Рассмотрим продвинутые способы борьбы с ошибками при обработке данных в Pandas. В демонстрационных целях создадим следующий файл:

Чтение файла с испорченной структурой
Так как структура файла в пятой строке отличается от ожидаемой (три столбца, разделенные символом табуляции), то попытка прочитать его вызовет ошибку:
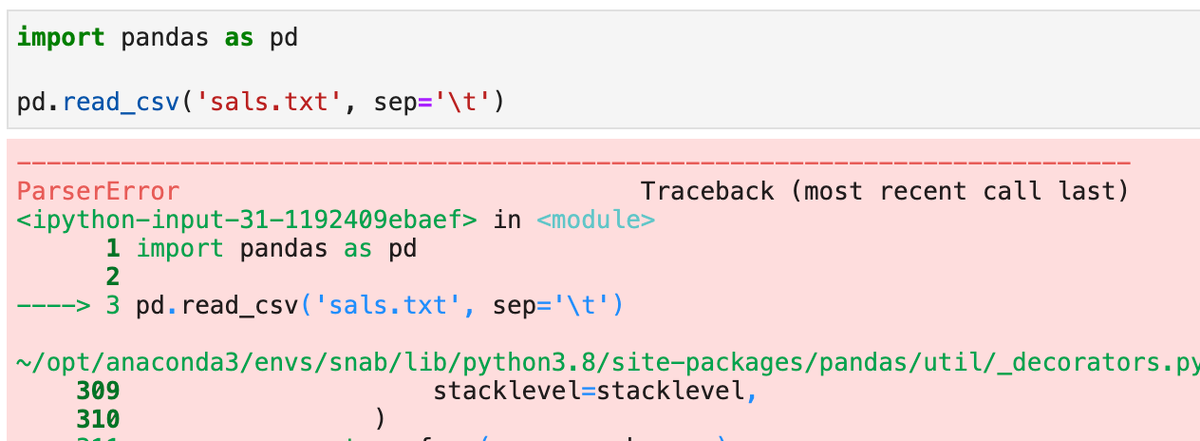
Чтобы отфильтровать "грязные строки" и загрузить оставшиеся в датафрейм, в методе read_csv предусмотрен "волшебный" параметр on_bad_lines, который позволяет изменить поведение по умолчанию и вместо вывода ошибок проигнорировать их с опцией напечатать предупреждение:
Преобразование полей с нетекстовыми типами
Попытаемся привести колонку 'дата_получения' к формату даты:
Получаем ошибку, так как некоторые поля столбца (в частности, первое) не удовлетворяют формату. Чтобы заглушить исключение и сделать преобразование для "нормальных" значений воспользуемся параметром errors='coerce':
"Ошибочные" значения заменятся на NaT . По этому признаку можно их выявить и применить дополнительные преобразования к исходному столбцу:
Аналогичный параметр errors содержит функция to_numeric, преобразующая поля в числа: