, перечисленных в разделе ключ task.tee.output. Позвольте перенаправить поток данных "scores" в локальную файловую систему:
ds.output.path.scores={OUTPUT_PATH:file:/tmp/testing}/scores
Но здесь вы можете схитрить. По умолчанию используются клавиши all-input и all-output:
ds.input.path=jdbc:SELECT * FROM scheme.
ds.output.path=aero:output/
В этом случае для каждого потока данных, который не имеет своего собственного пути, его имя будет добавлено в конец соответствующего значения ключевого слова без разделителя. Мы не рекомендуем использовать эти чит-ключи в производственной среде.
ds.input.columns. и ds.output.columns. слои определяют столбцы для потоков данных на основе столбцов или свойства метаданных для потоков данных на основе объектов. Имена столбцов должны быть уникальными для этого конкретного потока данных.
Выходные столбцы всегда должны ссылаться на допустимые столбцы входных данных, переданных Операции, которая генерирует указанный поток данных, или на его сгенерированные столбцы (имена которых начинаются с подчеркивания).
Список входных столбцов просто присваивает новые имена столбцам для всех потребляющих операций. Он может содержать один символ подчеркивания вместо имени какого-либо столбца, чтобы сделать этот столбец анонимным. В любом случае, если столбец является "анонимным", на него все равно можно ссылаться по его номеру, начинающемуся с _1_.
Существует исчерпывающий пример всех правил определения столбцов:
ds.input.columns.signals=userid,lat,lon,accuracy,idtype,timestamp
ds.output.columns.AG=accurate_signals.userid,accurate_signals.lat,accurate_signals.lon,accurate_signals.accuracy,accurate_signals.idtype,accurate_signals.timestamp,_hash
ds.input.columns.AG=userid,lat,lon,accuracy,idtype,timestamp,gid
ds.output.columns.timezoned=AG.userid,AG.lat,AG.lon,AG.accuracy,AG.idtype,AG.timestamp,_output_date,_output_year_int,_output_month_int,_output_dow_int,_output_day_int,_output_hour_int,_output_minute_int,AG.gid
ds.input.columns.timezoned=userid,lat,lon,accuracy,idtype,timestamp,date,year,month,dow,day,hour,minute,gid
ds.output.columns.tracks=if_step1.userid,if_step1.lat,if_step1.lon,if_step1.accuracy,_velocity,if_step1.timestamp,if_step1.date,if_step1.year,if_step1.month,if_step1.dow,if_step1.day,if_step1.hour,if_step1.minute,if_step1.gid,_track_type
ds.input.columns.tracks=userid,lat,lon,_,_,_,_,_,_,_,_,_,_,_,track_type
ds.output.columns.pedestrian_typed=if_step1.userid,if_step1.lat,if_step1.lon,if_step1.accuracy,if_step1.velocity,if_step1.timestamp,if_step1.date,if_step1.year,if_step1.month,if_step1.dow,if_step1.day,if_step1.hour,if_step1.minute,if_step1.gid,_point_type
ds.input.columns.pedestrian_typed=_,_,_,_,_,_,_,_,_,_,_,_,_,_,point_type
ds.output.columns.pedestrian=pedestrian_typed._1_,pedestrian_typed._2_,pedestrian_typed._3_,pedestrian_typed._4_,pedestrian_typed._5_,pedestrian_typed._6_,pedestrian_typed._7_,pedestrian_typed._8_,pedestrian_typed._9_,pedestrian_typed._10_,pedestrian_typed._11_,pedestrian_typed._12_,pedestrian_typed._13_,pedestrian_typed._14_
ds.input.columns.pedestrian=userid,lat,lon,_,_,timestamp,_,_,_,_,_,_,_,_
В разновидностях потоков данных CSV столбцы разделяются символом-разделителем, поэтому существуют ds.input.separator. и ds.output.separator. вместе с ключами ds.input.separator и ds.output.separator устанавливаются глобально. Суперглобальным значением разделителя столбцов по умолчанию является символ табуляции (TAB, 0x09).
