
Источник: Nuances of Programming
Предыдущая часть: “MongoDB: индексация”
Операции агрегирования обрабатывают данные и возвращают вычисленные результаты. Они группируют значения из нескольких документов, выполняют с ними разные действия и возвращают один-единственный результат. В SQL аналогами операций агрегирования MongoDB являются функция count(*) и оператор group by.
Метод aggregate()
Для агрегирования данных в MongoDB используется метод aggregate().
Синтаксис
Ниже представлен основной синтаксис aggregate():
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
Пример
Коллекция содержит следующие данные:
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'NOP',
url: 'https://nuancesprog.ru',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
_id: ObjectId(7df78ad8902d)
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'NOP',
url: 'https://nuancesprog.ru',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
_id: ObjectId(7df78ad8902e)
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'Neo4j',
url: 'http://www.neo4j.com',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
},
Опираясь на данные этой коллекции, отобразим количество учебных материалов, написанных каждым пользователем. Для этого воспользуемся методом aggregate():
> db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
{ "_id" : "NOP", "num_tutorial" : 2 }
{ "_id" : "Neo4j", "num_tutorial" : 1 }
>
В SQL аналогичный запрос для рассмотренного случая выполняется операторами: select by_user, count(*) from mycol, group by by_user.
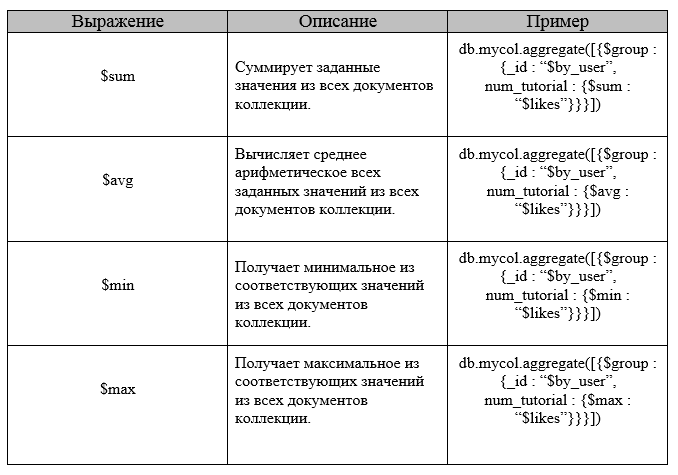
В данном примере мы сгруппировали документы по полю by_user, и при каждом нахождении by user предыдущее значение sum увеличивалось. Ниже представлен список возможных выражений агрегирования:
Концепция конвейерной обработки
В командной оболочке UNIX конвейер (pipeline) означает возможность выполнить операцию на входе и использовать вывод в качестве ввода для следующей команды и т.д. MongoDB также поддерживает этот принцип во фреймворке агрегирования данных. Он предусматривает совокупность последовательных операций, в процессе которых в качестве ввода принимается один набор документов, а на выходе получается другой (или итоговый документ JSON в конце конвейера). Полученный результат используется в следующей операции и т.д.
Перечислим доступные операторы во фреймворке агрегирования:
- $project: выбирает указанные поля из коллекции;
- $match: выполняет фильтрацию и тем самым уменьшает число документов, поставляемых на вход следующей операции;
- $group: выполняет агрегирование;
- $sort: сортирует документы;
- $skip: позволяет перейти вперед по списку, пропустив указанное количество документов;
- $limit: ограничивает количество документов для просмотра. Определяет их число, начиная с текущих позиций.
- $unwind: разворачивает документы с массивами. При использовании массивов данные предварительно объединяются. Этот же оператор выполняет противоположную операцию, позволяя получить каждый документ по отдельности. В результате возрастает количество документов для следующей операции.
Читайте также: