Использовать Guid.NewGuid() в качестве первичного ключа в базе данных — плохая с точки зрения производительности идея. Это связано с тем, что в SQL Server, MySQL и некоторых других БД для первичных ключей создаются кластерные индексы, которые определяют, как строки будут храниться на диске. GUID — это по сути случайное значение, поэтому новая строка может попасть в начало, середину или конец таблицы. Серверу БД в этом случае придётся перемещать другие строки, что приведёт к фрагментации данных, а их извлечение может занять больше времени, если вам нужно извлечь несколько добавленных последовательно записей (например, когда вы добавляете набор связанных сущностей, которые потом будут извлекаться вместе — БД понадобится прочитать данные из разрозненных страниц вместо последовательного чтения набора данных).
Поэтому, чаще всего, лучше пользоваться сгенерированными БД первичными ключами. В SQL Server, например, есть функция NEWSEQUENTIALID(), которая генерирует последовательные GUIDы. Зачем может понадобиться генерировать ключи именно на клиенте и как это правильно сделать?
Проблема
Для создания первичных ключей сущности большинство людей прибегают к одному из следующих подходов:
- Использование в качестве первичного ключа int и генерация таких ключей базой данных при вставке новой строки.
- Использование GUID и опции генерации на уровне БД.
- Самостоятельная генерация GUID в своём приложении и вставка строки с этим идентификатором.
Чтобы дать немного контекста и выяснить, почему вам могут понадобиться последовательные GUID, рассмотрим плюсы и минусы каждого из вышеперечисленных подходов к созданию первичных ключей.
Генерируемый БД Integer в качестве идентификатора
Первый вариант, позволяющий базе данных автоматически генерировать целочисленный первичный ключ, является очень заманчивым подходом; долгое время, особенно в монолитных системах, это было подходом по умолчанию, который удобно интегрировался с ORM. Одна из его приятных особенностей — первичные ключи получают красивые, монотонно возрастающие (и обычно последовательные) идентификаторы.
Это упрощает работу с тестовыми данными и поддержку, когда идентификаторы используюстя в URL-адресах: можно запомнить ID нужной сущности, быстро получить её в коде или по адресу, вбив нужный идентификатор:
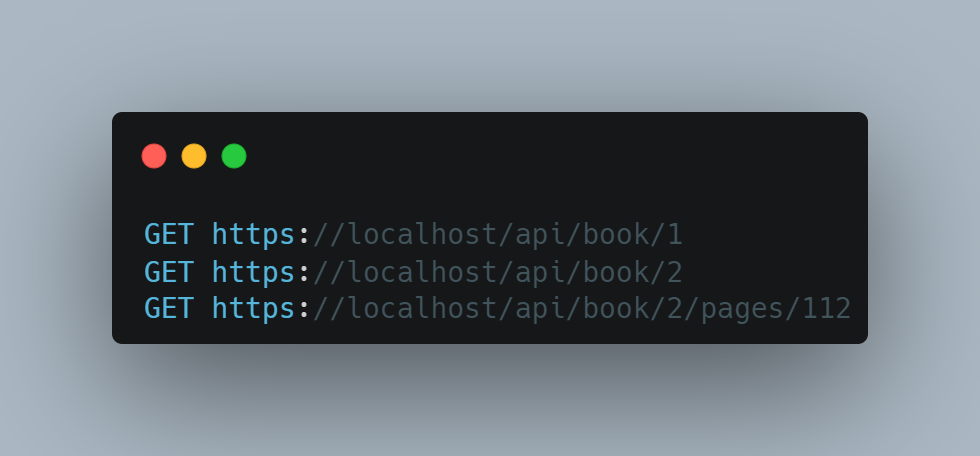
Какие недостатки у таких ключей?
Во-первых, подход с генерацией ключей в базе данных затрудняет или делает невозможным использование некоторых паттернов проектирования. Например, общий подход к идемпотентности заключается в создании идентификатора на клиенте и отправке его в запросе. Это позволяет легко устранять дублирование и гарантирует, что вы не вставите один и тот же объект дважды, так как легко обнаружить повторяющиеся запросы на вставку. Такой подход обычно невозможен с идентификаторами, сгенерированными базой данных, либо вынуждает дополнительно городить ещё одну абстракцию в виде RequestId.