Последний ds. уровни управляют разделением потока данных, лежащего в основе RDDS, а именно, ds.input.part_count. и ds.output.part_count.. Это очень важно, потому что единственным сверхглобальным значением по умолчанию для количества частей всегда является 1 (одна), и никакие варианты не допускаются. Вы всегда должны устанавливать их по крайней мере для начальных входных потоков данных из task.input.sink и настроить разделение процесса в соответствии с дальнейшим ходом выполнения Задачи.
Если указаны оба part_count. для некоторого промежуточного потока данных, он будет перераспределен сначала на выходной (сразу после операции, которая его сгенерировала), а затем на входной (перед подачей его в первую потребляющую операцию). Пожалуйста, имейте это в виду.
Адаптеры для хранения данных
Входные потоки данных всего процесса поступают из внешнего мира, а выходные потоки данных хранятся где-то снаружи. CLI выполняет эту работу с помощью своих адаптеров хранения.
В настоящее время реализованы следующие адаптеры хранения:
- Hadoop (запасной вариант, использует все протоколы, доступные в вашей среде Spark, т.е. 'file:', 's3:')
- HDFS (тот же Hadoop, но только для протокола 'hdfs:')
- S3 Direct (любое хранилище, совместимое с S3, с протоколом 's3d:')
- Aerospike ('aero:')
- JDBC ('jdbc:')
Резервный адаптер Hadoop вызывается тогда и только тогда, когда другой адаптер не распознает протокол пути, поэтому приоритет протокола 'hdfs:' выше, чем у других, поставляемых платформой.
Адаптеры хранения совместно используют два одноименных уровня ввода/вывода, и все их параметры являются глобальными.
Адаптер Hadoop не имеет явных параметров. Как и адаптер HDFS.
S3 Direct использует стандартный клиентский поставщик Amazon S3 и имеет только параметр для вывода:
- output.content.type с значением по умолчанию "text/csv"
Параметры адаптера JDBC следующие:
- input.jdbc.driver и output.jdbc.driver для получения полных имен классов драйверов, доступных в пути к классу. Без значений по умолчанию.
- input.jdbc.url и output.jdbc.url для URL-адресов подключений. Без значений по умолчанию.
- input.jdbc.user и output.jdbc.user без значений.
- input.jdbc.password и output.jdbc.password без значений.
- output.jdbc.batch.size для размера выходного пакета значение по умолчанию равно "500".
Параметры адаптера Aerospike следующие:
- input.aerospike.host и output.aerospike.host по умолчанию используется значение 'localhost'.
- input.aerospike.port и output.aerospike.port значение по умолчанию равно '3000'.
На этом завершается настройка интерфейса командной строки для одиночного процесса One Ring. После того как вы соберете библиотеку базовых процессов, вам, возможно, захочется узнать, как объединить их в более крупные рабочие процессы.
One Ring чтобы объединить их
В интерфейсе командной строки есть утилита для объединения двух или более шаблонов процесса One Ring в один более крупный шаблон.
Это действие является окончательным и должно выполняться только тогда, когда конвейер всех участвующих процессов полностью установлен, поскольку оно искажает большинство именованных объектов из составных файлов tasks.ini и выдает гораздо менее читаемую конфигурацию.
Искажение имен необходимо, потому что tasks.ini из разных процессов могут содержать операции и потоки данных с одинаковыми именами, и мы хотим избежать конфликтов ссылок. Однако потоки данных могут сохранять свои имена и переносить результирующую конфигурацию.
Вызов Composer из командной строки выглядит следующим образом (также доступен через REST):
java -cp ./TaskWrapper/target/one-ring-cli.jar ash.nazg.composer.Composer -X spark.meta -C "/path/to/process1.ini=alias1,/path/to/process2.ini=alias2" -o /path/to/process1and2.ini -M /path/to/mapping.file -v /path/to/variables.file -F
-C параметр представляет собой список пар путь к файлам конфигурации=псевдоним, разделенных запятой. Порядок операций в результирующей конфигурации соответствует порядку этого списка. Исходные конфигурации могут быть в форматах .ini и JSON и даже свободно смешиваться, просто используйте .расширение json для конфигураций JSON.
