Это третья статья в данном цикле. Предыдущие статьи можно посмотреть здесь и здесь. В прошлый раз мы с вами закончили тем, что сохранили наши данные в csv. Теперь пришло время загрузить их из csv. И сделаем мы это в новом блокноте, для этого просто создайте новый блокнот, в котором нужно подключить ваш гугл-диск и импортировать библиотеки:
import numpy as np
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/usdrub.csv', parse_dates=['date'])
Почему мы не подключили библиотеку pandas_datareader? Потому что она нам не нужна в этом занятии, мы будем работать с данными из csv. Как вы уже догадались - библиотека pandas содержит функцию read_csv, которая позволяет прочитать csv-файл и передать эти данные в виде датафрейма в переменную df. Эта функция содержит необязательный параметр, который пытается распознать даты в указанных столбцах. В прошлый раз мы говорили, что массивы заключаются в квадратные скобки, но в нашем случае будет только один элемент массива, а именно колонка date.
Весь код, приведенный в статье, вы можете посмотреть здесь. Напоминаю, что код лучше набивать самостоятельно, потому что так лучше запоминается и понимается. Мой блокнот нужен, если вы получили ошибку и не можете разобраться, что вы написали не так. Так же обращаю ваше внимание, что в моем - мои пути, в вашем коде должны быть ваши пути.
Напомню вам задачу, которую мы еще не решили на прошлом занятии: у нас есть дни в которых более одной записи. Для удаления дубликатов (если они есть) имеется определенная функция:
df = df.drop_duplicates()
df.info()
Последнюю функцию мы использовали для проверки результата, а он есть, но остается около двух тысяч записей, которые не являются дублями, но являются лишними. Для получения единственной записи за один торговый день используем функцию группировки по колонке date, а в качестве агрегатной функции будем использовать первое значение:
df = df.groupby('date').first()
df.info()
Вывод последней функции будет следующим:
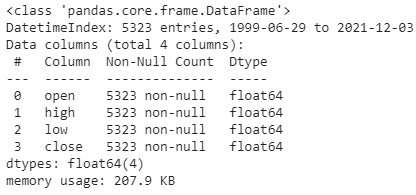
Вот теперь придраться не к чему, но обработка еще не закончена. Обычно хорошей идеей является вывод графика с целью визуальной оценки данных. Для этого мы подключим библиотеку, которую нужно бы подключать в каждом блокноте. Вы можете получить график, и не подключая эту библиотеку, так как она присутствует в зависимостях pandas, но будем считать это необходимым заклинанием, как и в случае с numpy.
import matplotlib.pyplot as plt
gr = df.plot(figsize=(24, 6))
Функция plot нарисует график, используя в качестве данных датафрейм df. Причем по оси Х отложатся даты, потому что они в индексе, а по Y значения наших четырех колонок. Загадочный параметр figsize=(24, 6) позволяет растянуть график по ширине. Если же график уходит за пределы вашего экрана, то можете уменьшить значение 24.
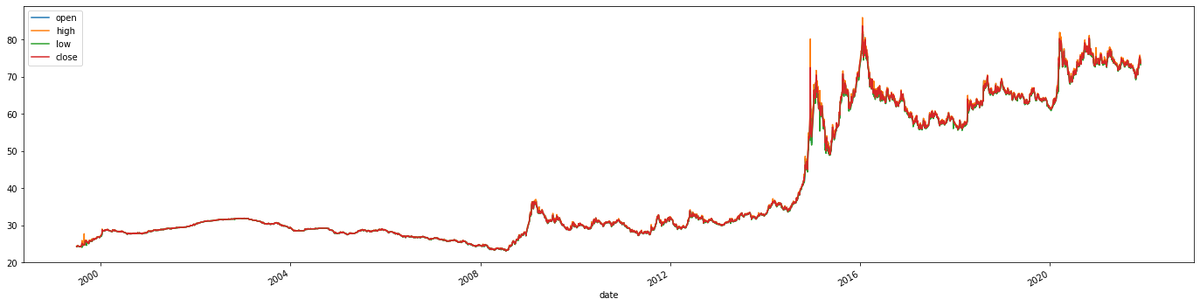
На что вам здесь надо обратить внимание? Во-первых, что 4 цены фактически сливаются в одну, следовательно можно использовать только одно значение вместо 4. Во-вторых, наша обработка дала результат и график выглядит как нормальный график, пусть с выбросами, но без проблемных участков. В-третьих, последняя треть графика сильно отличается от остальных двух третей. Это может означать, что модель построенная на данных из первых двух третей может давать большую ошибку в прогнозировании последней трети.
Но мы пока эту теорию не знаем, поэтому опустим третий вывод. Вместо этого вернемся к первому выводу. Можно ли математическими методами оценить похожесть цен? Для этого в статистике придумали понятие корреляции, которая вполне себе считается как математическая функция, и библиотека pandas имеет такую функцию:
df.corr()
Мы получили таблицу перекрестной корреляции столбцов, которая наглядно показывает, что коэффициент "похожести" почти равен 1 (диагональ из единичек не берите в расчет, так эта диагональ корреляции столбца на себя же). Если вы логически подумаете, то придете к выводу, что наиболее полная информация будет содержаться в столбце close, потому что он содержит информацию за весь день, в отличие от остальных.
Результаты сегодняшней работы мы сохраним в тот же файл с единственным отличием: в этот раз мы не будем использовать параметр index=false. Потому что в этот раз наш индекс содержит даты, которые нам нужны. Соответственно в следующий раз мы будем загружать датафрейм, учитывая, что date это индекс. Кстати, у этой функции есть режим работы для дописывания данных в конец файла, но сейчас он нам не нужен, потому что мы сейчас полностью переписываем файл.
Вам может показаться странным, что мы два занятия изучали обработку данных и даже не добрались до прогнозирования. На самом деле так и происходит: даже если вы создаете нейросети, большую часть времени уходить на обработку данных. Причем то, чем мы сейчас занимались называется предварительной обработкой, а есть еще задачи нормализации, категоризации и т.д. Одним словом, мы только подготовили данные для анализа, чтобы на следующем занятии наконец-то получить первый прогноз.