
Привет всем! Я буквально нутром чую, что очень зря лезу между двумя лагерями безумных фанатов, но рано или поздно я должен был выпустить хотя бы одну статью на эту тему. Любой уважающий себя техно-блогер, минимум раз в жизни пытался поставить точку в извечном вопросе борьбы "зеленых" и "красных". Каждый "юзер", в свою очередь, минимум раз в жизни задавался вопросом "что же лучше взять - Nvidia или AMD?".
Давайте сразу договоримся, это не будет статья из разряда "оба варианта по-своему хороши". Ну знаете, есть такие гадкие материалы, которые читаешь полчаса, а в конце автор заявляет, что явного победителя нет. Я буду с вами честен и обещаю, что объявлю лидера. Более того, я очень постараюсь объяснить и обосновать каждое свое умозаключение. Никакого субъективизма и предвзятости. Только сухие, голые факты.
Предлагаю вам выстроить обзор по схеме нескольких разделов, выявить сильнейшего по каждому пункту, а затем просто посчитать набранные каждой стороной баллы. Надеюсь, что такой вариант всех устраивает. Если у вас потом останутся какие-то вопросы, предложения, замечания, возражения или что-то еще, то рад буду пообщаться в комментариях. Вроде, все формальности соблюдены, план намечен, можно начинать.
Предупреждаю сразу, сегодняшний материал будет насыщен терминами и числами, трудными для восприятия рядовых пользователей. Если вы не хотите вдаваться в такие подробности, то просто ждите следующую часть статьи. Там все будет проще, и я подведу окончательный итог. Ну а если вы технарь или энтузиаст, то устраивайтесь поудобнее. Очень надеюсь, что собранная мной информация будет полезна и расширит ваш кругозор.
1. ГРАФИЧЕСКИЙ ПРОЦЕССОР.
Начнем с самого главного и самого сложного фактора, определяющего производительность видеокарт. Это, конечно же, графический процессор. Как вы знаете, название нынешнего поколения графических процессоров Nvidia - Ampere. В топовые модели современных видеокарт (RTX3080, RTX3080Ti, RTX3090) устанавливается GA102. Площадь чипа составляет 628 квадратных миллиметров, в нем 28,3 миллиарда транзисторов.
Лагерь AMD на данный момент представлен графическими процессорами RDNA2. Последний из них (Navi 21) имеет площадь всего 520 квадратных миллиметров, в нем 26,8 миллиарда транзисторов. При этом, чипы Nvidia производятся по 8-ми нанометровой технологии Samsung, а чипы AMD - по 7-ми нанометровой технологии TSMC. Нетрудно посчитать плотность. Она составляет 41,1 млн транзисторов на квадратный миллиметр у Nvidia.
У AMD этот показатель равен 51,5 млн транзисторов на квадратный миллиметр. Вроде бы, можно похвалить AMD за грамотное использование ресурсов - их чип меньше по площади, но, при этом, у них более тонкий техпроцесс и большая плотность транзисторов. Но не все так однозначно. Помимо физических различий, есть еще и нюансы, вроде компоновки элементов, энергоэффективности, тепловыделения и многого другого.
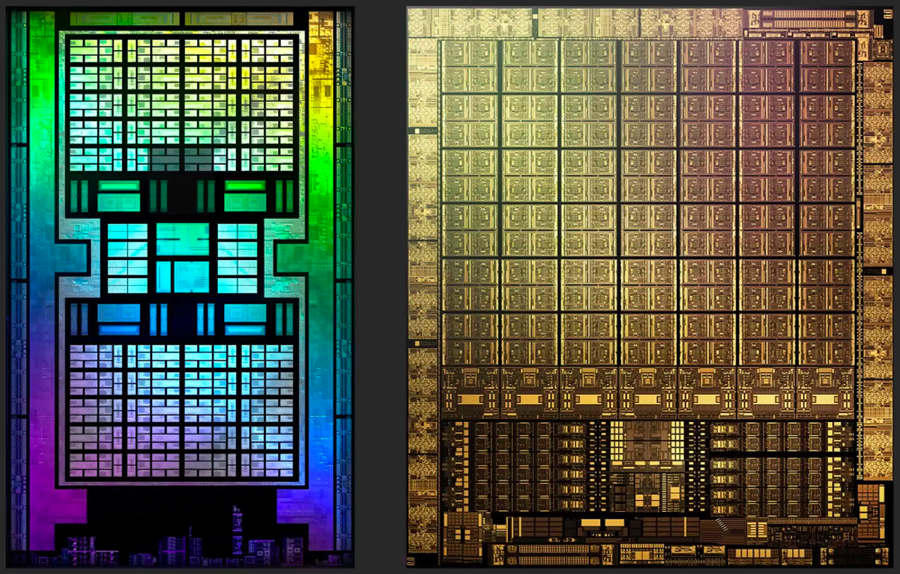
Взгляните на изображения кристаллов. Они могут помочь нам понять, какой логикой руководствовались инженеры, так или иначе располагая различные составляющие. Первое, что бросается в глаза - это необычная структура Nvidia. Системные контроллеры и основной кэш находятся внизу, а логические блоки расположены в длинных столбцах. AMD, в свою очередь, применяет централизованный подход к компоновке микросхем.
