Здравствуй друг! Сегодня мы решим еще 5 упражнений из книги K&R. Приступим.
Упражнение 1.11. Как бы вы протестировали программу подсчета слов? Какого рода входной поток скорее всего выявит ошибки в программе (если таковые есть)?
Упражнение для будущих тестировщиков 😃. А я не очень люблю тестировать свой код и уж тем более чужой 😒, а протестировать нам с тобой предлагают следующую программу из главы 1.5.4:
Как мне кажется, чтобы выявить ошибки в программе подсчета слов, поток данных должен содержать в себе:
- пустые строки;
- строки, состоящие только из нечитаемых символов (пробелов и табуляции;
- в строках между словами есть более одного подряд стоящих нечитаемых символов;
- строки, начинающиеся или оканчивающиеся на нечитаемые символы или начинающиеся или оканчивающиеся на несколько подряд стоящих нечитаемых символов.
Больше ничего придумать не могу. Если у тебя есть что добавить к этому списку, то обязательно сообщи мне в комментариях 🤭. А пока я протестирую программу по своему списку:
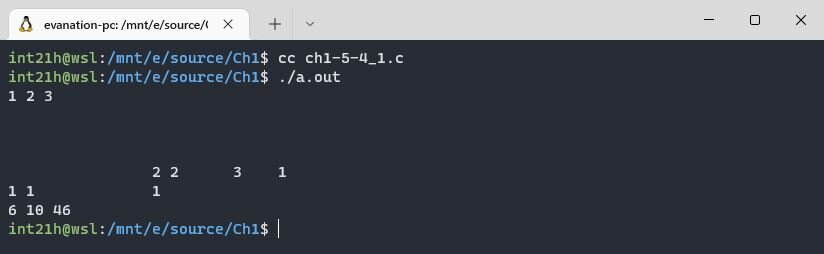
Второе число в последней строке вывода программы показывает количество слов. Всё верно. Наш тест не выявил ошибок 😃. Решаем следующее упражнение.
Упражнение 1.12. Напишите программу для вывода входного потока по одному слову в строке.
Условие понятно и упражнение будет легко выполнено, ведь в нашем арсенале появились операции конъюнкции (И) и дизъюнкции (ИЛИ), а также мы теперь знаем конструкцию if ... else ... . Осталось только придумать алгоритм. Ключом к решению этой задачи будет идея, что программа будет заменять пробельный символ (пробел или табуляцию) на символ новой строки ('\n'), если предыдущий символ не был пробельным и не печатать пробельный символ, если предыдущий символ был тоже пробельным. Для этого заведем переменную, которая будет хранить текущее состояние (находимся мы в слове или слово кончилось):
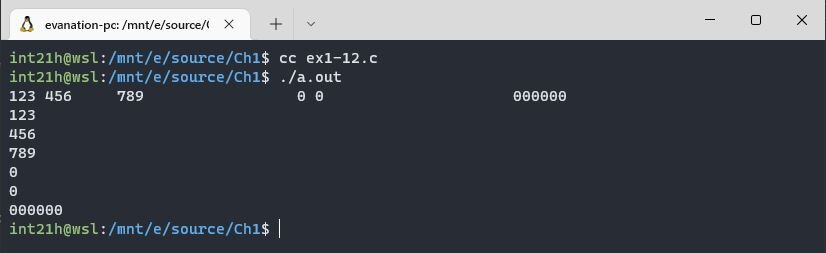
Это было слишком просто, может следующее упражнение будет посложнее 😏
Упражнение 1.13. Напишите программу для вывода гистограммы длин слов во входном потоке. Построить гистограмму с горизонтальными рядами довольно легко, а вот с вертикальными столбцами труднее.
Хорошее упражнение. Пусть гистограмма выводит длины слов от 1 до N, а слова длиннее N пускай выводятся отдельной строчкой. Для этого нужен массив на N+1 элементов.
Проверим рандомный текст 😀
Кстати, если запустить эту программу в терминале, который работает в кодировке UTF-8 (или любой другой многобайтовой), то один символ кириллицы будет считаться за два. Это связано с тем, что в кодировке UTF-8 кириллические символы занимают по два байта, в отличие от латинских символов, которые занимают по одному байту, а функция getchar() считывает один байт во входящем потоке. Чтобы программа работала корректно с кириллицей нужно переключить кодировку в терминале на однобайтовую, например KOI8-R 😀
С горизонтальной гистограммой судя по всему мы успешно справились. А как же сделать вертикальную? 🤔 Для этого перед выводом гистограммы нам нужно узнать сколько гистограмма будет занимать строк в высоту, а это значение равное самому большему количеству слов одной длины, т.е. максимальное значение в массиве. Инициализируем переменную которая будет хранить это значение и в момент заполнения массива будем её обновлять. При выводе гистограммы будем проверять значение каждого элемента массива с порядковым номером текущей выводимой строки, если значение элемента массива меньше номера строки, то печатаем пустое пространство, иначе печатаем ' | '. Номера строк растут снизу вверх, т.е. первая выводимая строка после заголовка гистограммы имеет наибольший порядковый номер:
Не так уж это было и трудно 😎 Решаем следующее упражнение?
Упражнение 1.14. Напишите программу для вывода гистограммы частот, с которыми встречаются во входном потоке различные символы.
Это упражнение уже не такое интересное, т.к. почти не отличается от предыдущего 🙁. Но мы всё равно его сделаем и также в двух вариантах - с горизонтальной и вертикальной гистограммой 💪🏻. Отличие будет только в размерности массива - он нужен на 256 элементов (если считать что один символ занимает в памяти 1 байт) и еще для экономии места на экране не будем выводить значение, если символ в потоке не встретился.
Вариант с горизонтальной гистограммой:
Вертикальная гистограмма:
Красиво! 😋 Решаем последнее на сегодня упражнение.
Упражнение 1.15. Перепишите программу преобразования температур из раздела 1.2 так, чтобы само преобразование выполнялось функцией.
Помнишь программу преобразования температур? Мы с ней работали в прошлый раз. Вот её исходный код:
От нас требуют инкапсулировать расчет температуры по Цельсию, т.е. написать отдельную функцию и вызвать её в 18 строке 😃. Это несложно:
Работа программы не изменилась, по сравнению с версией без отдельной функции перерасчета:
А это значит мы справились еще с пятью упражнениями! 💪🏻 Отличная работа! Если ты захочешь дополнительно обсудить решение любого упражнения, то добро пожаловать в комментарии 🙃.
Хорошего тебе дня, друг! ✋🏻
#k&r #c #programming