-X перечисляет префиксы задач, если они присутствуют. Если каждый из них отличается, укажите их все в списке, разделенном запятыми. Если все они одинаковы, укажите их только один раз. Если префиксов нет, просто опустите этот переключатель.
-V то же, что и CLI: пары переменных name=value для всех конфигураций, разделенные новой строкой и закодированные в Base64.
-v то же, что и CLI: путь к файлу переменных, пары имя=значение в каждой строке.
-M путь к файлу сопоставления потоков данных, используемому для передачи потоков данных от одного процесса к другому (процессам).
Синтаксис этого файла выглядит следующим образом:
alias1.name1 alias2.name1
alias1.name2 alias2.name5 alias3.name8
Первая строка этого примера означает, что поток данных 'name1' из процесса 'alias2' будет заменен потоком данных 'name1' из 'alias1' и сохранит 'name1' в результирующей конфигурации. Вторая строка заменяет 'name5' в 'alias2' и 'name8' в 'alias3' на 'name2' из 'alias1' и сохраняет 'name2' во всей объединенной конфигурации. Итак, принцип прост: если вы хотите объединить несколько потоков данных из разных процессов, сначала поместите основной, а затем перечислите потоки данных, подлежащие замене.
-o путь к составленному выходному конфигурационному файлу, по умолчанию в формате .ini. Для использования вывода JSON .расширение json.
-F выполните полное составление, если задан этот переключатель. Результирующий task.tee.outputs будет содержать только те же выходные данные, что и самая последняя конфигурация в цепочке, в противном случае он будет содержать выходные данные всех объединенных задач.
И облака в которых они обитают
Существует два поддерживаемых способа выполнения задач One Ring. Всегда лучше начинать с локального режима, отлаживать весь процесс на небольших проверенных наборах данных, а затем перемещать его в облако.
Локальное выполнение
После того, как вы составили конфигурацию процесса, вам определенно следует протестировать ее локально с небольшой, но достаточно репрезентативной выборкой ваших исходных данных. Гораздо проще отлаживать новый процесс локально, а не в реальном кластере.
После того, как вы создали локальный артефакт, как описано выше, назовите его следующим образом:
java -jar ./RestWrapper/target/one-ring-cli.jar -c /path/to/tasks.ini -l -m 6g -x spark.meta -S /path/to/dist_interface.file
-c задает путь к tasks.ini.
-l означает локальный режим выполнения контекста Spark ('local[*]', если быть точным).
-m задает объем оперативной памяти, например "4g" или "512m".
-x задает префикс текущей задачи, если это необходимо. Если вы планируете передавать tasks.ini в свой кластер через контекст Spark, вам также следует использовать tasks.ini с префиксом локально.
-S для взаимодействия с One Ring Dist, обсуждаемым немного далее.
Также вы должны передать все входные и выходные пути через переменные, чтобы облегчить переход между хранилищем вашей локальной файловой системы и хранилищем кластера.
Например, предположим, что ваш процесс имеет два исходных набора данных и один результат, хранящиеся по путям, указанным переменными SOURCE_SIGNALS, SOURCE_POIS и OUTPUT_SCORES. Просто подготовьте разделенный новой строкой список пар имя = значение из них, и затем у вас есть два способа передать их в один кольцевой интерфейс командной строки:
- Закодируйте как строку Base64 и передайте с помощью ключа командной строки -V
- Поместите в файл (или другое хранилище, поддерживаемое адаптером) и передайте его путь с помощью клавиши командной строки -v
Если указаны оба ключа, -V имеет более высокий приоритет, и -v будет проигнорирован.
