В прошлой статье мы подготовили данные, но на самом деле эта статья продолжает серию статей: тыц, тыц, тыц, тыц, тыц и тыц (получается это 8 статья). Как уже вошло в привычку, создаем новый блокнот, посмотреть который вы можете здесь. Импортируем библиотеки:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import MinMaxScaler
Мы видим новые функции из библиотеки sklearn, к объяснению которых мы подойдем чуть позже. А пока нам надо загрузить данные:
df = pd.read_csv('/content/drive/MyDrive/usdrub1.csv', index_col='DATE', parse_dates=['DATE'])
df.corr()
С функцией корреляции мы уже сталкивались. И правильнее было бы проверить корреляцию до сохранения данных в предыдущей статье, но прежде чем начать анализ следует проверить данные на правильность их использования. И первой такой проверкой будет корреляция, которая нам показывает, что все параметры очень хорошо коррелируют с валютной парой доллар / рубль, кроме нефти, которая имеет обратную корреляцию. Второй проверкой будет наличие пустых значений, хотя мы это проверяли прошлый раз. Сейчас мы сделаем это другим способом:
df.isna().count()
Убедившись в одинаковом количестве значений всех параметров, мы можем приступить к подготовке данных для машинного обучения. Первым этапом подготовки будет отделение данных от цели. Целью (целевым показателем или y), в нашем случае будет валютная пара (ruble), остальные же значения будут данными (исходными показателями или x):
y = df.ruble
x = df.drop('ruble', axis=1)
Вторым этапом будет разделение на тренировочную выборку и тестовую. При обучении модели (fit) может оказаться такая ситуация, когда модель просто "запоминает" значения, для проверки используется отдельный участок ряда, который не участвовал в обучении, который мы назовем тестовой выборкой. Для получения двух выборок воспользуемся функцией train_test_split из библиотеки sklearn:
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, shuffle=False)
print(x_train.shape, y_train.shape, x_test.shape, y_test.shape)
Вторая строка выводит размерность наших выборок. Если вы посмотрите на размерность разных параметров, то увидите, что она сильно отличается, что плохо даже с математической точки зрения, поэтому третьим этапом подготовки будет нормализация параметров, то есть приведение значений к определенному диапазону. В машинном и глубоком обучении таким диапазоном является от 0 до 1. Для этого мы воспользуемся MinMaxScaler из библиотеки sklearn:
scaler = MinMaxScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_test_scaled = scaler.transform(x_test)
print(x_train_scaled.max(), x_train_scaled.min()
Последняя команда выводит максимальные и минимальные значения нормализованных параметров, которые естественно не больше 1 и не меньше 0. Вот теперь мы можем создать модель и обучить её:
model = LinearRegression()
model = model.fit(x_train_scaled, y_train)
Обращаю ваше внимание, что целевой показатель мы не масштабируем. Получим прогнозные значения по нормализованным, после чего посчитаем среднеквадратичную ошибку:
