
В данной статье будет показано применение метода Kmeans для решения задачи, представленной на DataCamp.
И так. Одна из сетей по продаже алкоголя провела акцию по продаже алкоголя в Санкт - Петербурге. Акция оказалась успешной. И руководство захотело провести данную акцию в других регионах нашей страны. Из - за ограничения ресурсов провести данную акцию по всей стране не возможно. Поэтому необходимо выбрать 10 регионов максимально похожих на Санкт - Петербург.
Загрузим набор данных и посмотрим что у нас есть.
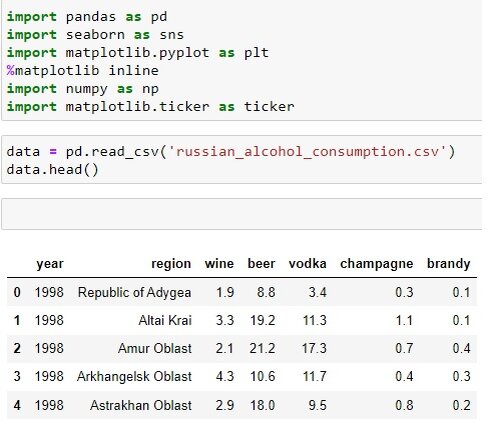
year - год
region - область
wine, bear, vodka, champagne, brandy - потребления напитков на душу населения
Конечно для анализа это очень много. Вряд ли на данных 1998 года можно сделать какие то выводы для решения нашей задачи. И мало вероятно, что есть какая то взаимосвязь от потребления алкоголя в 1998 и 2016 годом. в дальнейшем для анализа будем использовать только данные с 2010 года.
Год и регион категориальные данные. Все остальное это - числа. Есть пропуски в данных. Пропусков мало поэтому просто удалим их. Не видать им скидок на новый год
Данные в таблице представлены в плоском виде (обратите внимание как записаны года: каждый новый год это новая строчка). Это накладывает ограничения в дальнейшем анализе, создания дополнительных фич ( признаков), построения графиков.
Давайте получим уникальный список имен регионов, создадим пустой ДатаФрейм, Передадим в него наш созданный список, И через цикл наполним его данными потребления алкоголя по годам, виду алкоголя. теперь регион будет представлен только в одной строке.
Сразу посчитаем потребление в долях от суммарного объема и отобразим все на графиках.
Все стандартно. из необычного только :
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
код не дает графическому пакету matpotlib устанавливать подписи оси Х на свой вкус , заставляя проставлять года с шагом 1
Ну и сами графики. Вид не очень, но самое главное наглядно и информативно.
2008 год стал переломным в потребление пива. И к 2016 году потребление упало почти в два раза. Напитки покрепче пьются больше и чаше чем в других регионах. Водочку пьют как и все. Средне.
Та же картина, даже четче, наблюдается если посмотреть на доли потребления алкоголя по виду от суммарного объема (алкокорзина). Графики ниже.
Выводы по первой части:
- Выкатить акцию в Питере, в городе с уникальным профилем потребления алкоголя и попытаться отмасштабировать акцию на другие регионы - так себе идея. Но мы все же попробуем отобрать похожие регионы.
- "Культурная столица" имеет уникальную для регионов алкокорзину. Это хорошо и плохо одновременно. Плохое тут в том что многие методы кластеризации эту самую уникальность будут считать выбросами. И при попытки расширить границы в кластер будет попадать куча регионов и решение из "коробки" может не сработать Хорошее - этот же минус можно обратить в плюс при настройке модели, но об этом во второй части.
Разбиение на две части сделано для удобства чтения и написания статьи и не несет за собой попытки набора просмотров...
Обратная связь и критика поддерживается...
Вторая часть
#аналитика #analytics