В этой публикации, «Как удалить дубли страниц в WordPress», я опишу, как искать копии страниц и как избавиться от этих дублей. Это очень серьезный вопрос имеющий отношение к внутренней оптимизации сайта, определяющий перспективу развития Вашего ресурса и его удачное продвижение.

Типы дублей страниц
Существуют 2 вида дублей — четкие (целые) и нечеткие.
- Четкая (целая) копия — это страницы ресурса имеющие абсолютно одинаковый контент, но содержащие разные адреса URL, например, пагинации.
- Нечеткая (не целая) копия — это страницы, у которых часть содержимого похожа, а другая часть отличается, к примеру, архивы авторов или архивы записей.
Их существование может ухудшить индексацию блога, понижению позиций в выдаче и к применению санкций (фильтров) поисковиками.
Разными причинами может быть обусловлено появление дублей страниц на сайте.
- Технические недоработки. Этими недоработками могут быть: неверно настроенный robots.txt, битые ссылки, удаленные страницы и не налаженный редирект 301 с www домена на без www.
- Автоматические копии страниц. Большое число движков (CMS) автоматически создают копии страниц на ресурсе без участия веб-разработчика или оптимизатора. Среди которых Joomla и WordPress. Дубли появляются в анонсах, ответах на комментарии, архивах, страницах автора.
- Ошибки оптимизатора. Черная seo оптимизация и влияние на поисковых роботов. Отдельные вебмастера намеренно генерируют документы, которые являются частичными или полными дублями, дабы увеличить количество страниц и разместить побольше рекламы.
А сейчас рассмотрим алгоритм нахождения копии страниц на блоге.
Как обнаружить дубли страниц
Есть много бесплатных методов, основанных как на применении Google и Яндекс, так и с использованием программных инструментов, анализирующее имя домена. Сперва будем использовать наиболее простые и трудоемкие.
Поиск дублей с помощью Яндекса
В поиске Яндекса, вставьте ту часть текста (site:свой_домен.ru «подозрительный текст»), заключив ее в кавычки, в отношении которой имеются подозрения в существовании копии и отправьте поисковой системе этот запрос. Не забудьте указать свой домен в начале запроса. На картинке внизу был взят анонс статьи, ввиду этого появляется, кроме страницы со статьей, еще и на главной и на страницах рубрик– частичные копии.
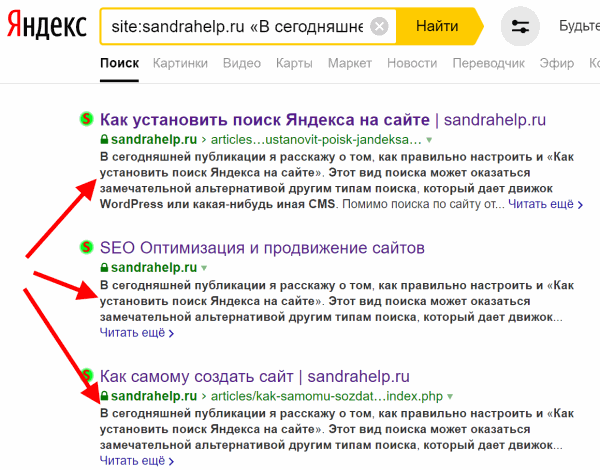
Это не страшно, если вы нашли лишь частичные дубли текста анонса, важно, чтобы основной текст вашей статьи нигде не повторялся. Данный пример был взят специально, чтобы вам продемонстрировать – анонс статьи не надо делать большим (2-3 предложения в одном абзаце).
Поиск дублей с Google
Эта технология по поиску копий схожа с предыдущей. Как и в вышесказанном способе, берете кусок текста с кавычками и ставите в окно поиска Гугла, в начале текста напишите строку site:свой_домен.ru.
Если будут обнаружены копии, тогда они окажутся в выдаче. Теперь перейдем от обычных способов к применению специальных инструментов.
Удаление дублей страниц
Здесь рассмотрим пять вариантов удаления копий.
- Выключить древовидную структуру комментариев. Это наиболее простой вариант решения этой проблемы. В настройках древовидных комментариев убираем чекбокс, и проблема исчезнет навсегда.
Данный способ хорош в том случае, если у ваших постов мало оставленных отзывов и нечасто появляются дискуссии. Выключив кнопку «ответить» исчезнет и ссылка, создающую копию поста.
- Изменить comment-template.php. С помощью этого способа можно исправить код, создающий replytocom, убрав из него проблемные записи. И в самой ссылке уже не будет создаваться replytocom.
Для воплощения данного способа откроем comment-template.php, чтобы отредактировать его. На WordPress, он располагается в каталоге /wp-includes. Внутри него ищем небольшой кусочек кода показанный ниже:
Надо удалить ‘replytocom’, $comment->comment_ID — этот отрезок кода добавляет проблемный хвостик к ссылке.
Сохранив дубли исчезнут, однако не навсегда. Если вы сделаете обновление версии WordPress, то все файлы будут обновлены, в том числе и этот, и придется заново делать изменения.
- Применение атрибутов nofollow/noindex и канонических URL. С помощью rel="canonical" можно показать роботам поисковиков, какая из всех дублей страниц должна быть основной (канонической). Этот параметр можно настроить WordPress плагином All in One SEO Pack.
С помощью данного модуля можно закрыть для индексации разные разделы блога.
- Директива Disallow. Этот способ не удаляет копии, он лишь говорит роботам, что определенные страницы индексировать не надо. К примеру, если в какой то папке находятся копии статей, а проанализировав их адрес, вы это сможете понять, тогда можно закрыть эту папку настроив файл robots.txt.
User-agent: *
Disallow: /?replytocom*
- Редирект 301 в htaccess. Этот вариант удаления дублей — самый классный. На сайте ничего не нужно менять. Просто делаем настройку в файле htaccess постоянной переадресации, другими словами редирект 301, со всех адресов с replytocom на главные страницы без replytocom.
Вот этот код напишем в htaccess:
RewriteCond %{QUERY_STRING} replytocom=
RewriteRule ^(.*)$ /$1? [R=301,L]
В итоге наши ссылки с replytocom останутся на страницах, а поисковые роботы перейдя по ним окажутся на канонической странице. С помощью редиректа, через какое то время и Гугл и Яндекс удалят полностью из своих баз ссылки с хвостами и вы навсегда будете защищены от дублей.
Тут, пожалуй, все. Вопросы по статье, «Как удалить дубли страниц в WordPress», пишите в комментариях.