Рассмотрим один из способов распределения объектов по группам - агломеративную кластеризацию в Python. Она является разновидностью иерархического алгоритма и заключается в последовательном объединении точек в кластеры. При этом сначала каждый объект лежит в отдельной группе, после на каждом шаге самые близкие кластеры объединяются на основании выбранных метрик расстояния.
В качестве дистанций между кластерами часто принимают:
- максимальное расстояние между двумя точками одно и другого кластера (полная связь);
- минимальное расстояние между двумя точками одно и другого кластера (одиночная связь);
- среднее расстояние между парами точек одно и другого кластера (средняя связь);
- значение совокупной внутрикластерной ошибки при объединении (метод уорда).
В качестве метрики расстояния между точками обычно используется евклидова мера (также поддерживается много других, например, корреляция, косинусное различие).
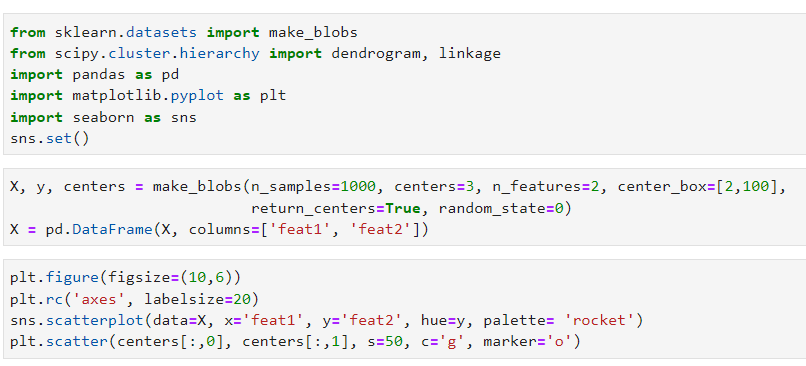
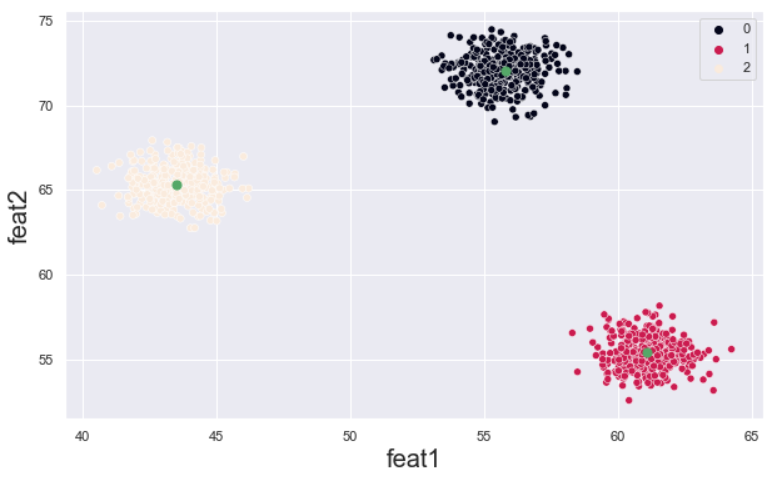
Сгенерируем и визуализируем набор данных (читай подробнее):
Для построения дерева иерархической кластеризации потребуется сначала провести расчеты функцией linkage, а затем отобразить их функцией dendrogram (обе из scipy.cluster.hierarchy):
Для отображения потребуется link_df передать в dendrogram:
По вертикальной оси дендрограммы отображается дистанция между кластерами, то есть чем ближе к вершине, тем она больше. На основании этого рисунка можно выбрать количество кластеров, на которое разумно поделить данные (здесь, очевидно, 3).
Теперь предскажем кластер для каждой точки данных с классом AgglomerativeClustering из sklearn.cluster:
Как видим, с данным примером алгоритм справляется успешно. Параметры linkage и affinity имеют смысл упоминавшихся ранее способов подсчета расстояний между кластерами и парами точек.