train_pred = model.predict(x_train_scaled)
train_mse = mean_squared_error(y_train, train_pred)
train_mse
Как видим из вывода эта ошибка составляет 17.27. Это значение абсолютно ничего не значит, пока мы его с чем-нибудь не сравним, а сравнивать мы его будем со среднеквадратичной ошибкой прогноза тестовой выборки:
test_pred = model.predict(x_test_scaled)
test_mse = mean_squared_error(y_test, test_pred)
test_mse
Ошибка в тестовой выборке больше, чем в тренировочной. Это нам говорит о том, что на неизвестных данных модель работает хуже, что в принципе логично, но также можно предположить, что меняется сама модель. Воспользуемся графическим способом, выведя на график прогнозные и фактические значения:
test = pd.DataFrame(list(zip(y_test, test_pred)), index=y_test.index, columns=['Факт', 'Прогноз'])
test.plot(figsize=(24, 6))
Первая строка может показаться непонятной. Нам надо объединить массив test_pred и ряд y_test, которые имеют разную структуру, поэтому сначала создается объединенный список из итератора zip, который передается функцию создания датафрейма. Кроме данных в эту функцию входят индексы и названия колонок. Получаем вот такой график:
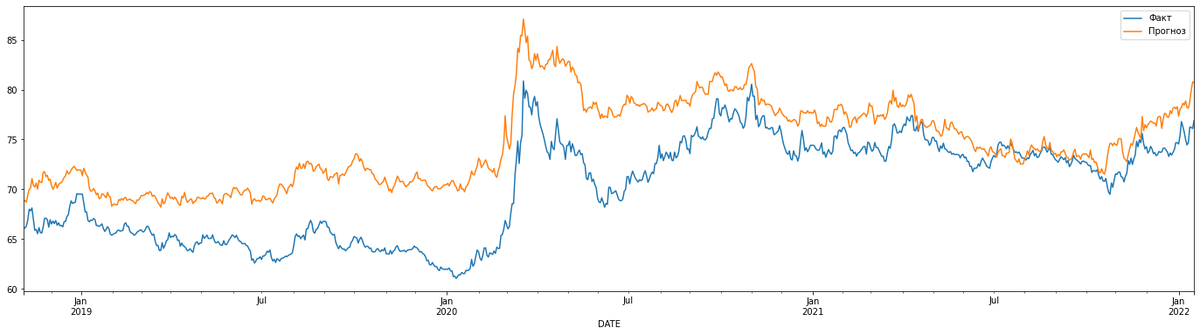
Мы видим, что прогнозные данные могут отклонятся от фактических, в ту или другую сторону. Сейчас прогнозные данные выше фактических. Но не это важно, ведь мы с вами не получили прогноз на предстоящий период. Для этого нам необходимо где-то взять прогнозные значения исходных данных, подставить их в модель и получить целевое значение. Если вы сталкивались с теорией вероятностей, то должны знать, что вероятность независимых параметров надо перемножить, тогда мы получим вероятность целевого параметра, то есть другими словами: точность прогноза упадет в несколько раз.
Мы попробуем совсем другой путь, который заключается в смещении исходных параметров относительно целевого, то есть, например, текущие исходные данные будут соответствовать целевому параметру через 5 дней:
y = df.ruble[5:]
x = df.drop('ruble', axis=1)[:-5]
Для понимания этих команд вам потребуется изучение массивов в python, numpy и pandas, но большинство людей догадываются самостоятельно без дополнительного обучения. Дальше нам надо повторить те же команды начиная с train_test_split. В связи с тем, что они ничем не отличаются от написанных ранее, можно просто еще раз выполнить все ячейки, начиная с той, где разделяются тренировочные и тестовые выборки. Чуть изменилась среднеквадратичная ошибка в треннировочной выборке, а вот ошибка в тестовой выборке снизилась значительно. Давайте посмотрим на график:
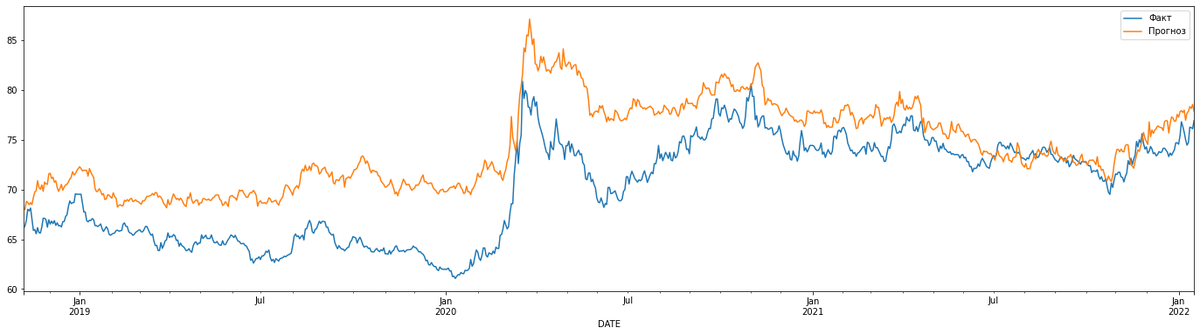
Самое время получить прогноз по оставшимся 5 дням:
x = df.drop('ruble', axis=1)[-5:]
x_scaled = scaler.transform(x)
pred = model.predict(x_scaled)
pred
Он выглядит так: 77.8085758 , 78.55363847, 79.71491351, 80.6072599 , 80.59765329.
Еще раз напоминаю, что данный материал не является инвестиционной рекомендацией, то есть если вы его будете использовать, то только на свой страх и риск.