Например,
cat > /path/to/variables.ini
SIGNALS_PATH=file:/path/to/signals
POIS_PATH=file:/path/to/pois
OUTPUT_PATH=file:/path/to/output
^D
base64 -w0 < /path/to/variables.ini
U0lHTkFMU19QQVRIPWZpbGU6L3BhdGgvdG8vc2lnbmFscwpQT0lTX1BBVEg9ZmlsZTovcGF0aC90by9wb2lzCk9VVFBVVF9QQVRIPWZpbGU6L3BhdGgvdG8vb3V0cHV0Cg==
java -jar ./RestWrapper/target/one-ring-cli.jar -c /path/to/tasks.ini -l -m 6g -V U0lHTkFMU19QQVRIPWZpbGU6L3BhdGgvdG8vc2lnbmFscwpQT0lTX1BBVEg9ZmlsZTovcGF0aC90by9wb2lzCk9VVFBVVF9QQVRIPWZpbGU6L3BhdGgvdG8vb3V0cHV0Cg==
java -jar ./RestWrapper/target/one-ring-cli.jar -c /path/to/tasks.ini -l -m 6g -v /path/to/variables.ini
Вы увидите много выходных данных Spark, а также дамп вашей задачи. Если все пройдет успешно, вы не увидите никаких исключений в этом выводе. Если нет, внимательно прочитайте сообщения об исключениях и исправьте свой tasks.ini и /или проверьте исходные файлы данных.
Выполнение в вычислительном кластере
One Ring официально поддерживается выполнение на кластерах EMR Spark с помощью сборок непрерывного развертывания TeamCity, но его можно относительно легко адаптировать для других облаков, служб непрерывной интеграции и сценариев автоматизации.
Мы предполагаем, что вы уже знакомы с AWS и имеете экземпляр утилиты EC2 в этом облаке. Возможно, вам придется или не придется настраивать TeamCity или какую-либо другую службу CI по вашему усмотрению на этом экземпляре. Хотя нам нравится, когда все автоматизировано.
Во-первых, вам необходимо настроить некоторую дополнительную среду на экземпляре утилиты, начиная с последней версии PowerShell (требуется, по крайней мере, версия 6) и AWS Tools для PowerShell. Пожалуйста, следуйте официальной документации AWS и зарегистрируйте свой ключ доступа к AWS API с помощью этих инструментов.
Получите сценарии и шаблон развертывания CloudFormation:
git clone https://github.com/PastorGL/one-ring-emr.git
Также получите шаблон конфигурационных файлов:
git clone https://github.com/PastorGL/one-ring-emr-settings.git
И есть конфигурации TC, которые вы можете импортировать в свой TC:
git clone https://github.com/PastorGL/one-ring-tc-builds.git
Не забудьте настроить корни VCS и всегда используйте свою собственную частную копию one-ring-emr-settings, потому что туда будут отправлены самые конфиденциальные данные. В случае другой службы CI вы можете извлечь шаги сборки из XML-файлов TC. Их структура довольно проста, просто покопайтесь в них.
Среда, созданная конфигурациями сборки, представляет собой каталог, в котором содержимое one-ring-emr дополняется добавлением one-ring-emr-settings и артефактов One Ring one-ring-cli.jar и one-ring-dist.jar , так что это выглядит следующим образом (вы также можете использовать символические ссылки, чтобы поместить их в вручную):
/common
/presets
/settings
one-ring-cli.jar
one-ring-dist.jar
create-cluster.ps1
list-jobs.ps1
preset-params.ps1
remove-cluster.ps1
run-job.ps1
set-params.ps1
cluster.template
Вы помещаете свой tasks.ini в подкаталог /settings вместе с другими файлами .ini. Кроме того, вы должны заполнить все необходимые значения во всех файлах .ini внутри этого каталога, которые соответствуют среде вашей учетной записи AWS.
Обычно мы помещаем предварительные настройки для всех наших процессов в разные ветви нашей копии, если репозиторий one-ring-emr-settings, и просто переключаемся на требуемую ветвь этого репозитория для конфигурации сборки каждого процесса.
Этапы сборки выполняются в следующем порядке:
- Запрашивать переменные в пользовательском интерфейсе TC
- preset-params.ps1
- set-params.ps1
- create-cluster.ps1
- Кодирование переменных в Base64
- run-job.ps1
- remove-cluster.ps1
Давайте объясним, что делает каждый шаг.
