Здравствуй дорогой друг! Сегодня у нас по плану еще 4 упражнения и они уже не такие тривиальные как предыдущие 😮, но зато очень интересные. Погнали решим их!
Упражнение 1.16. Доработайте функцию main программы определения самой длинной строки так, чтобы она выводила правильное значение длины самой длиной строки и печатала как можно больше текста из этой строки.
Из-за этого упражнения я много раз бросал читать книгу и выполнять остальные упражнения, а всё потому что у меня была версия с первым переводом 🤦🏻♂️, а в ней это упражнение переведено так:
Перепишите main предыдущей программы так, чтобы она могла печатать самую длинную строку без каких-либо ограничений на ее размер.
С теми познаниями в языке C, которые у нас есть, это упражнение в таком переводе нерешаемо 😡! А будем считать, что мы можем применять только те знания, которые нам дали авторы книги до выполнения упражнения.
На языке оригинала условие задачи такое:
Revise the main routine of the longest-line program so it will correctly print the length of arbitrarily long input lines, and as much as possible of the text.
Но и во втором переводе, кстати, ненамного лучше:
Доработайте главный модуль программы определения самой длинной строки так, чтобы она выводила правильное значение для какой угодно длины строк входного потока, насколько это позволяет текст.
Поэтому, я рискнул переделать условие упражнения так, как я понимаю его в переводе с английского. Если ты не согласен с моим переводом, то сообщи об этом в комментариях. 😊
Итак, для начала посмотрим на исходный код программы, которую нам предстоит переписать:
И посмотрим как она работает в случае когда вводимые строки больше, чем MAXLINE. Изменим MAXLINE на 10, для того чтобы не вводить большие строки. Скомпилируем программу и протестируем её на небольшом количестве строк:
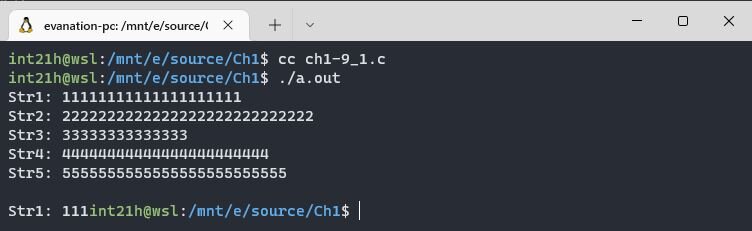
Программа должна была вывести самую длинную строку, а самая длинная вторая, а не первая 😢. У программы такое поведение из-за условия i < lim-1 в цикле for функции getline (строка 35). Получается алгоритм программы обрезает вводимые строки, чтобы они не оказались длиннее MAXLINE во избежание переполнения массива. Но не переживай, сейчас мы это исправим!
По условию задачи мы можем переписать только функцию main, а getline и copy требуется оставить без изменений. Нам и не нужно переписывать ничего, кроме функции main, потому что getline считывает строки по частям. Если строка больше лимита, то в следующий вызов getline начнет считывать оставшуюся часть строки до тех пор пока она не кончится (до символа '\n') или пока опять не будет достигнут лимит чтения. Такую подсказку нам оставили авторы в главе 1.9:
Например, что делать функции main, если ей встречается строка длиннее предельной длины? Проверяя длину строки и последний введенный символ, функция main может определить, не чрезмерную ли длину имеет строка, а затем обработать эту ситуацию по своему усмотрению.
Т.е. ключ к решению этого упражнения - после каждого вызова getline проверять была ли строка прочитана до конца. Это мы можем проверить, ведь если getline прочитал строку до конца, то в массиве line есть элемент с индексом равным длине прочитанной строки уменьшенной на 1 и со значением '\n' (длину прочитанной строки возвращает функция getline) , в противном случае просто был достигнут лимит чтения и строка была прочитана не полностью. Значит нужно завести переменную, в которой будем накапливать длину до тех пор пока getline не прочитает строку полностью. И нужен еще один массив, в который будет сохранено начало строки, которое нам понадобится для вывода результата работы программы. Также сделаем печать длины максимальной строки:
Протестируем на том же наборе данных, на котором тестировали программу до изменений. Не забываем изменить MAXLINE на 10:
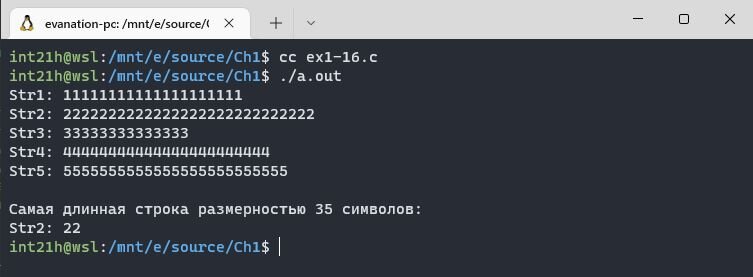
Совсем другое дело. Упражнение выполнено! 🥳 Переходим к следующему.
