Приветствую дорогой друг! 🖐🏻 Сегодня мы снова решаем задачи из легендарной книги K&R. Нам остались последние упражнения в первой главе. Давай не будем откладывать это в долгий ящик - упражнения сами себя не решат!
Упражнение 1.20. Напишите программу detab, которая бы заменяла символы табуляции во входном потоке соответствующим количеством пробелов до следующей границы табуляции. Предположим, что табуляция имеет фиксированную ширину n столбцов. Следует ли сделать n переменной или символическим параметром?
Сначала ответим на вопрос. Т.к. ширина табуляции будет статичной, то правильнее будет n задать в виде символического параметра. Переменная будет занимать лишнее место в памяти компьютера, в отличие от символической константы, которую компилятор заменит на своё значение в тексте исходного кода. Если бы ширину табуляции задавал бы пользователь (например, в виде параметра при запуске программы), тогда без переменной не обойтись.
Насчет алгоритма программы detab - он прост как программа печати "hello, world"! Считываем посимвольно поток данных, фиксируем позицию текущего символа относительно границы табуляции. Если встретился символ табуляции, то вместо него печатаем пробелы до границы табуляции. Т.к. мы еще не знаем операцию получения остатка от деления (она нужна чтобы определить позицию текущего символа относительно границы табуляции), то я заменю эту операцию "г-но кодом" 😂
У меня в терминале символ табуляции имеет ширину 8, поэтому TABSIZE установил в 8 и еще заменим в программе пробел на символ нижнего подчеркивания, чтобы визуально видеть пробелы 😉
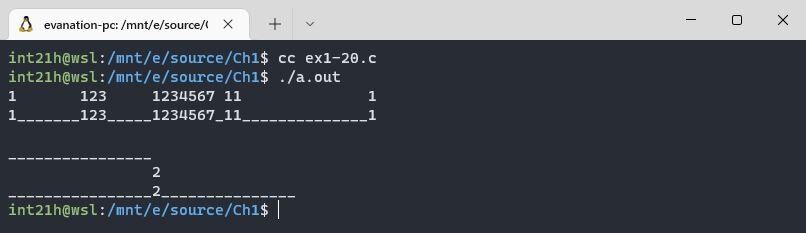
It works! Поехали дальше.
Упражнение 1.21. Напишите программу entab, которая бы заменяла пустые строки, состоящие из одних пробелов, строками, содержащими минимальное количество табуляций и дополнительных пробелов, — так, чтобы заполнять то же пространство. Используйте те же параметры табуляции, что и в программе detab. Если для заполнения места до следующей границы табуляции требуется один пробел или один символ табуляции, то что следует предпочесть?
Ух! Строки, состоящие из одних пробелов - это скучно! Усложним задачу - строки будут любые. В сравнении с предыдущим упражнением, алгоритм уже будет посложнее. По прежнему будем фиксировать текущую позицию относительно границы табуляции, но еще будем считать пробелы, когда они встретятся в потоке, но не выводя их сразу, периодически обнуляя, как только "переступим" границу табуляции или как только встретится непробельный символ. Если встретился непробельный символ до того как достигли границы табуляции, то выводим накопленные пробелы. Если переступили границу, то вместо накопленных пробелов выводим символ табуляции. Соответственно, ответ на вопрос в упражнении: мы предпочтем символ табуляции.
