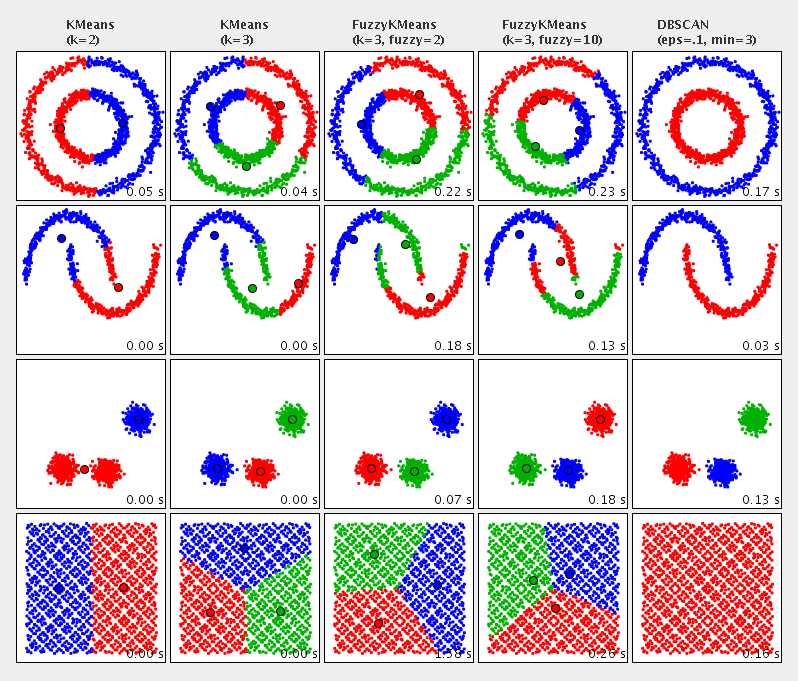
В первой части был проведен беглый анализ потребления алкоголя в Санкт - Петербурге. В этой части наконец то применим Kmeans.
В чем суть алгоритма:
Это наиболее простой метод кластеризации данных. Метод машинного обучения без учителя. Задача метода разбить векторное множество на заданное количество классов путем минимизации среднеквадратичного отклонения на точках заданного кластера.
Посмотреть как работает алгоритм, и поиграться с параметрами можно здесь
Для начала откинем данные ранее 2009 года и добавим дополнительные признаки. А именно как изменялась динамика потребления алкоголя за год.
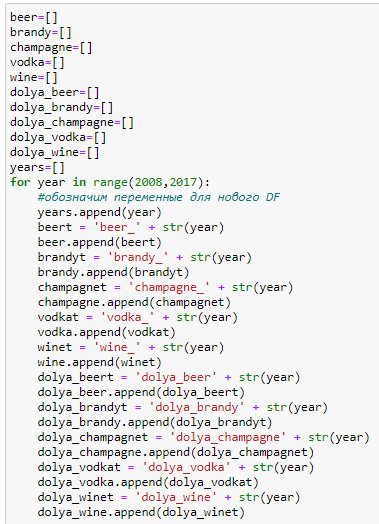
Кратко по коду:
Для того, что бы не прописывать название каждого столбы в ручном режиме создадим списки куда будем складывать методом 'append' названия столбцов. Для этого пробежимся циклом по годам и создадим название столбца из названия категории + год в текстовом формате. Дальше сложим все списки в один и создадим новый ДатаФрейм. И рассчитаем динамику потребления алкоголя по категориям.
Так как метод и так имеет множество недостатков, то упростим жизнь и отмасштабируем наши данные. Иначе мы будет выяснять кто сильнее? Кличко или Паспарту?
Это в свою очередь повысит точность метода (но это не точно, и не всегда помогает... Надо просто поверить и все получиться)))
Для этого используем метод StandardScaler из пакета sklearn
Теперь наши данные не зависят от размерности.
StandardScaler возвращает масив из строк таблицы которой мы подали ему на вход. Поэтому вернем на место название колонок они нам еще пригодятся.
Ну и собственно то ради чего мы тут собрались. Kmeans!
n_clusters - количество кластеров для кластеризации
init - метод метод инициализации
random_state - псевдогенератор случайных чисел. Необходим для дальнейшего воспроизведения экспериментов.
n_init - количество раз когда метод будет выбирать начальные центры случайном образом
algorithm - вид алгоритма вычисления
copy_x - предоставим алгоритму изменять наши данные для возможности их центровки
km.inertia_ сумма квадратов расстояний до ближайшего центра.
на графике отсутствует явный перегиб. Каждое последующее добавление кластера не дает большого сокращения расстояния между точек. Одна из причин - проклятие размерностей. Чем больше признаков у переменной, тем более удалены точки от центра, следовательно добавление числа кластеров не будет приносить пользу. Откинем данные по потреблению алкоголя на душу населения, т.к. они коррелируют с долей потребления алкоголя по виду напитков и прогоним код заново.
В районе 10 расстояние точек от центра падает линейно. Примем число кластеров 8 и обучим модель. получим метки кластеров.
При количестве кластеров более 7 Санкт-Петербург попадает в отдельный кластер.
И это не удивительно, ведь как мы выяснили ранее этот город по многим параметрам является уникальным и метод расценивает это как выброс.
Методом перебора выясняем, что оптимальным числом кластеров является 6.
Вот и список наиболее похожих регионов.
Но их 22, а нам надо 10. Как выбрать наиболее похожие регионы.
Все просто. В нашей таблице 130 признаков для каждого региона.
Это значит, что мы отбирали регионы по признакам в 130 мерном пространстве. И что бы теперь отобрать регионы нам просто нужна узнать расстояния от точки Санкт - Петербурга до других регионов. Делается это при помощи простой формулы из 10 класса
По коду:
сохраняем название регионов в переменную и удаляем регионы из таблицы
отнимаем из всей таблицы признаки Санкт - Петербурга и возводим все в квадрат (делаем разность только положительной)
Берем квадратный корень, возвращаем обратно регионы
Сортируем по возрастанию и вот они топ 10 регионов.
"Теперь мы знаем, что чтобы выпить "культурно" не обязательно ездить в Питер, так как в Вологде пьют практически так же..."
#аналитика #analytics