Apache Kafka нынче используется большинством компаний. Нередко Кафку описывают словами "шина данных" - зачастую это главная артерия данных в больших и сложных системах, по которой циркулируют данные между различными ее частями. В этой статье и я расскажу, зачем и как появился этот инструмент, какие проблемы решает и почему он так важен.

В серии статей "Узнай-ай-ти" я простыми словами объясняю явления, подходы и технологии из мира IT. Если Вы хотите о чем-то узнать, пишите в комментариях, и я обязательно разберу это в будущих статьях.
Асинхронные сообщения
Начну немного издалека. Как Вы наверняка знаете, все современные IT-системы обычно состояит из набора отдельно стоящих слабо связанных сервисов, или микросервисов. Полностью независимыми, понятное дело, они быть не могут (иначе какая же это система?), поэтому основное, как они друг с другом взаимодействуют - это обмен сообщениями.
Наверняка у многих из Вас может совершенно естесственно возникнуть вопрос:
Что тут может быть сложного в такой простой операции? Сервисы же могут общаться через API, то есть: сервис А предоставляет endpoint (эндпоинт), который может вызвать сервис B, передав нужные данные и получив ответ. Вот и все.
Верно, так часто и происходит. Так реализуется синхронное взаимодействие, однако, бывает, требуется и асинхронное. Что это значит?
- иногда не нужно, чтобы сообщение было доставлено ПРЯМО сейчас. Возможно, принимающая сторона сейчас занята, и она примет сообщение в обработку чуть позже, когда будет возможность
- ответ тоже не всегда необходим сразу же. Мы готовы ждать какое-то время, прежде, чем нам придет ответ
- возможен даже вариант, когда нам ответ не важен - то есть если даже если сообщение не было обработано, нам это не критично
Чтобы реализовать такую подсистему асинхронного общения, понадобится много усилий: это и организация очереди сообщений, и устойчивость к падениям, таймауты на отправку/получение и многое другое... Поэтому для таких случае был разработан протокол AMQP, и множество систем обмена сообщениями, реализующих его. Пожалуй, самые известные, это RabbitMQ и ActiveMQ.
Причем тут Kafka?
Я бы назвал такие системы предшественниками Apache Kafka, хотя для многих задач они хорошо подходят и в самой Kafka надобности нет. Тем не менее, по моему субъективному ощущению все больше и больше Kafka вытесняет AMQP системы. В чем же их проблема?
Проблема совершенно естесственна и вытекает из того, для чего AMQP-системы проектировались: для обмена сообщениями только между двумя сервисами. Несмотря на то, что обычно есть возможно опубликовать сообщение в топик сразу для чтения его из нескольких систем - это далеко не полностью решает проблему.
Архитектура же Apache Kafka устроена так, что она позволяет записанное один раз сообщение читать сколько угодно другими сервисами, причем очень продолжительное время. Чтобы было понятно, посмотрим "сверху" на то как Кафка устроена.
Архитектура
AMQP можно в голове представлять действительно как систему обмена сообщениями - что-то такое, что позволяет перенаправлять поток данных из одного места в другое. У Kafka другой подход - на самом деле, любое сообщение, которое Вы отправили Кафке, сразу же записывается на диск!
Все такие сообщения записываются в виде лога: то есть они укладываются друг за другом подряд на диск, и каждому сообщению назначается свой номер, так называемый оффсет (offset). Теперь клиенту, чтобы начать читать сообщения, нужно знать только offset, на котором он остановился в прошлый раз (если клиент приходит в первый раз, то он, соответственно, начинает читать сначала). После этого, можно запрашивать у Кафки сообщения начиная с этого оффсета, и читать их, сколько захочется: до конца, или остановиться где-то посередине. После чтения лог с сообщениями не удаляется, поэтому их можно прочитать еще раз заново, или продолжить с того места, где остановился. Это значит, что читать может одновременно множество клиентов параллельно, причем каждый со своего места!
Итак, теперь проблема, которая была обозначена в AMQP решена: сообщения из исходного сервиса можно отправить один раз, а прочитать их смогут кто угодно, сколько угодно раз и практически когда угодно.
Так как Kafka - это все-таки шина данных, а не долгосрочное хранилище, то этот самый лог иногда подчищается с начала(удаляются самые "старые" записи). Стандартное время хранения - одна неделя(конечно, можно настроить). То есть, сообщения, которые опубликовал Ваш сервис, еще неделю могут читать другие клиенты! Это предоставляет различные сценарии использования Кафки: ее можно использовать и как real-time систему доставки сообщений, так и как источник данных для батчевых job - например, Вы можете прочитать данные, которые копились от сервиса целые сутки, проанализировать их, выдавать какую-нибудь аналитику по ним и снова "заснуть" на сутки. А главное - Вы можете применять все эти подходы одновременно!
