
Двусторонний тест (англ. Two-Tailed Test, TTT) – метод проверки Выборки (Sample) на принадлежность определенному интервалу значений.
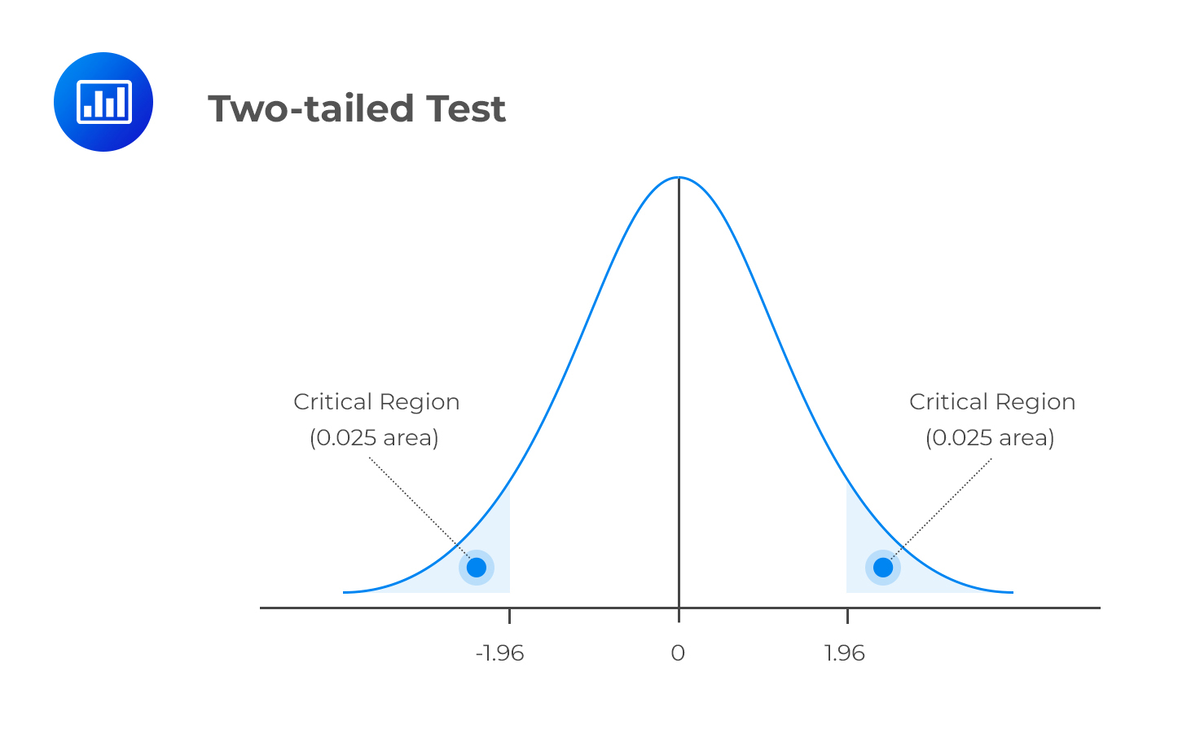
Он используется при проверке Нулевой гипотезы (Null Hypothesis) и проверке Статистической значимости (Statistical Significance): если проверяемая выборка попадает в одну из критических областей, вместо нулевой гипотезы принимается Альтернативная (Alternative Hypothesis).
Нулевая гипотеза: среднестатистическое количество уничтоженных мылом микробов равно 99%.Альтернативная: Мыло в среднем уничтожает менее 99% процентов микробов.
Двусторонний тест – это сравнение среднего значения выборки со средним Генеральной совокупности (Population) – всех имеющихся для исследования значений. Любая точка данных, которая находится вне заданных предела, называется диапазоном отклонения.