Во-втроых, это усложняет код INSERT, поскольку вы должны убедиться, что возвращаете сгенерированные идентификаторы. EntityFramework под капотом назначает ID сущностям после вставки, но в случае с Dapper вам придётся делать это самостоятельно.
Третья проблема возникает только в высоконагруженных приложениях — при вставке большого количества строк БД должна блокировать генератор идентификаторов чтобы избежать использования одного ID несколькими сущностями, это может стать узким местом в приложении. Если БД масштабируется и используется master-master репликация, то всё становится ещё сложнее — в разных БД существуют разные настройки, которые могут генерировать записи с пропусками (например, первый сервер будет генерировать только нечетные идентификаторы, а второй только четные) или генерировать идентификаторы из разных подмножеств.
Резюмируя этот подход:
- Читаемые и запоминаемые URL.
- Проблемы с идемпотентностью.
- В некоторых случаях нужно дополнительно озаботиться возвращением идентификаторов при вставке.
- Снижение производительности в высококонкурентной среде.
- Усложняет масштабирование.
Генерируемый БД GUID в качестве идентификатора
При использовании сгенерированных БД гуидов мы можем избавиться от части проблем — например, NEWSEQUENTIALID() использует для генерации значений данные оборудования (MAC-адрес сетевой карты и "идентификатор часов"), поэтому сгенерированный с помощью неё иденитфикатор остается глобально уникальным. Это избавляет от необходимости дополнительной настройки генерации последовательности иденификаторов при репликации.
Функция генерирует корректно сортируемые последовательности, так что данные будут вставляться последовательно, а при слиянии данных с нескольких реплик эти данные так же будут локально последовательными.
В MySQL функция UUID() генерирует GUID версии 1, что делает их так же частично сортируемыми.
Стоит сразу заметить, что в PostgreSQL данные хранятся иначе, поэтому использование непоследовательных GUID не влияет катастрофически на производительность базы данных.
В случае генерируемых БД идентификаторов мы всё ещё вынуждены мириться с сложностью реализации идемпотентности в запросах и необходимостью заботиться о возвращении идентификаторов при вставке. Также тот факт, что гуиды являются 128-битными значениями по сравнению с 32-битными целыми числами, приводит к увеличению общего размера данных.
Генерируемый клиентом GUID в качестве идентификатора
Решение проблем генеририуемых БД первичных ключей заключается в использовании созданных клиентом идентификаторов. У этого подхода тоже есть различные плюсы и минусы!
Одним из преимуществ является то, что это просто. Все современные языки имеют доступные генераторы GUID; в .NET это метод Guid.NewGuid(), который возвращает случайный 128-битный идентификатор.
Вы можете установить это значение в качестве ID для добавляемой сущности, и вам не нужно беспокоиться о проверке, с каким идентификатором она была добавлена в БД. Используете ли вы EF Core или Dapper, Postgres или SqlServer, код будет одинаковым. Данные при запросе на вставку перемещаются только в одном направлении, от клиента к базе данных, а не в двух направлениях, как в случае с генерируемым БД первичным ключом.
Если вы создаете идентификаторы в своем клиентском коде, у вас теперь есть доступ к различным шаблонам идемпотентности. Например, представьте, что вы включаете GUID в запрос, но запрос завершается сбоем из-за ошибки сервера. Вы можете просто отправить тот же запрос еще раз, зная, что сервер сможет идентифицировать его как «дубликат», поэтому ему нужно только повторить часть действия, которое привело к ошибке или просто вернуть ответ об успешном создании сущности. Таким образом, вы можете избежать создания дубликатов.
Уникальность гуидов — это и их сильные стороны, и их слабость. С точки зрения разработчика и пользователя, с /book/55DE358F-45F1-E311-93EA-00269E58F20D работать не так просто, как с /book/1.
Тип Guid в .NET реализует UUID version 4, то есть генерируемый полностью случайным образом идентификатор. С точки зрения базы данных эта случайность может вызвать большие проблемы. Случайность идентификаторов может привести к серьезной фрагментации индекса, что увеличивает размер вашей базы данных и влияет на общую производительность.
Если подводить итог для опции генерируемого на клиенте GUID, то получится следующее:
- Легко использовать и код остаётся универсальным при переходе между разными БД.
- Позволяет сделать запросы идемпотентными без дополнительного уровня абстракции.
- Нет необходимости читать значения из БД после вставки.
- Нечеловекочитаемые URL.
- Больший объем данных по сравнению с целочисленными идентификаторами.
