Это перевод оригинальной статьи от Jesus Castello.
Что такое структура данных?
Структура данных — это особый способ организации и доступа к данным.
Примеры:
- массивы
- бинарные деревья
- хэши
Различные структуры данных отлично справляются с разными задачами.
Например, хэши хороши, если вы собираетесь хранить данные, которые похожи на словари (слова и их определения), или как список контактов (имя и номер телефона).
Знания о том, какие бывают структуры данных, и какие они имеют характеристики, делает вас лучшим Руби-разработчиком.
Это то, что вы будете знать, прочитав эту статью.
Понимание массивов
Массив — это первая структура данных, которую вы изучите, когда приметесь изучать программирование.
Массивы используют смежные ячейки памяти, где объекты расположены один за другим без разрывов между ними.
В отличие от низкоуровневых языков программирования, таким как C, Руби делает за программиста всю сложную работу по управлению памятью, увеличивая максимальный размер массива и уменьшая его, когда вы удаляете элементы.
Используется:
- Как база для более расширенных структур данных
- Для сбора результатов в исполняемом цикле
- Для сбора коллекций
Массивы есть повсюду, в чём можно убедиться, использовав методы split и chars, которые разбивают строку на массив символов.
Пример создания массива:
Ниже показано, как различные операции над массивами ведут себя по мере увеличения размера массива.
Если вы недостаточно знаете о нотации временно́й сложности алгоритмов, прочитайте эту статью.
Временна́я сложность операций над массивами:
- вставить — O(1)
- взять — O(1)
- получить доступ — O(1)
- найти — O(n)
- удалить — O(n)
Почему это может помочь?
Потому что это показывает вам производительность операций над массивами.
Если вы производите множество операций поиска (find) на БОЛЬШОМ массиве, это будет выполняться медленно…
Но, если вы знаете какие индексы вам нужны, то эти операции будут проходить быстро, потому что имеют временну́ю сложность O(1).
Выбирайте нужную вам структуру данных, руководствуясь следующими критериями:
- Характеристики производительности → Что вы планируете делать с данными? Насколько велик размер набора данных?
- Структура ваших данных → С данными какого типа вы работаете? Можете ли вы реорганизовать ваши данные, чтобы улучшить их структуру?
Структура данных хэш
Вам нужно сопоставить коды стран и их названия?
Или, может быть, вам нужно просто что-то подсчитать.
Это именно то, для чего созданы хэши!
Хэш — это структура данных, в которой каждое значение соответствует ключу, а ключом может быть всё что угодно — строка, число, символ и так далее.
Как это работает?
Хэш конвертирует ваш ключ в число (используя метод hash из Руби), а затем использует этот номер как индекс. Но вы должны это понимать, чтобы использовать хэши в своих программах на Руби.
Используется:
- Для подсчёта количества символов в строках
- Для сопоставления слов с их определениями, имён и телефонных номеров, и так далее
- Для поиска дубликатов внутри массивов
Пример:
Временна́я сложность:
- сохранить — O(1)
- получить доступ — O(1)
- удалить — O(1)
- найти по значению — O(n)
Хэши одна из самых полезных структур данных, когда речь заходит о производительности, потому что функции сохранения (store), удаления (delete) и доступа (access) имеют константную временну́ю сложность.
Поиск в контексте хэша означает то, что вы ищете какое-то определённое значение.
Стеки
Стек похож на стопку плиток, вы кладёте одну плитку наверх и вы можете взять за один раз только одну плитку сверху.
Это гораздо более полезно, чем выглядит поначалу!
Используется:
- Для замены рекурсивных методов обычным циклом
- Для слежения за оставшейся работой, оставляя последнюю сверху
- Для реверса массива
Пример:
Конечно, вы можете использовать для этого метод reverse.
Это только лишь пример, показывающий вам эту особую характеристику стеков.
Временна́я сложность:
- вставить — O(1)
- забрать — O(1)
- найти — нет
- получить доступ — нет
Заметьте, что стеки (и очереди) имеют только две операции — вставка и удаление, или push и pop.
Как использовать бинарные деревья
Многие Руби-разработчики возможно слышали про бинарные деревья, но никогда не использовали их.
Что это такое?
Первое, у нас нет встроенной реализации бинарных деревьев.
Второе, бинарные деревья не так уж полезны для повседневных задач программирования, в отличие от массивов и хэшей, которые используются ВСЁ время.
Но бинарные деревья очень интересная структура данных.
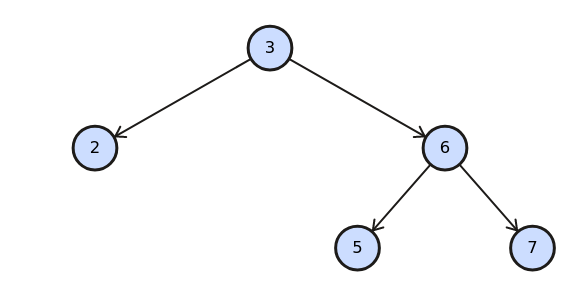
Фактически, существует много вариантов, таких как Trie (описано в следующем разделе), многовариантные деревья, такие как B-Tree (используется в базах данных) и Heap.
Используется:
- Для сжатия данных
- Для построения таблиц маршрутизации
- Для построения абстрактных синтаксических деревьев
Пример:
Временна́я сложность:
- вставка — O(log n)
- удаление — O(log n)
- поиск — O(log n)
- получить доступ — нет
Сбалансированное бинарное дерево получается тогда, когда у всех узлов есть по два дочерних элемента, а все листья имеют одинаковый уровень.
Если дерево становится несбалансированным, его производительность деградирует до O(n).
В самобалансирующихся бинарных деревьях (таких, как красно-чёрное дерево, или дерево AVL), каждая операция занимает время, пропорциональное высоте (или уровню) дерева.
Обратите внимание, что не указано время для получения доступа, потому что для доступа к узлу сначала нужно его найти...
В этом случае вы потратите O(log n) на получение доступа.
Но если сохранить ссылку (как переменную) на найденный узел, то время доступа к нему сократится до O(1).
Структура данных Trie
Trie — это специализированная древовидная структура данных.
Она полезна для работы со словами, а также для быстрого поиска слов начинающихся с префикса, или для поиска полного слова.
Используется:
- Для игр в слова
- Для проверки орфографии
- Для предложения автозавершения слов
Пример:
Временна́я сложность:
- добавление — O(k)
- включено? — O(k)
- слова — O(k)
В этом списке я использовал k для нотирования размера входной строки, в то время как n используется для нотирования размера самой структуры данных.
Таким образом, для слова apple, k будет равно 5.
Выводы
Вы изучили основные структуры данных, их главные способы использования и характеристики, а также, как их можно использовать в Руби.
Когда вы применяете новые знания, вы становитесь способны решать проблемы быстрее.
Спасибо, что прочитали до конца!