В этом месте стоит задаться вопросом "зачем Nvidia применила столь необычный подход?". Интерфейсы здесь ни при чем, ведь контроллеры памяти и PCI Express работают на краю кристалла. С тепловыделением это тоже не связано, ведь даже если кэш-часть или контроллер кристалла будут нагреваться сильнее, чем логические секции, то гораздо проще было бы разместить в центре побольше теплопоглощающего кремния.
Причина такой компоновки не совсем понятна, но, возможно, она связана с реализацией блоков вывода рендеринга (ROP). В любом случае, можно сказать, что изменение макета не оказывает серьезного влияния на производительность. Это связано с тем, что 3D-рендеринг практически всегда сопровождается большим количеством длительных задержек. Как правило, из-за необходимости ожидания данных (или других причин).
В итоге, дополнительные наносекунды, добавленные за счет того, что некоторые логические блоки находятся дальше от кэша, не играют существенной роли. Если вы спросите про инженерные решения, которые реализовала AMD в компоновке Navi 21, то здесь стоит отметить, что применив стандартный централизованный подход, им удалось улучшить тактовые частоты, без значительного увеличения энергопотребления.
Оба производителя стремятся улучшить такой важный параметр, как "производительность на ватт", и у обоих это получается. Но если вы обратите внимание на динамический прогресс от поколения к поколению, то поймете, что AMD развивается в этом направлении гораздо более широкими шагами. Всего за два года совместной работы AMD и TSMC увеличили этот показатель на 64% (если сравнивать Radeon VII и 6800XT).
Мой вердикт - балл переходит к Nvidia. Да, AMD сделали огромный технологический скачок в своем нынешнем поколении видеокарт. Коллаборация с TSMC пошла им на пользу. Значительно подтянулась энергоэффективность. Но в лобовом столкновении "зеленые" все еще впереди. Как бы ни были хороши процессоры Navi 21, GA102 все равно лучше. Возможно не во всех аспектах, но в сумме составляющих точно.
2. СИСТЕМА ПАМЯТИ И КЭШ.
Для начала, взглянем на Ampere. По сравнению с прошлым поколением, здесь произошли довольно заметные изменения: объем кэша 2-го уровня увеличился на 50%, а кэши 1-го уровня в каждом SM (потоковый мультипроцессор) увеличились вдвое. Совсем неплохо. Как и раньше, кэш-память L1 настраивается здесь, с точки зрения того, сколько места в кэше можно сейчас выделить для данных, текстур или общих вычислений.
Для графических шейдеров (например, вершинных или пиксельных) и асинхронных вычислений кэш фактически установлен на 64 КБ для данных и текстур; на 48 КБ для общей памяти; на 16 КБ для конкретных операций. Остальная часть внутренней памяти не изменилась. Но за пределами графического процессора нас ждет приятный сюрприз. Благодаря Micron, NVIDIA использует GDDR6X для своих потребностей в локальной памяти.
По сути, это тот же GDDR6, но шина данных полностью заменена. Вместо того, чтобы использовать обычную настройку 1 бит на вывод, при которой сигнал очень быстро колеблется между двумя значениями напряжения (PAM), GDDR6X использует четыре значения напряжения. То есть GDDR6X эффективно передает 2 бита данных на вывод за цикл, поэтому при той же тактовой частоте и количестве выводов полоса пропускания удваивается.
Например, RTX3090 поддерживает 24 модуля GDDR6X, которые работают в одноканальном режиме и рассчитаны на 19 Гбит/с, что дает пиковую пропускную способность 936 ГБ/с. Это на 52% больше, чем у RTX2080Ti. AMD пошла по другому пути: вместо того, чтобы обращаться за помощью к стороннему поставщику, они просто использовали свое собственное подразделение ЦП, чтобы придумать достойный ответ для Nvidia и Micron.
