Одно из самых важных дискретных вероятностных распределений — геометрическое. Обсудим его и один способ, как с его помощью получать быстрые ответы на сложные вопросы.
Итак, сама случайная величина имеет смысл числа попыток до первой удачной, а вероятность удачи в каждой попытке равна p. Вероятность неудачи 1-p обозначим q. Так что возможные значение — это натуральные числа n от 0 и далее, а вероятности этих значений равны p, pq, pq² и так далее.

Легко проверить, что сумма таких вероятностей дает единицу. В самом деле, общий множитель p можно вынести и получить сумму геометрической прогрессии 1+q+q²+..., сумма которой по формуле есть 1/(1-q)=1/p. В итоге и получится 1.
Видимо, потому и геометрическое распределение, что основано на геометрической прогрессии.
Математическое ожидание, то есть сумму значений, умноженных на их вероятности, посчитать чуть сложнее. Но можно:
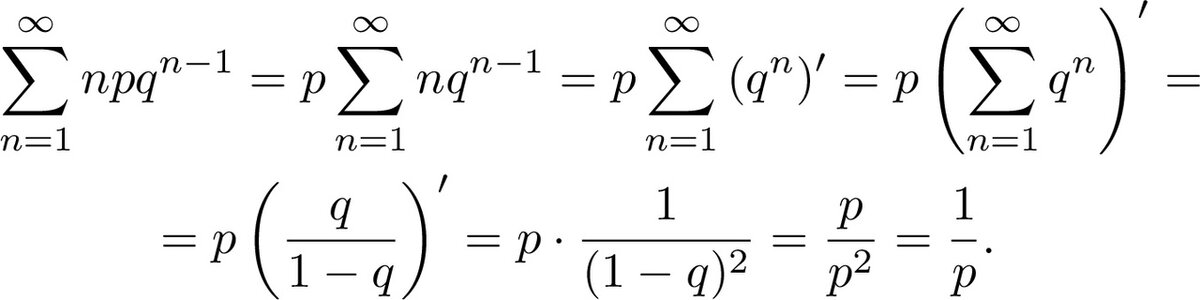
Итак, среднее обратно вероятности успеха в отдельной попытке, что любопытно. При равных шансах на успех и неудачу получается в среднем 2 попытки до успеха...
Это распределение обладает свойством потери памяти, наряду с экспоненциальным. Я об этом уже рассказывал, но повторюсь. Найдем вероятность того, что случайная величина (число попыток) не меньше m+M, причем M попыток уже сделано. По формуле условной вероятности, надо поделить вероятность того, что попыток не меньше и M, и M+m (то есть просто не меньше M+m) на вероятность того, что их не меньше M.
Вероятность того, что попыток не меньше M, равна сумме вероятностей для n=M и далее до бесконечности. Это прогрессия со знаменателем q и первым членом pqᴹ. Ее сумма равна qᴹ.
Аналогично, для M+m вероятность, что попыток не меньше, выражается той же формулой с заменой M в показателе на M+m: qᴹ⁺ᵐ. Деление одной на другую, по свойству степени, дает qᵐ. А это не что иное, как вероятность события "попыток не меньше m".
То есть, вероятность, что попыток надо "ещё m" равна вероятности того, что их изначально понадобится m. То есть история попыток роли не играет. Распределение не имеет памяти.
Таких распределений не так много. На самом деле, одно дискретное и одно непрерывное (экспоненциальное, брат-близнец геометрического).
Теперь как знание этого распределения может помочь. В недавней заметке мы решили ряд задач на игру в орлянку, в том числе и такую, которую я изложу в иных терминах.
Человек регулярно покупает актив и ждет, пока тот либо подешевеет на А рублей, либо подорожает на В рублей. И фиксирует убыток либо прибыль, продавая актив. Вероятность повышения цены на рубль равна 0.5 для простоты. Мы знаем, что вероятность получить прибыль тогда равна А/(А+В), а среднее число шагов до продажи равно АВ.
Добавим к условию такое правило: сыграв на бирже такую комбинацию, человек повторяет ее, до тех пор, пока не зафиксирует прибыль. Прошлые потери его не волнуют: он ставит целью продать актив, подорожавший на В рублей, и всё тут. Каково среднее число шагов до достижения цели?
Мы получили ответ через разностные уравнения: (А+В)В. Но можно разглядеть геометрическое распределение: каждая игра является попыткой с вероятностью успеха А/(А+В). Среднее число попыток до успеха обратно к этой вероятности: (А+В)/А.
Это само по себе любопытно!
Но каждая попытка в среднем состоит из АВ шагов, то есть полное число шагов равно (А+В)В.
Всё.
Вот ещё пример. Решаем задачу: ищем фальшивую монету в сундуке, полном монет; есть вероятность просмотреть фальшивую монету. Каково среднее число проверок отдельной монеты до обнаружения фальшивой (она точно есть и ровно одна)?
Если применять тактику "проверь весь сундук, и если не нашел, то начинай сначала", то проверка сундука — это попытка, с вероятностью успеха (найти монету) q=1-p. Среднее число сундуков, которые надо проверить, равно 1/q. Каждый сундук содержит n монет, так что всего монет надо проверить n/q. Хотя в последнем сундуке фальшивая монета в среднем будет обнаружена посередине. Так что на полсундука можно скостить:
n/q - n/2
Это можно упростить до
n/2 + np/q
В самом деле, n/q - n/2 = n/2 + n/q-n = n/2 + n(1/q-1) = n/2 + n(1-q)/q = n/2 + np/q.
Получается среднее при безошибочном распознавании (n/2) плюс лишняя работа за счет ошибок: np/q. При маленькой p это приблизительно np, то есть пропроционально. Но при большой уже нет. Например, при p=0.5 получаем полтора мешка вместо половины.
А вот почему именно такая тактика — перебери всё и лишь потом начинай сызнова — оптимальна, это мы обсудим в другой раз!