- Могут вызвать проблемы с производительностью БД из-за фрегментации индекса.
Преимущества сортируемого GUID
У гуидов есть несколько преимуществ, и, кроме проблем с человекочитаемостью, один большой недостаток с фрагментацией индекса, вызванной их полной случайностью. А нам всего-то и нужен сортируемый последовательно-возрастающий глобально-уникальный идентификатор чтобы использовать его в качестве ключа. Где его взять?
Отличные новости — именно для этого есть библиотека NewId, которая позволяет генерировать лексикографически упорядоченные по времени создания идентификаторы. Сама библиотека основана на Snowflake_ID от Твиттера, который разработан специально для использования в распределенных системах, и Flake, который развивает идеи UUID версии 1. Самый простой способ понять, что это значит, — показать, как выглядят идентификаторы, сгенерированные NewId.
Пример результата работы программы:
NewId использует в качестве данных для создания идентификатора 3 источника:
- Worker/process ID, который отвечает за уникальность между процессами/сервером — именно он отвечает за общую для всех идентификаторов часть, а идентификатор конкретного процесса можно включить дополнительно для избежания коллизий между процессами в рамках одной машины.
- Timestamp, который обеспечивает сортируемость идентификатора.
- Последовательно возрастающий идентификатор.
Объединив 3 части вместе, вы можете получить идентификатор, который будет частично отсортированным благодаря компоненту метки времени. Включив идентификатор процесса, можно избежать коллизий при генерации идентификаторов несколькими процессами. А использование части с последовательно возрастающим идентификатором позволяет генерировать 2^16-1 идентификаторов в миллисекунду в рамках одного процесса:
Код генерации идентификатора для самых любознательных
На сколько же NewId снижает фрагментацию индекса?
Сравнение фрагментации индекса при использовании Guid и NewId
NewId, по-видимому, в значительной степени ориентирован на сервер SQL Server. Поэтому, и потому, что для MySQL я не нашёл понятного способа измерить фрагментацию данных и эффективность использования дискового пространства, тесты проводились именно на SQL Server.
Развернем Docker-образ SQL Server:
Создадим 2 простые таблицы для разных типов сгенерированных идентификаторов:
Создадим в таблицах тестовые данные при помощи старого-доброго ADO.NET:
Чтобы посмотреть размер каждого индекса и его фрагментацию, используем стащенный из этой статьи запрос:
Результаты:
Полученные данные легко объяснить из информации, которую мы уже знаем. Во-первых, сгенерированные случайно идентификаторы приводят к большой фрагментации данных поскольку новые элементы вставляются на случайную позицию. NewId вызвали только 5-процентную фрагментацию. Ещё при использовании Guid остается больше пустого места на каждый странице с данными (возможно, из-за постоянных перемещений данных во время вставки), поэтому вам нужно больше страниц для хранения того же объема данных (77 против 59). Это тоже станет источником некоторого снижения производительности при использовании гуидов.
Но на самом деле влияние фрагментации при чтении данных совсем не так велико, как может представляться — скорее можно назвать его незначительным. Вот пример замера производительности при чтении 10.000 записей и 100.000 записей в запросе:
Настоящая проблема c производительностью гуидов начинается в больших таблицах при вставке данных — потому что индекс перестраивается случайным образом, а сервер БД не может сделать предсказания для следующего набора данных. Один из бенчмарков сравнивает производительность добавления 5 миллионов записей батч-запросами по 100.000 записей каждая в таблицу c автоинкрементным целым ключом, UUID версии 1, 4 или подхаченной "последовательной" версии 4. По результатам видно, что после полутора миллионов записей UUID версии 4 начинает деградировать, а время вставки быстро растет:
В другом бенчмарке сравнивается добавление записей в БД, где ключи генерируются разными функциями SQL: uuid_generate_v4(), uuid_time_nextval и uuid_sequence_nextval с разным набором параметров. Тесты проводятся в трёх условиях: на изначально пустой таблице, помещающейся в оперативную память таблице и явно не влезающую в оперативную память. С ростом объёма данных тоже видно значительное снижение скорости добавления новых данных в таблицу:
Выводы
NewId явно делает свою работу БД в некоторых сценариях. Но стоит ли его использовать? Ответ, как обычно — "зависит". Но это точно хорошая альтернатива, если вы уже генерируете первичные ключи на клиенте и работаете с MS SQL Server.
Telegram-канал Ростовского .net-сообщества