Общая система памяти в RDNA 2 не сильно преобразилась по сравнению с предшественницей — но есть два существенных изменения. Каждый шейдерный движок теперь имеет два набора кэшей первого уровня. Но как вообще можно втиснуть в графический процессор 128 МБ кэш-памяти третьего уровня? Как выяснилось, легко. Используя конструкцию SRAM для кэша L3, AMD встроила в чип два набора кэш-памяти объемом 64 МБ.
Транзакции данных обрабатываются 16 наборами интерфейсов, каждый из них сдвигает 64 байта за такт. Так называемый Infinity Cache имеет свой собственный тактовый домен и может работать на частоте 1,94 ГГц, что дает пиковую внутреннюю пропускную способность 1986,6 ГБ/с. А так как это не внешняя DRAM, то задержки здесь предельно низкие. Такой кэш идеально подходит для хранения структур ускорения трассировки лучей.
Какой же из всего этого можно сделать вывод? Давайте проанализируем рассмотренные данные. Использование GDDR6X дает GA102 огромную полосу пропускания для локальной памяти, а большие объемы кэша помогают уменьшить влияние "промахов". Массивная кэш-память 3-го уровня Navi 21 позволяет реже использовать DRAM, при этом ГП может даже работать на более высоких тактовых частотах без дефицита данных.
Теоретически, использование нескольких уровней встроенной SRAM обеспечивает более низкие задержки и лучшую производительность для заданного диапазона мощности, чем внешняя DRAM, независимо от пропускной способности последней. Но, на практике, подавляющее большинство тестов показывают явное преимущество GA102 перед Navi 21. Еще один балл улетает к "зеленым". Счет становится 2:0, идем дальше.
3) ПОДСЧЕТ ЯДЕР И ТРАССИРОВКА ЛУЧЕЙ.
По заявлениям Nvidia, Ampere имеет более чем в два раза большее количество ядер CUDA в каждом SM, чем Turing (в общей сложности 128). Но, если разобраться, то на практике, это не так. Раньше блоки INT32 могли обрабатывать значения с плавающей запятой, но в небольшом количестве простых операций. Сейчас Nvidia увеличила поддерживаемый диапазон математических операций с плавающей запятой. Что это дало?
Теперь INT32 соответствуют другим модулям FP32. Это означает, что общее количество ядер CUDA на SM не изменилось, просто половина из них теперь имеет больше возможностей. Поскольку блоки INT/FP могут работать независимо, SM Ampere может обрабатывать до 128 вычислений FP32 за цикл или 64 операций FP32 и 64 операций INT32 одновременно. Это неплохо, ведь Turing в свое время умела делать только последнее.
Таким образом, новый графический процессор может потенциально вдвое увеличить производительность FP32 по сравнению с предком. Для вычислительных рабочих нагрузок это большой шаг вперед, но для игр польза окажется гораздо меньшей. Для примера, возьмем RTX3080. Ее пиковая пропускная способность FP32 на 121% превосходит RTX2080Ti. Но средний прирост FPS в современных играх составляет "скромные" 31%.
Так почему же вся эта вычислительная мощность тратится зря? На самом деле, зря она не тратится, просто игры не всегда запускают инструкции FP32. Около 36% инструкций, обрабатываемых ГП, связаны с процедурами INT32. Эти вычисления обычно выполняются для определения адресов памяти, сравнения двух значений и логического управления. Для этих операций функция двойной скорости FP32 попросту не используется.
Все из-за того, что блоки с двумя путями данных могут работать только с целыми числами или с плавающей запятой. Значит, SM переключится в этот режим только тогда, когда все выстроенные в очередь 32 потока, обрабатываемые им в данный момент, выполняют одну и ту же операцию FP32. В итоге, преимущество FP32 в RTX3080 над RTX2080Ti, при работе в режиме INT+FP, составляет 11%. Поэтому, в играх разрыв не столь велик.
Какие еще есть улучшения? Например, на каждый SM приходится меньше тензорных ядер, но каждое из них оказывается намного более мощным, чем в Turing. Эти схемы выполняют очень специфические вычисления (например, умножают два значения FP16 и складывают ответ с другим FP16), и теперь каждое ядро выполняет 32 таких операции за цикл. Также, появилась поддержка такой функции, как Fine-Grained Structured Sparsity.
Если кратко, то с ее помощью математическая скорость может быть удвоена путем удаления данных, которые не влияют на ответ. Опять же, это хорошая новость для профессионалов, работающих с нейронными сетями и искусственным интеллектом, но, на данный момент, в этом нет никаких значительных преимуществ для игровых разработчиков. Ядра трассировки лучей теперь могут работать независимо от ядер CUDA.