Не существует стандарта в отношении количества Наблюдений (Observation), которые находятся в допустимом диапазоне. Например, при создании фармацевтических препаратов, может быть установлен коэффициент в 0,001% или меньше. В случаях, когда точность менее критична, например, количество продуктов в среднем пакете супермаркета, может быть уместным уровень в 5%.
Двусторонний тест также можно использовать для контроля производства: если кондитерская фабрика определяет своей целью 50 конфет в пакете с приемлемым распределением от 45 до 55 конфет, любой пакет, где конфет менее 45 или более 55, считается отклонением и браком.
Чтобы механизмы упаковки считались точными, желательно в среднем 50 конфет в упаковке с соответствующим распределением. Кроме того, количество мешков, попадающих в диапазон отбраковки, должно находиться в пределах предела распределения вероятностей, который считается приемлемым в качестве коэффициента ошибок. Здесь нулевая гипотеза будет заключаться в том, что среднее значение равно 50, а альтернативная гипотеза будет заключаться в том, что оно не равно 50.
Если после проведения двустороннего теста z-показатель попадает в область отклонения, что означает, что отклонение слишком далеко от желаемого среднего значения, то для исправления ошибки может потребоваться корректировка установки или связанного с ней оборудования. Регулярное использование двусторонних методов тестирования может помочь гарантировать, что производительность останется в пределах допустимых пределов в долгосрочной перспективе.
Пример TTT
Представим, что новый брокер Гамма-инвестиции утверждает, что его комиссия ниже, чем у вашего текущего брокера, Тета-инвестиции. Данные, полученные от независимой исследовательской фирмы, показывают, что Среднее значение (Mean) и Стандартное отклонение (Standard Deviation) – мера разброса значений в наборе всех клиентов Тета, равна $18 и $6 соответственно.
Берется выборка из 100 тета-клиентов, и брокерские сборы рассчитываются с новыми ставками брокера Гамма. Если среднее значение выборки составляет 18,75 доллара, а стандартное отклонение выборки равно $6, можно ли сделать вывод о разнице в среднем счете между брокерами?
- H0 (Нулевая гипотеза): среднее равно 18
- H1 (Альтернативная гипотеза): среднее вне диапазона 18 (это то, что мы хотим доказать)
- Стандартное отклонение (критический регион): 2,5% с каждой стороны
- Стандартизованная оценка (Z-Score) – метрика, характеризующая удаленность наблюдения от среднего значения генеральной совокупности. Рассчитывается следующим образом:
(среднее значение выборки - среднее значение гипотезы) / (стандартное отклонение / кв. корень (количество наблюдений)) = (18,75 - 18) / (6 / (кв. корень (100)) = 1,25
Это расчетное значение Z2,5 находится между двумя пределами: -1,96 и 1,96.
Нет достаточных доказательств, что существует какая-либо существенная разница между комиссиями брокеров. Следовательно, нулевая гипотеза не может быть отвергнута.
Двусторонний тест: SciPy
Давайте посмотрим, как TTT реализован в SciPy. Для начала импортируем необходимые библиотеки:
Вызовем встроенный метод default_rng() (англ. default random generator – генератор случайных чисел по умолчанию), чтобы в дальнейшем сгенерировать два набора случайных значений:
Создадим две случайные переменные rvs1 и rvs2 (random variables) с помощью метода norm.rvs(). Параметр loc=5 (location – локация) здесь – среднее значение, равное пяти. scale=10 – стандартное отклонение (мера разброса), равное десяти. size=500 – размер выборки, равный 500.random_state=rng – это способ генерирования случайных значений, необходимый для воспроизводимости эксперимента.
Выполним TTT, вызвав ttest_ind():
Поскольку среднее значение и среднее отклонения равны, и настройка генератора случайных значений тоже, то значение метрики двустороннего теста statistic стремится к единице (~0.99). pvalue – это вероятность появления экстремального наблюдения в интервале от нуля до единицы.
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Автор оригинальной статьи: Adam Hayes
Подари чашку кофе дата-сайентисту ↑