Всё началось с того, что месяц назад я купил rtx3060 вместо 1050ti. Жаба душила, но посовещавщись с наставником понял, что видеокарта ещё много, когда пригодится(на этом и следующем семестрах), а видеопамяти на старой не хватало, чтобы делать семинары по время занятий по cv/nlp. За это время доллар аномально упал, видекарты подешевели. Если кто-то ещё планирует - сейчас может быть удачное время.
Например, есть тут можно купить у китайского продавца за 50к но это озон глобал. Гарантий не будет, да и я не уверен, что видеокарта будет действительно новой. Или можно заказать на onlinetrade, но цена уже 66к.
Сорри за рекламу, но без этого лучшую модель у меня бы обучить не получилось:)
Теперь что касается модели.
Этап 1
- Первая из идей, которая сработала - увеличения кропа картинки до того размера, на каком обучалась изначальная сеть. Сейчас я уже понимаю, что это не так принципиально(именно чтобы размеры полностью совпадали), так что размер картинки - гиперпараметр, который можно подбирать. Однако при увеличении размера картинки, обратно пропорционально квадрату падает и размер батча, который используется при обучении. Вообще есть много разных исследований на эту тему, но об этом попозже.
- Выбор размера модели. Чем больше модель, тем больше фичей она способна найти, но размер батча падает, т.е. градиент становится более шумным и хуже работают нормализации. Остановился на ResNet34. Экспериментировал и с другуми архитектурами, пытался обучать модели из секции EfficentNet и RegNet_x. Но никакого профита не дало.
- Шедулер. На первый взляд ReduceOnPlato - лучшее изобретение человечества, поэтому я им с радостью воспользовался.
- Агументации. Пытался прикрутить albumentations, но возникли проблемы с keypoints. В итоге пришёл к идее, что агументации картинки и ключевых точек надо разделять. А ещё у меня пропадала часть точек. Поэтому я очень обрадовался, когда Саит Шарипов выложил очень похожую идею, но уже с рабочим кодом, которым можно было воспользоваться, заодно решил позаимстовать и список аугментаций, совместив его со своим(в частности, добавились чёрные квадраты). Правда из коробки не работало зеркальное отражение, т.к. метки классов ехали, пришлось исправлять. Плюс у меня ещё была куча других агументаций.