То есть, пока они выполняют обход BVH или математику пересечения примитивов лучей, остальная часть SM все еще может обрабатывать шейдеры. Часть ядер трассировки лучей, отвечающая за проверку пересечений, также имеет вдвое большую производительность. Ядра трассировки лучей также оснащены дополнительным оборудованием, которое помогает применять трассировку лучей к размытию движения.
Но эта функция в настоящее время доступна только через собственный Optix API от NVIDIA. Что же ответит AMD? Вычислительные блоки по-прежнему содержат два набора векторных блоков SIMD32, скалярный блок SISD, блоки наложения текстур и стек различных кэшей. Произошли изменения в отношении того, какие типы данных и связанные с ними математические операции они могут выполнять. Но есть и еще кое-что.
AMD теперь предлагает аппаратное ускорение для определенных процедур трассировки лучей. Эта часть вычислительных блоков выполняет проверки пересечения лучевого бокса или лучевого треугольника. Однако, ядра трассировки лучей в Ampere дополнительно ускоряют алгоритмы обхода BVH, тогда как в RDNA 2 это делается с помощью вычислительных шейдеров с использованием модулей SIMD 32.
Учитывая, что ядра трассировки лучей NVIDIA теперь работают полностью независимо от остальной части SM, это дает Ampere явное преимущество по сравнению с RDNA 2 в проработке структур ускорения и тестах пересечений, необходимых для трассировки лучей. Вычислительные блоки в RDNA 2 теперь поддерживают больше типов данных: наиболее заметными из них являются типы данных с низкой точностью (INT4, INT8).
Они используются для тензорных операций в алгоритмах машинного обучения. AMD имеет отдельную архитектуру (CDNA) для ИИ и центров обработки данных, но это обновление предназначено для использования с DirectML. Сочетание аппаратного и программного обеспечения улучшает шумоподавление в алгоритмах трассировки лучей и временного масштабирования. В случае с последним, у NVIDIA, конечно же, есть DLSS.
Она использует тензорные ядра в SM для выполнения части вычислений. Аналогичный процесс может быть построен и через DirectML, но в Ampere тензорные ядра также обрабатывают все математические операции, связанные с форматами данных FP16. В RDNA 2 подобные вычисления выполняются с использованием шейдерных блоков и упакованных форматов (32-битный векторный регистр содержит два 16-битных).
Давайте подытожим. AMD преподносит блоки SIMD32, как векторные процессоры - они выдают одну инструкцию для нескольких значений данных. Векторный блок содержит 32 потоковых процессора. Каждый из них работает с одним фрагментом данных, поэтому операции носят скалярный характер. По сути, это почти то же самое, что и SM в Ampere, где блок обработки применяет одну инструкцию для 32 значений данных.
У Nvidia весь SM может обрабатывать до 128 вычислений FMA FP32 за цикл. Один вычислительный блок RDNA 2 производит только 64 таких вычисления. SM Nvidia могут выполнять инструкции для одновременной обработки целочисленных значений и значений с плавающей запятой (например, 64 FP32 и 64 INT32), а также имеют независимые блоки для операций FP16, тензорной математики и процедур трассировки лучей.
Блоки управления AMD выполняют большую часть рабочей нагрузки блоков SIMD32, хотя у них есть отдельные скалярные блоки, которые поддерживают простую целочисленную математику. Таким образом, у Ampere здесь преимущество. У GA102 больше SM, чем у Navi 21. Плюс больше возможностей, когда дело доходит до пиковой пропускной способности, гибкости и предлагаемых функций. Счет становится 3:0.
ПРОДОЛЖЕНИЕ СЛЕДУЕТ.
Дорогие друзья, если вы любите хорошую авторскую литературу (особенно в жанрах фэнтези и мистика), то я бы хотел порекомендовать вам почитать рассказы и роман моих близких друзей Ирины Захаровой и Екатерины Балашовой.
https://author.today/work/149935
Спасибо за внимание!
История о том, как я купил Palit GeForce RTX 3080 Ti GamingPro в ДНС по рекомендованной цене. Без шуток. Распаковка прилагается.
Лучшие игровые и профессиональные ноутбуки на процессорах серии Intel Core i9 10000.
Лучшие игровые и профессиональные ноутбуки на процессорах серии AMD Ryzen 9 5000.
Разбираем магазинные сборки ПК до 50 тысяч рублей. Стоят ли они своих денег?
Можно ли купить нормальную видеокарту в 2022 году за разумные деньги? Проверяем доступность и цены. Часть 2.