TC имеет функцию для определения "параметров конфигурации сборки" и предоставляет пользовательский интерфейс для их установки во время выполнения сборки (вместе с соответствующими методами REST). Мы используем эти параметры сборки для установки переменных в нашем шаблоне процесса и запрашиваем у пользователя их значения. Также мы запрашиваем любые дополнительные параметры, специфичные для среды, например, для предустановки размера кластера.
На следующем шаге мы выбираем один из четырех пресетов размера кластера из каталога /preset (файлы S, M, L, XL .ini), если он был выбран на предыдущем шаге, и помещаем его содержимое в параметры сборки.
set-params.ps1 имеет возможность переопределить любую строку любого существующего файла .ini из подкаталога /settings, заменив ее пользовательским параметром сборки с именем 'filename.ini' + '.' + 'parameter.name ', что дает вам еще один уровень гибкости параметризации сборки. Этот скрипт перезаписывает файлы .ini с этими параметрами, поэтому все последующие скрипты получают расширенные конфигурации.
На следующем шаге мы создаем искровой кластер в EMR, развертывая шаблон CloudFormation, дополненный всеми параметрами, собранными на данный момент, и параметрами из /settings/create.ini.
Затем мы кодируем переменные с помощью Base64, точно так же, как мы это делали в локальном режиме.
На данный момент все готово для запуска процесса в кластере. run-job.ini настраивает всю необходимую среду (из файлов .ini компонентов из папки "/settings"), вызывает метод Livy REST в кластере и ожидает завершения. Если tasks.ini содержит более одной задачи, все они будут выполняться в порядке определения. Его собственные параметры задаются в /settings/run.ini.
Даже если какой-либо из предыдущих шагов завершится неудачей, следует вызвать remove-cluster.ps1. Этот скрипт выполняет очистку и управляется /settings/remove.ini.
Все сценарии, работающие с кластером, также совместно используют параметры из глобального файла /settings/aws.ini.
Можно выполнить каждый сценарий PowerShell в интерактивном режиме и вручную копировать и вставлять их выходные переменные между шагами с помощью параметров командной строки. Возможно, будет полезно ознакомиться с этим материалом, прежде чем переходить на полную автоматизацию.
Мы также обычно переходим на более высокий уровень автоматизации и ставим сборки TC в очередь с помощью их REST API.
В любом случае, внимательно следите за своими консолями CloudFormation, EMR и EC2, по крайней мере, в течение нескольких первых попыток. Могут быть недостаточные права доступа и множество других проблем, но мы предполагаем, что вы уже имеете опыт работы с AWS и EMR, если вы здесь.
И если да, то вы уже знаете, что хранилище объектов S3 не слишком хорошо подходит для Spark из-за его архитектурных особенностей, таких как "конечная согласованность" и зависимость времени отклика от количества объектов в корзине. Чтобы избежать ошибок тайм-аута, рекомендуется всегда копировать исходные данные из S3 в HDFS в кластере перед вызовом Spark и, наоборот, копировать результат обратно из HDFS в S3 после его вычисления.
EMR предоставляет утилиту с именем s3-dist-cp, но ее использование является громоздким, поскольку вы должны знать точные пути.
One Ring предоставляет оболочку Dist для автоматизации обработки s3-dist-cp, фокусируясь на конфигурации вашей задачи, поэтому вы все равно можете использовать переменные для исходных путей и динамически генерировать пути к результатам, не утруждая себя командной строкой s3-dist-cp.
One Ring Dist также можно использовать с другими вариантами dist-cp, если это требуется вашей средой.
Вызов One Ring Dist
Синтаксис аналогичен CLI:
java -jar ./DistWrapper/target/one-ring-dist.jar -c /path/to/tasks.ini -o /path/to/call_distcp.sh -S /path/to/dist_interface.file -d DIRECTION -x spark.meta
-c, -x, -v/-V переключатели имеют то же значение для Dist, что и для CLI.
-d задает направление процесса копирования:
- 'from' чтобы скопировать исходные данные из S3 в HDFS,
- 'to' чтобы скопировать результат обратно.
-S указывает путь к файлу интерфейса со списком путей HDFS выходных данных задачи, сгенерированных CLI.
-o это путь, по которому выводится скрипт с полными командами s3-dist-cp.
