Теорема САР (или Теорема Брюера) со временем становится все более и более актуальной, потому что сейчас все чаще используются микро-сервисы, распределенные системы и распределенные вычисления.
Запускаю серию статей "Узнай-АйТи" для начинающих разработчиков или людей, которые только начинают свой путь в IT. В этой серии я буду наболее сжато, кратко и используя понятный язык объяснять полезные и/или интересные явления из мира IT, которые обязательно Вам пригодятся!
Несмотря на то, что практического смысла теорема несет не так много, она очень важна для понимания работы современных распределенных систем! И расскажу я Вам о ней, опираясь на контекст СУБД (система управления базами данных, далее - база данных), потому что наверняка вы с какой-то мере уже сталкивались с ними.
Теорема
Теорема САР - это утверждение о том, что любая распределенная система не может обладать одновременно тремя свойствами: согласованность данных, доступность и устойчивость к разделению
Сначала я поясню кратко, что каждое из этих свойств значит, а потом попытаюсь "на пальцах" объяснить, что же они означают и почему не могут ужиться вместе.
Согласованность данных
Согласованность данных (или consistency) - в принципе, название говорит само за себя. Это когда данные не противоречат сами себе и находятся в консистентном состоянии.
Приведу простой пример. Допустим, Вы записали некую строку в базу данных и получили ответ о том, что запись была произведена успешно. Далее, Вы у этой же базы данных спрашиваете эту же записанную строчку, и получаете ответ о том, что такая строчка не найдена.
Оказывается, не во всех системах требуется такая строгая консистентность. Например, в аналитических базах данных то, что некоторые данные "долетят" чуть позже, чаще всего не играет критической роли. Ну, немножко "поплывет" график, временно просядет. Ничего страшного.
Как такое может произойти, расскажу дальше.
Доступность
Доступность (availability) - в любой момент времени система способна дать ответ на запрос.
Конечно же, мы хотим построить такую систему, которая будет доступна 100% времени! Но и здесь часто можно пожертвовать этим свойством в угоду другим.
Устойчивость к разделению
Устойчивать к разделению (partition tolerance) - смысл распределенной системы часто в этом и заключатеся - "разнести" данные или вычисления по различным удаленным узлам, что данных могли храниться раздельно, а вычисления проводиться независимо и параллельно.
Объяснение
Что же это за такие свойства, и почему же они не могут быть вместе? Давайте смотреть на примере баз данных.
Теорему САР обычно изображают в виде треугольника, где на углах расположены указанные три свойства, а любая распределенная система лежит на какой-то из сторон треугольника, потому что она может удовлетворять максимум двум свойствам из трех.
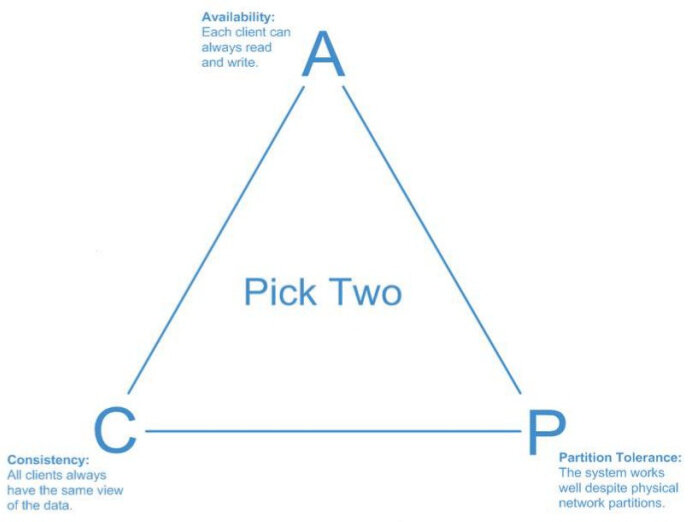
Отказываемся от устойчивости к разделению (реляционные базы данных)
Все Вы наверняка имели дело с реляционными базами данных. Например, Postgres, MySQL, MariaDB и т.д. Попробуйте спроецировать эти три свойства на них. Поняли, в чем проблема?
