Рассмотрим рекомендации работы с числовыми типами в Pandas, чтобы сэкономить память и процессорное время при обработке данных. В первую очередь, для этого следует не допускать выделения избыточных ресурсов под ваш датафрейм, что происходит по умолчанию. Система допускает такую "оплошность", так как не знает пределы значений чисел в колонках.
Эту задачу следует решить вам. Чтобы подыскать нужный тип, сначала вспомните диапазоны вмещаемых значений, для чего можете обратиться к функциям библиотеки NumPy - iinfo (целые числа) и finfo (дробные):
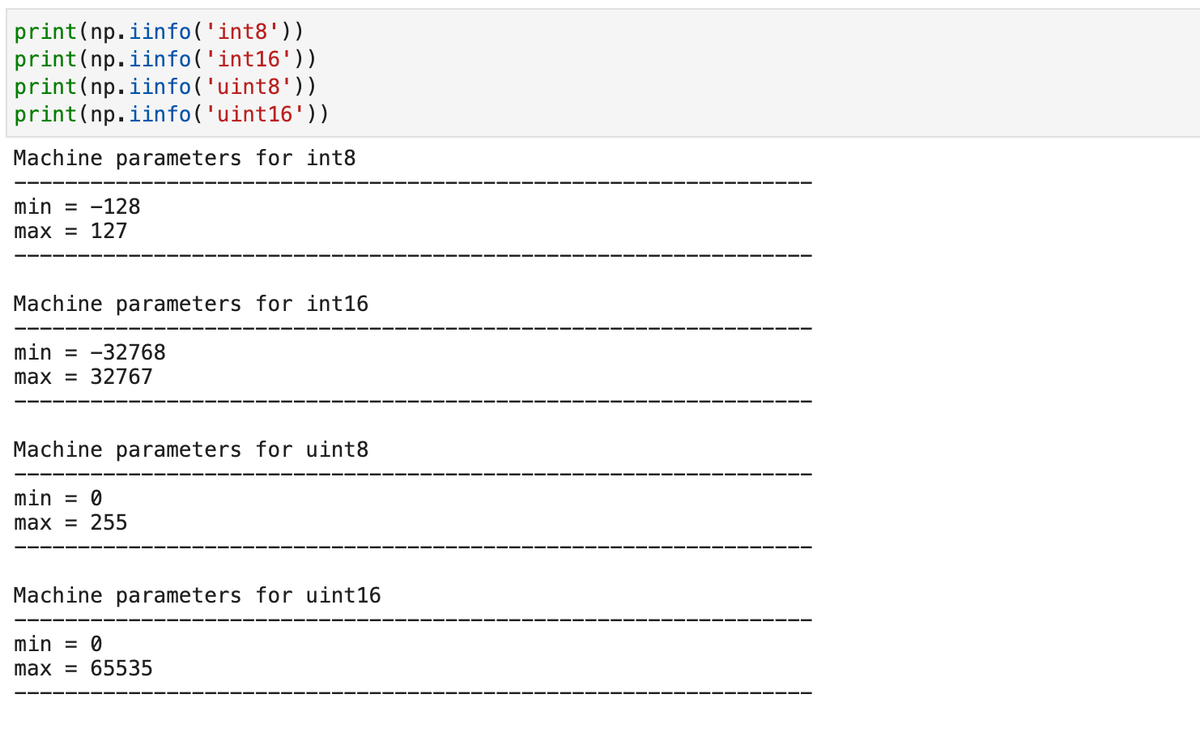

Теперь, чтобы выбрать нужный тип, оцените пределы допустимых значений в вашей колонке, в чем поможет отображение текущих максимума и минимума :
Для задания требуемого типа воспользуйтесь либо параметром dtype при создании датафрейма (серии), либо методом astype для преобразования уже имеющегося объекта:
Обратите внимание, что значения, выходящие за пределы допустимых, заменяются на -inf и inf. Также замечу, что по умолчанию для дробных чисел тип колонки устанавливается в float64:
Для преобразования целочисленных столбцов до "ближайшего" по размеру типа можете использовать функцию Pandas to_numeric с параметром downcast='integer':