Методы выявления и фильтрации дубликатов (duplicated, drop_duplicates) в библиотеке Pandas я уже освещал ранее. Вместе с тем для исследования объектов с частью одинаковых значений и понимания сути расхождений требуются дополнительные знания в части более тонкого применения функций и комбинации с другими методами.
Рассмотрим вопрос на примере игрушечного датафрейма следующего вида:
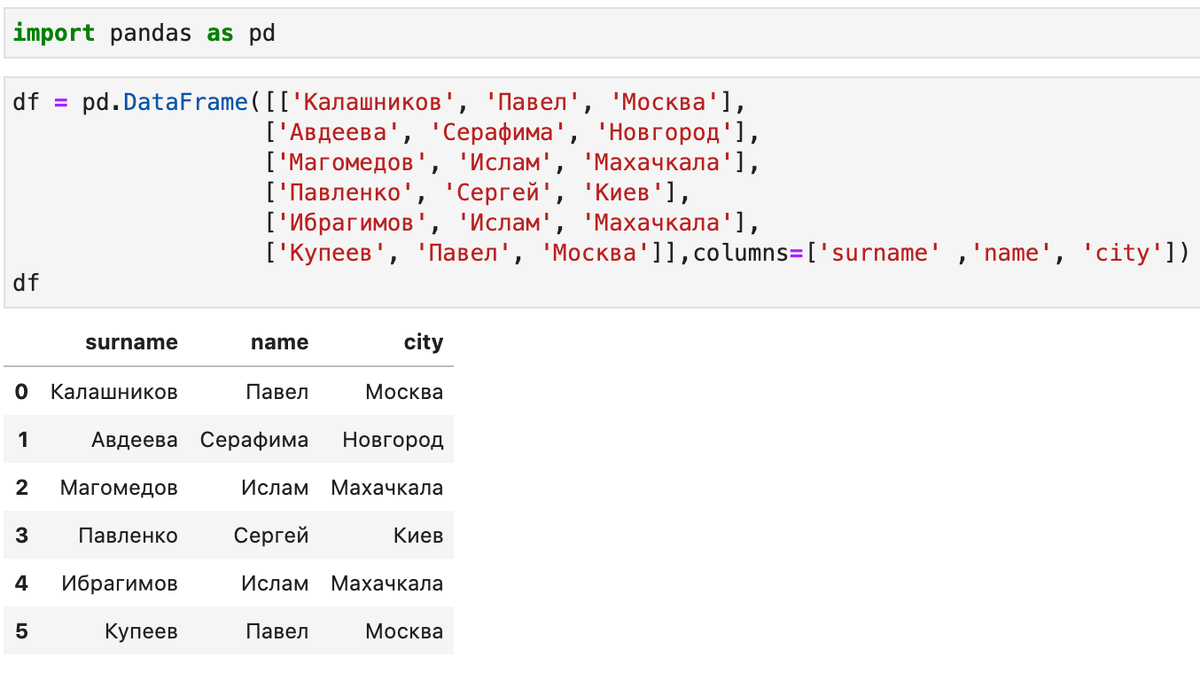
Обычный вызов duplicated приведет к пометке в качестве дубликатов и выводу только части данных (по умолчанию первые вхождения не выводятся):

Чтобы получить все дубликаты, воспользуйтесь параметром keep со значением False:
Однако, в некоторых случаях требуется сравнить объекты по части одинаковых полей (частичные дубликаты). При этом, если данных много, для удобства дополнительно воспользуйтесь сортировкой:
Другим способом нахождения дубликатов по некоторым полям является группировка:
В вышеуказанном примере мы заключаем изучаемое поле (в котором дубликаты расходятся) в множество, чтобы исключить получение одинаковых значений.