- Лосс - L1 по советам Ирины Лапенко
И в итоге.. 20-30 баллов. Была проделана куча экспериментов, но без толку. Добавлял ещё аугментаций, тестировал масштабы, застрял:(
Этап 2
- По советам Ирины Лапенко, я убрал принудительное преобразование предсказаний к int
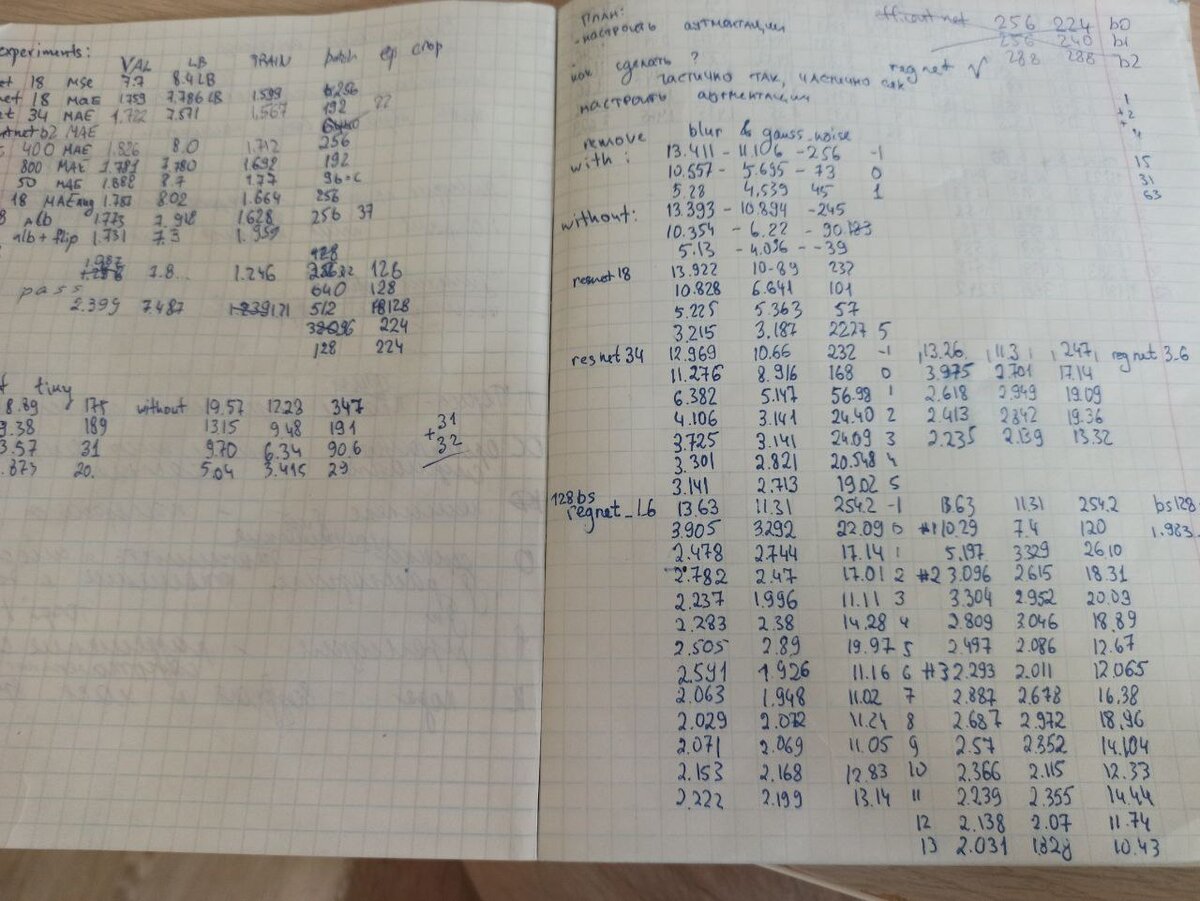
- Аугментации забирают много времени, причём мониторя загрузку компьютера, я увидел, что и видеоркарта и cpu загружены на 100%. Основная причина - аугментации происходят на cpu. Перемещать их я не стал, зато обнаружилось, что у нас лосс считается на cpu. Трансфер данных между устройствами это всегда задержки, да и процессору и так плохо. Перенес рассёт лосса на gpu, мой процессор ожил, нагрузка спала со 100%, и модели стали обучаться быстрее. Аугментации всё равно тормозят работу модели, поэтому скорость обучения resnet18 и resnet34 вообще не отличаются. Нашёл, что оптимальный размер модели - около resnet50.
- Пытаясь понять, что не так с моделью, я решил - может быть добавление огромного числа аугментаций не есть хорошая идея? Мы же работаем с человеческими лицами, вряд ли изменение цветовой гаммы поможет нам повысить качество модели на тестовом датасете. В итоге я написал визуализатор изображения после всех мастштабирований и аффинных преобразований. Остановился на таком наборе:

- Растяжения не использовал, т.к. лица при фотографиях не растягиваются, движения кроме поворотов тоже не нужны, т.к. в нашем датасете все фотографии достаточно хорошо центрированы.
- Блюры, гауссовские шумы т.д. я тоже убрал, т.к. в тестовом датасете ничего похожего нет, а размытия, например, могут ухудшить именно момент обучения сети, т.к. оно становится более шумным.
- От теней, соляриции и других погодных эффектов тоже нет толку, погода всегда хорошая:)
- Мне показалось, что итоговый набор хорошо обощает тренировочную выборку, но при этом, теоретически все эти изображения мы можем встретить и в тесте.
- По сравнению с агументациями Саида Шарипова я уменьшил угол поворота и сделал меньшие размеры чёрных квадратов, т.к. на каких-то изображениях они закрывали слишком много.