Поменяем в строках 25 и 30 символ пробела на символ нижнего подчеркивания и в тесте будем его использовать вместо пробела:
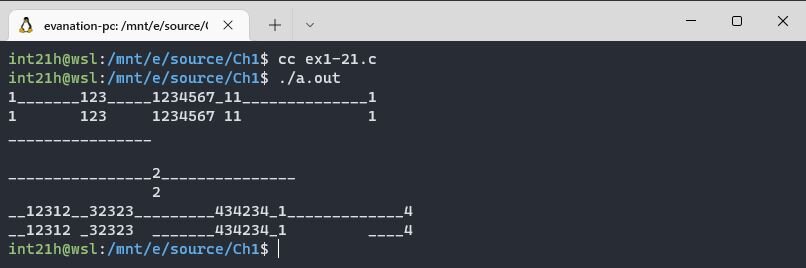
Это упражнение решено, несите следующее! 😃
Упражнение 1.22. Напишите программу для сворачивания слишком длинных строк входного потока в две или более коротких строки после последнего непустого символа, встречающегося перед n-м столбцом длинной строки. Постарайтесь, чтобы ваша программа обрабатывала очень длинные строки корректно, а также удаляла лишние пробелы и табуляции перед указанным столбцом.
Самое сложное в этом упражнении это определить как же точно должна работать программа. Нужно больше конкретики! 😕 Например, что делать, если слово в целом вмещается, кроме пробела, который отделяется от другого слова - переносить пробел на новую строку или не печатать его вообще? 🤯 В принципе, в условии нет жесткого ограничения на то, что текст должен быть не шире какой-то границы, поэтому такой пробел будем печатать на той-же строке, пускай он и выйдет за границу, но последующие пробелы, если они будут, уже напечатаются с новой строки - такое поведение у стандартного блокнота винды. Знак переноса блокнот не ставит, и наша программа не будет. Кстати, в оригинале в условии упражнения не сказано что нужно удалять лишние пробелы перед границей вывода - это отсебятина переводчика! Когда условия хоть как-то конкретизировали, можно приступать к алгоритму. Будем считывать слово до нечитаемого символа (пробела, табуляции или символа новой строки) но не больше лимита выводимой строки. Перед выводом проверяем - вмещается ли строка полностью в границы, если нет - печатаем слово с новой строки. У меня такой код получился:
Возьмем какой-нибудь английский текст (мне лень настраивать терминал на KOI8-R) и проведем тест программы:
Всё четко! 😊 Решаем следующее упражнение.
Упражнение 1.23. Напишите программу для удаления всех комментариев из программы на С. Позаботьтесь о корректной обработке символьных констант и строк в двойных кавычках. Вложенные комментарии в С не допускаются.
Достаточно простое упражнение для нас. Посимвольно читаем входной поток и фиксируем состояние чтение. В зависимости от состояния выводим или нет прочитанный символ.
Всё работает! 😊 Осталось последнее упражнение в первой главе и на сегодня!
Упражнение 1.24. Напишите программу для выполнения примитивной синтаксической проверки программ на С, таких как непарные круглые, квадратные и фигурные скобки. Не забудьте об одинарных и двойных кавычках, управляющих символах и комментариях. (Это сложная программа, если пытаться реализовать самый общий случай.)
Ничего себе! 😦 Такими темпами к концу чтения книги мы напишем целый компилятор! 🤭 В идеале программа должна проверить не только парные скобки, но и их порядок. Например: { ( } ) - явная ошибка, хотя все скобки парные. Или: ) ( - ошибка последовательности скобок. Т.к. у нас ограниченные знания, то такие проверки будет достаточно непросто написать и код получится слишком сложным, поэтому ограничимся просто парной проверкой. Также будем проверять на незакрытые комментарии, двойные и одинарные кавычки. Для этого заведем три переменные для каждого вида скобок. Если встретилась открывающая скобка, то увеличиваем соответствующую переменную на 1. Если встретилась закрывающая, то уменьшаем на 1. Если все скобки парные, то к концу чтения эти переменные должны быть со значением 0. Не закрытые комментарии и кавычки будем проверять по состоянию чтения. Проверку состояния чтения возьмем из предыдущего упражнения.
Вроде как работает 🙂
Ну вот, мы решили все упражнения в первой главе. Далее будем более углублено изучать язык Си, а упражнения станут еще интереснее. Скоро увидимся!
#k&r #c #programming