Упражнение 1.17. Напишите программу для вывода всех строк входного потока, имеющих длину более 80 символов.
Очень легкое упражнение по сравнению с предыдущим. В условии ничего не сказано о дополнительных ограничениях, только размер строк, которые нужно выводить. Не будем рассматривать вопрос производительности и реализуем самый простой вариант с минимальным размером буфера чтения входного потока. Буфер должен быть такого размера, чтобы сразу отсеять строки, которые выводить не нужно, т.е. нужные нам строки должны считаться функцией getline минимум за два приема. Из функции getline удалим второй аргумент (можно было бы оставить вариант функции из предыдущего упражнения, но мне так больше нравится 😇). Примечательно, что размер буфера никак не влияет на количество символов выводимой строки - строки любой длины больше указанного ограничения будут выведены полностью, а не их часть как в предыдущем задании!
Скомпилируем код, предварительно изменив LINEL на 10. Как же тебе показать результат работы программы на одном скрине? 🤔 Дело в том, что "потоком данных" выступает терминал, а он отправляет данные каждый раз после нажатия enter или после символа новой строки. Невозможно передать в терминал многострочный текст за один раз - терминал будет формировать поток данных после каждой строки. Поэтому я просто прокомментирую кратко скрин:
Первые три вводимые строки с учетом знака новой строки имеют длину меньшую или равную LINEL, поэтому после ввода программа их не печатает. Четвертая строка пустая (её длина 1 символ). У пятой строки уже длина 11 и после ее ввода она напечаталась. Следующая строка состоит из одних пробелов и табов - программа ее обработала по общим правилам. Последняя строка намного больше буфера чтения и программа ее вывела без обрезки. Это успех! Переходим к следующему упражнению.
Упражнение 1.18. Напишите программу для удаления лишних пробелов и табуляций в хвосте каждой поступающей строки входного потока, которая бы также удаляла полностью пустые строки.
Хм 🤔. В принципе задача легко решаема. Достаточно при чтении потока данных фиксировать позицию последнего непробельного символа. Но есть проблема переполнения буфера чтения. Если мы будем считывать строки по частям, как в прошлых упражнениях, то пока не прочитаем строку до конца мы никогда не узнаем следует ли удалять пробелы в конце части строки - ведь это могут быть пробелы в середине строки, а по условию нам нужно удалить их только в хвосте! Значит функция getline должна считывать строку до её конца и сохранять часть строки, которая поместится в буфер. Визуально будем выводить "<...>" в конце тех строк, которые не вместились в буфер. Функция getline также должна ставить знак конца строки '\0' в конец буфера (если произошло переполнение) или после последнего непробельного символа (если переполнения не было). Возвращать getline будет длину строки с уже удаленными пробелами в хвосте, так что мы сможем узнать было ли переполнение буфера.
Поменяем MAXLINE на 10, а еще добавим символ нижнего подчеркивания в список пробельных символов (строка 39 примет вид if(c != ' ' && c != '\t' && c != '_') - это поможет нам визуально увидеть, что пробелы действительно удаляются. Только вместо пробелов будем использовать нижнее подчеркивание:
Наш алгоритм работает без ошибок! 😍 Осталось еще одно упражнение.
Упражнение 1.19. Напишите функцию reverse(s), которая переписывает свой строковый аргумент s в обратном порядке. Воспользуйтесь ею для написания программы, которая бы выполняла такое обращение над каждой строкой входного потока по очереди.
Это совсем просто 😬. В функции reverse реализуем классический алгоритм реверса массива. Функция getline, как в прошлом упражнении будет считывать всю строку и помещать в буфер что поместится. Также, как и в прошлый раз, переполнение буфера будет сигнализироваться добавлением "<...>" к строке, только в начало, а не в конец. Можно было бы getline и по другому реализовать - например, сохранять в буфер не начало, а конец строки. Но думаю целью упражнения является функция reverse, которая будет неизменна для обоих вариантов, поэтому ограничимся одним вариантом программы:
Для теста изменим MAXLINE на 10:
Готово! Сегодня мы решили еще 4 упражнения! И мы почти закончили первую главу. У нас с тобой отличные результаты 😉. Удачи друг и до скорой встречи! 🤠
#k&r #c #programming