Каюсь, упустил основную цель, которую обозначил в самом начале. К которой последовательно двигались здесь и здесь, а вот здесь мы вроде как достигли этой цели, но внимательный читатель может вполне закономерно высказать свое "фи", потому что мы прогнозировали только один день вперед. А уже вот тут сказали, что все это неправильно. И так возвращаемся к поставленной цели - получить прогноз (пусть плохой), но на месяц вперед, тем более месяц уже прошел с того момента как мы стали прогнозировать. Поэтому сделаем анализ на старых данных и сравним с реальным значением.
По традиции создаем новый блокнот, который вы можете сравнить с моим. Импортируем библиотеки:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
Загружаем данные из csv-файла:
df = pd.read_csv('/content/drive/MyDrive/usdrub.csv', parse_dates=['date'])
df.info()
Обращаю ваше внимание, что в этот раз мы не назначали дату как индекс, но традиционно парсили дату. Второй командой мы убедились, что все данные загрузились, а date имеет формат datetime64[ns], это обязательное условие, иначе уже в следующих командах вы получите ошибку:
df['year'] = df.date.dt.year
df['month'] = df.date.dt.month
df.tail()
Здесь мы создаем новую колонку year, в которую записываем значение года, а во вновь созданную колонку month - месяц. Последней командой убеждаемся, что все мы правильно сделали. Тем более глаз натыкается на три дня декабря, которые нам надо будет удалить:
df_dt = df[df.date < '2021-12-01']
df_dt = df_dt[['year', 'month', 'close']]
df_dt.tail()
Хорошим тоном является создание новой переменной при удалении и изменении данных, чтобы была возможность вернуться к неизмененным данным, что мы и делаем в первой команде. Во второй команде мы оставляем только те колонки, которые нам потребуются. Ну и, как обычно, убеждаемся в том, что мы все сделали правильно. Сгруппируем наши данные по году и месяцу, а close нам потребуется последний:
df_dt = df_dt.groupby(by=['year', 'month']).last()
df_dt.tail()
Как делать прогноз с помощью модели ARIMA мы уже знаем. Значение p, d и q нам не очень важно, поэтому возьмем минимальные 2, 0, 1:
model = sm.tsa.ARIMA(df_dt, order=(2, 0, 1)).fit()
gr = model.plot_predict()
gr.set_figwidth(24)

Осталось получить прогноз на месяц вперед:
pred = model.forecast()
pred
Результат - 74.75873058, сравним его со фактическим значением, полученным с Московской биржи:
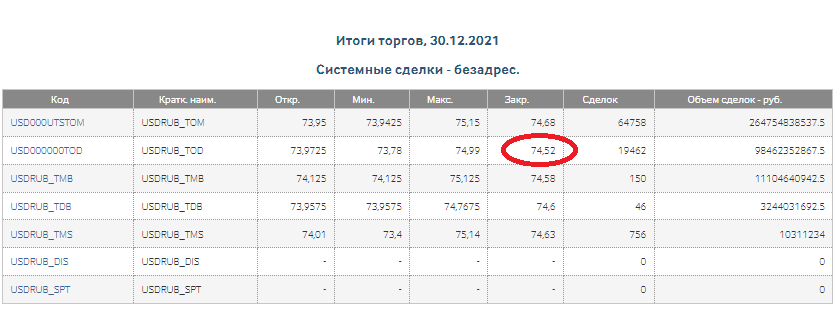
Ну что же, результат очень даже неплохой. Аппетит, как известно приходит во время еды. А не спеть ли нам песню о любви? А не сделать ли нам прогноз на год? Да как два байта переслать:
df_dt = df[['year', 'close']]
df_dt = df_dt.groupby('year').last()
model = sm.tsa.ARIMA(df_dt, order=(2, 0, 1)).fit()
gr = model.plot_predict()
gr.set_figwidth(24)
Понятно, что расхождения будут больше. Получим прогноз на 2022 год:
pred = model.forecast()
pred
Результат даже меня впечатлил - 65.62629775, минимальное значение - 50.77178664, максимальное - 80.48080887. Тут я должен напомнить, что данный материал не является инвестиционной рекомендацией. Если вы будете его использовать, то только на свой страх и риск. Пройдет год, и мы вернемся к этим данным, но не забывайте, что ситуация может поменяться, в результате чего модель может тоже измениться. Вот теперь мы можем продолжить изучение машинного обучения.