- Следующий большой шаг - это настройка обучения. Я наткнулся на хорошую визуализацию различных шедулеров на kaggle. В процессе поиска информации о том, какой из них лучше, также нашёл, что их можно вызывать и внутри одной эпохи. При большом количестве аугментаций и небольших батчах, в том случае если в конце эпохи у нас будет высокий learning rate, то мы в резульате никогда не получим хорошую модель. А в начале эпохи хотелось, чтобы модель наоборот быстро училась. Под подобную концепцию лучше всего подходил CosineAnnealingWarmRestarts
- Также хотел попробовать и CyclicLR - triangular2, однако мне не понравилось, что своего максимума он достигает посреди эпохи. Решил всё-таки остановиться на первом, с учётом растяжения в 2 раза. Поэтому число эпох для обучения модели выбирал, как 2**n - 1
- В самом начале контеста я увидел, что модель показывает большой лосс, поэтому использовал старт с learning_rate==0.01. Мне казалось, что так модель быстрее приспособится от задачи классификации к задаче регрессии. Однако, увидел пост Игоря Иткина, о том, что он снижает свой лосс во время обучения, начиная с 1e-3 до 1e-5. Подумав, тоже его уменьшил. После теста оказалось, что модель приспосабливается не медленнее, чем с более высоким значением шага. Объяснил это для себя тем, что вероятно высокий лосс в итоге сбивает предобученные веса и теряется часть смысла transfer learningа.
Итого ResNet50 обученый с batch size 128 после 31 эпохи выдал мне 5.57 (или 5.01 private) паблик лидерборда и 40+ баллов. Дальше уже шёл поиск архитектуры. Снова.
- Серия моделей EfficentNet не зашла. Напомню, что эти модели оптимизированы под размер исходного кропа изображения. А сильно увеличивая этот размер, терялось очень много в размере батча.
- RegNet_y. Ссылка на статью с medium. Если говорить коротко, то авторы серии моделей RegNet говорят, что масштаба 224 на 224 достаточно. Они берут обычный ResNet Block и его гиперпараметры. Потом они эти блоки конкатенируют и получают пространство моделей. В итоге для каждой модели можно вычислить её производительность(если я не путаю) во флопах. Они для разных бенчмарков выбирали подходящие под них модели, в частности производительность ResNet50 около 4 Flop. И для всех моделей +- 4 флопа они выбирали наилучшую. Так получается RegNet_x. Серия моделей RegNet_y - тоже самое, но уже с добавлением SE. На HuggingFace есть RegNet_v и RegNet_z, которые использую какие-то фичи от трансформеров, но я не экспериментировал. В итоге модель RegNet_y_3_2 уже позволила набрать 50 баллов. Тоже 31 эпоха и batch_size 128. (или 4.79627 private & 4.97552 public)
- ConvNext - это SoTA модель на 2022. В 2020-2021 был бум Vision Transformers, которые оставили свёрточные модели не у дел. Прежде всего в задачах классификации. Однако новомодные транформеры уступали в задачах детектирования и сегментации. В Майкрософте решили, почему бы не попробовать скрестить модели, добавив всё хорошее к трансформерам и получили модель SWIN. Авторы этой же идеи поступили ровно наоборот - они добавили фишки транформеров, конкретно этого свина (но без аттеншена) к свёрточным сетям. Советую почитать статью. Там подброно описывается вся эволюция от ResNet к СonvNext. Эта модель является и SoTA в Transfer Learing, но у меня категорически не зашло(на уровне ResNet). Возможно одна из причин - это LayerNorm. В частности эта нормализация используется и в дефолтном классификаторе. Данная нормализация способствует потере информации в задачах регрессии(не проверено, увидел на StackOverFlow). А отказаться от неё тоже идея не самая хорошая, т.к. прошлы слои уже "привыкли" к тому, что данные будут нормализованы.
Как итог я вернулся к RegNet_y_8G. Время было, 50 баллов уже есть, поэтому я подобрал batch_size, чтобы видеопамять была забита(80). И вместо 31 эпохи добавил ещё один рестарт шедулера. Стало 63 эпохи. Обучалась модель 10 часов и показала на Private лидерборде 4.38570. Что уже топ-2. По советам в чатике, также чуть-чуть сблендил предсказания с RegNet_3_2 с весами 6:4 и получил 4.13403