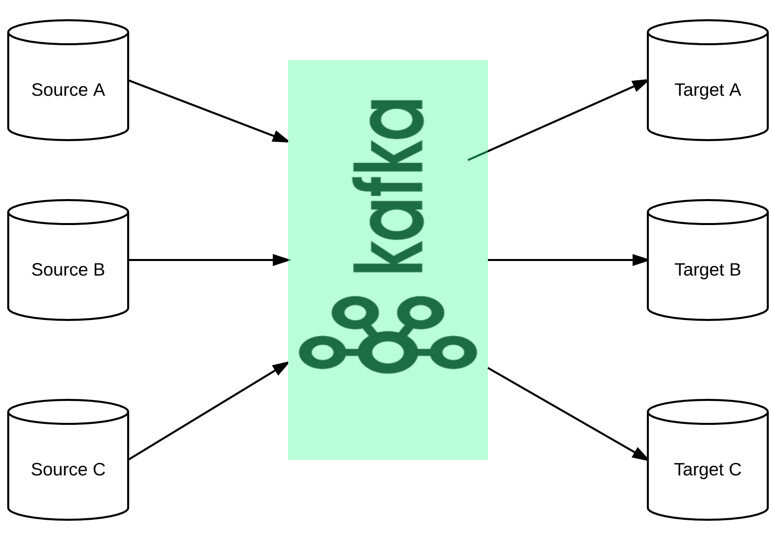
Единая точка маршрутизации
Хочу еще раз сравнить Кафку с другими системами доставки сообщений с точки зрения архитектуры. Пусть у нас есть N сервисов-отправителей сообщений (генерируют данные) и M сервисов-получаетелей сообщений. В худшем случае, когда все сервисы общаются между собой, пришлось бы исользовать N x M очередей! Каждое сообщение пришлось бы отправлять по M раз, и это безумно запутанно!
В случае же с Кафкой - мы просто ставим ее посередине между всеми сервисами и больше не заботимся на стороне отправителей, кому мы должны отправлять сообщения - мы просто можем не знать, что за клиенты читают наши данные и сколько вообще их. Мы просто пишем данные в Кафку и забываем о них. Клиенты (сервисы-получатели) сами разберутся, что они будут читать и когда.
Масштабируемость
Нужно отметить, что еще одно важное свойство Кафки - это масштабируемость. Для этого немного углубимся в ее архитектуру.
На самом деле, основное разделение данных в Кафке идет по топикам (topics): это как раз то, что пишут сервисы. Например, Ваш сервис генерирует сообщения о заказах, сделанными пользователями интернет-магазина: и он складывает их в топик под названием, например, orders. Также сервис логгирует неудачные попытки логина в интернет-магазин, и записывает сообщения с информацией о них в топик unsuccessful_login_attempts. Ваш сервис может писать в Кафку множество таких топиков, но и другие сервисы могут иметь свои топики в той же кафке. И именно внутри этих топиков сообщения записываются в лог, откуда сервисы-клиенты могут читать данные в порядке их записи.
С точки зрения масштабируемости это значит, что мы можем завести несколько серверов (они называются брокерами) Kafka, объединить их в кластер, и "раскидать" по ним топики. Если места будет не хватать для новых топиков, под них можно завести новые Kafka-сервера в кластер!
Но и это еще не все - масштабирование возможно и в рамках топика: топик можно разделить на партиции. А партиция - это часть сообщений топика. Например, если Вы делите топик на 24 партиции, то можно писать в каждую партицию поровну сообщений - по 1/24. На самом деле, я Вас немного обманул, потому что сообщения пишутся в виде лога (подряд в порядке поступления) в рамках партиции топика.
Надеюсь, я Вас не сильно запутал. Но на всякий случай приведу схему устройства топика в Кафке:
Здесь топик состоит из 4х партиций (от 0 до 3х), и, на картинке показано, как справа в лог каждой партиции записываются сообщения. В рамках каждой партиции они имеют номер(тот самый offset) и упорядочены по времени записи.
Значит, и топик можно "раскидать" по различным серверам Кафки - различные партиции будут находиться на разных серверах - это может ускорить работу с топиком: теперь и запись и чтение можно производить во много потоков на независимые сервера Кафки (брокеры).
Заключение
У Кафки множество достоинств, которые не вошли в эту статью - по ней можно написать книгу, и даже не одну(и они уже написаны). Сюда входят и отказоустойчивость, и обратная совместимость, и удобность использования и целая эко-система, которая выросла вокруг.
Суть в том, что сейчас это - одна из самых важнейших и востребованных технологий, а значит, наверняка придется столкнуться с ней в своей карьере. Теперь будем считать, что Вы готовы!
Если Вам понравилась эта статья, ставьте лайк и подписывайтесь на канал. Также, в комментариях поделитесь, о какой технологии Вы бы еще хотели узнать. До встречи в новых статьях серии "Узнай-ай-ти"!