Все эти системы не удовлетворяют последнем свойству - устойчивости к разделению.
В реляционной модели данных, где данные "нормализованы", часто возникает потребность, например, в операциях JOIN. Такие операции тяжело производить в распределенных системах, когда данные "раскиданы" по различным узлам системы.
Совершенно естесственным образом согласованность и доступность были заложены при проектировании реляционных баз данных. Более того, в то время, когда они проектировались, проблема горизонтального масштабирования не стояла так остро.
Однако сейчас, когда данных становится все больше и больше, необходимо иметь свойство устойчивости к разделению и жертвовать каким-то из других двух. Но что же может из этого выйти?
Отказываемся от согласованности данных
Попробуем посмотреть, что значит, когда данные у нас могут быть не согласованы.
Для этого представим просто базу данных, расположенную на двух хостах, где каждый из хостов является репликой другого
А теперь потребуем, чтобы репликация происходила асинхронно. Это значит, что алгоритм записи в базу данных такой:
- клиент пишет данные на один из хостов
- хост записывает, сохраняет данные и дает корректный ответ клиенту
- данные фоновым процессом копируются на реплику
А теперь представим, что клиент СРАЗУ ЖЕ после пункта 2 идет спрашивать у реплики то, что он записал. В этом случае асинхронная репликация могла еще не успеть завершиться, и реплика еще ничего не знает об это записи! Значит, ответ на запрос будет пустым.
В этом случае, у нас нет согласованности данных. В чем же тогда преимущество? Верно, должна быть доступность.
Предположим, что после пункта 2 у нас вообще исходный хост, на который мы писали, отвалился. Например, вырубилась сеть. Значит, и реплика не успела получить новую запись, но (!) реплика продолжает работать! Да, в данных есть какая-то неконсистентность, но наша система в целом доступна, потому что мы можем спокойно общаться с репликой - она рабочая.
Уберем доступность
Давайте попробуем переместить нашу систему на другое ребро треугольника - потребуем доступность и устойчивость к разделению, но пожертвуем согласованностью.
Что же делать, если после пункта 2 клиент таким же образом обратился к новой записи на реплику? Скорее всего, просто ждать, пока завершится репликация! Потому что мы не имеем права сказать, что данных нет, потому что это будет неконсистентно.
А что делать, если точно так же после записи и до репликации первый хост отказал? Ни-че-го! Сказать, что этой записи на втором хосте нет, мы не можем - опять же, из-за согласованности. Мы можем только ответить "система недоступна, подождите, когда все наладится". Таким образом, мы отказались от доступности, но у нас появилась согласованность!
Выводы
У треугольника теоремы САР есть три стороны:
Первая - это AC (availability, consistency). Как правило, это - реляционные базы данных. Классические базы, к которым Вы все привыкли. Их главная проблема - трудность масштабирования. Примеры: MySQL, MariaDB, Postgres, Oracle и др.
Базы данных, которые расположились на двух других сторонах, как правило, относятся к классу NoSQL (Not Only SQL). Их главное преимущество - относительная простота в горизонтальном масштабировании.
Сторона AP (availability, partition tolerance) - масштабируемые решение, которые предоставляют высокую доступность в ущерб согласованности данных. Примеры: Clickhouse, Cassandra.
Сторона CP (consistency, partition tolerance) - обычно это базы данных, имеющие единую точку отказа. То есть с согласованностью данных здесь все в порядке, но в жертву приносится высокая доступность. Примеры: HBase, MongoDB, Redis.
Если Вам была полезна данная статья, ставьте "палец вверх" и подписывайтесь. Также, пишите в комментариях, какие бы еще темы вы хотели расмотреть