Платформа Jetson AGX Orin была представлена в конце марта. Как считает NVIDIA, это лучшее компактное, экономичное, но при этом весьма высокопроизводительное решение для робототехники и автономных транспортных средств, использующих современные ИИ-решения. На это у компании есть основания.
Сердцем платформы является 7-нм чип (17 млрд транзисторов), включающий в себя 12 ядер Arm Cortex-A78AE, специально спроектированных для применения в задачах, требующих повышенной надёжности. GPU-часть представлена 2048 ядрами Ampere и 64 тензорными ядрами. В полной версии такой чип развивает 275 Топс на вычислениях INT8 при частоте 2,2 ГГц для CPU и 1,3 ГГц для GPU, но NVIDIA предлагает несколько решений на базе новой архитектуры.
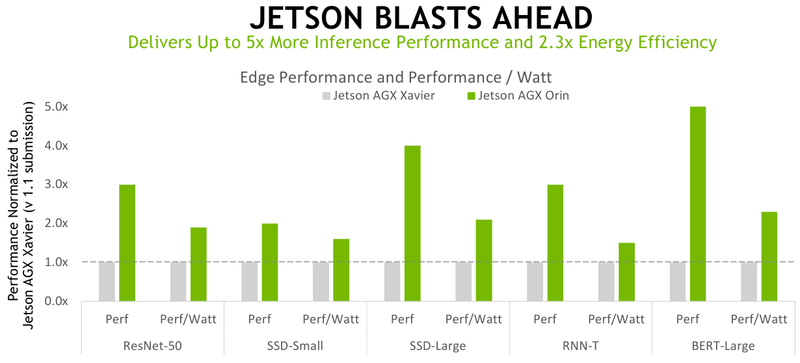
Старшая версии в пять раз быстрее и в два раза энергоэффективнее, нежели Jetson AGX Xavier — компания привела результаты тестирования AGX Orin в MLPerf Inference V2.0, где новая платформа без труда расправилась со своей предшественницей, а также не оставила практически ни единого шанса связке Qualcomm Snapdragon 865 и Cloud AI 100 (DM.2). Впрочем, старший серверный вариант ускорителя всё же оказался более энергоэффективным в сравнении с NVIDIA A100 в некоторых других тестах.
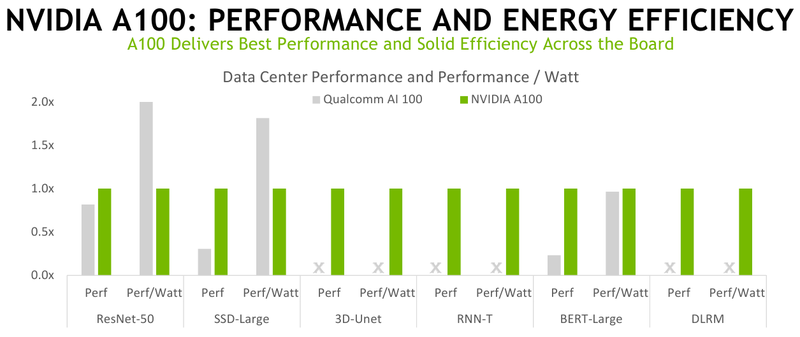
Дополнительно NVIDIA опубликовала результаты тестов ускорителя A30. Компания отдельно подчёркивает несколько моментов. Так, производительность A100 на платформах Arm и x86-64 оказалась практически идентичной — трёхлетние усилия по портированию ПО на Arm не прошли даром. Более того, оптимизация одного только ПО дала прирост до 50% за последний год. Заодно NVIDIA объявила, что теперь инференс-платформа Triton может работать только на CPU, не требуя обязательного наличия GPU.
Также NVIDIA совместно с Microsoft показала, что производительность A100 в инстансах Azure незначительно отличается от того, что можно получить при использовании bare-metal оборудования. Наконец, компания продемонстрировала эффективность работы Multi-Instance GPU (MIG) — при использовании всех семи инстансов производительность каждого составляет порядка 98% от той, которая доступна при использовании только одного инстанса.
К сожалению, сам набор MLPerf всё ещё во много ориентирован на аппаратные решения NVIDIA — в новой серии тестов очень мало результатов от других крупных игроков, хотя всего было принято более 3900 замеров, из которых 2200 включали также данные об энергопотреблении. Та же Qualcomm выступила далеко не во всех дисциплинах, а Google фактически отказалась от участия в этом раунде.