Конфигурация Dist
Dist имеет свой собственный слой в tasks.ini с префиксом distcp., с небольшим набором ключей.
distcp.exe указывает, какой исполняемый файл следует использовать. По умолчанию он имеет значение 's3-dist-cp'.
distcp.direction задает, какие операции копирования подразумеваются для выполнения. В дополнение к переключателям -d 'from' и 'to' существуют:
- 'both' для указания копии в обоих направлениях требуется,
- 'nop' (по умолчанию) для подавления копирования.
Логическое значение distcp.move указывает на удаление файлов после копирования. По умолчанию для него установлено значение true.
distcp.dir.to и distcp.dir.from указывают, какие пути к HDFS должны использоваться для хранения файлов, собранных из HDFS, и для результатов соответственно, со значениями по умолчанию '/input' и '/output'. Подкаталоги, названные в честь потоков данных, будут автоматически созданы для их файлов по этим путям.
distcp.store и distcp.ini указывают другой способ установки значений -S и -o (но переключатели командной строки всегда имеют более высокий приоритет).
Использование Dist
Когда CLI встречает директиву distcp.direction в конфигурации, она прозрачно заменяет все свои входные и выходные пути S3 путями HDFS в соответствии с предоставленным направлением.
Это полезно для многопроцессорных задач. Если выходные данные первой задачи хранятся в HDFS, это позволяет следующим задачам использовать их без обратного перехода к S3, сохраняя при этом пути, указывающие на S3:
spark.task1.distcp.direction=to
spark.task2.distcp.direction=nop
spark.task3.distcp.direction=from
... и если та же задача выполняется в одиночку, она должна просто использовать двунаправленную копию:
spark.task1.distcp.direction=both
...без дальнейших изменений переменных пути и других параметров конфигурации.
Для любого потока данных, который отправляется в distcp.dir. из CLI, добавляется строка с результирующим путем HDFS к файлу интерфейса Dist (в разделе distcp.store / -S path). Это позволяет Dist собирать их и генерировать команды для направления "from".
На самом деле вы никогда не должны вызывать Dist вручную, это задача сценариев автоматизации - вызывать его до и после выполнения CLI.
Присоединяйтесь к Сообществу
Если вы хотите внести свой вклад, пожалуйста, сначала ознакомьтесь со списком вопросов One Ring.
Проблема для вашей наиболее желаемой функции, возможно, уже была создана кем-то, но если это не так, вы можете создать ее самостоятельно. Не прикрепляйте никаких назначенцев, ярлыков, проектов и так далее, просто предоставьте подробное объяснение его варианта использования и напишите простую начальную спецификацию.
Если у вас есть лишнее время и вы просто хотите что—то закодировать, вы можете выбрать проблему с пометкой "Требуется помощь", "Список пожеланий" и присвоить приоритет - один из приоритетов ('Px'). метки. Существуют ярлыки "Хорошо для решения" и "Хорошая первая проблема", которые обозначают сложность проблемы. Просто назначьте его себе и запросите полную спецификацию, если она еще не существует.
Не выбирайте проблемы, помеченные как "Рекомендуется соблюдать осторожность", если вы действительно не знакомы со всей кодовой базой One Ring.
Обратите внимание, что One Ring имеет свой стиль кода. Ваши материалы должны строго соответствовать используемым нами шаблонам кодирования, чтобы они не казались чужеродными.
Убедитесь, что ваши запросы на извлечение не затрагивают ничего, выходящего за рамки проблемы, и не добавляйте и не изменяйте версии каких-либо внешних зависимостей. По крайней мере, обсудите эти темы с авторами, прежде чем вносить свой вклад.
Мы не будем принимать никакой код, который был заимствован из любых источников, несовместимых по лицензии. У нас новая BSD с оговоркой "Не делай зла". Только не используй One Ring в качестве оружия, хорошо?
У этого проекта нет Кодекса поведения и никогда не будет. Вы можете быть сколь угодно саркастичным, но оставайтесь вежливым и никого не тролльте, если не хотите, чтобы вас троллили в ответ.
Счастливого проектирования данных!