В терминологии программирования строка означает просто последовательность или массив символов. Один символ представляет собой буквенно-цифровое значение. В те дни, когда был изобретен C, символ в компьютере представлялся 7-битным кодом ASCII. Таким образом, строка представляет собой набор множества 7-битных символов ASCII. Однако по мере роста использования компьютеров во всем мире 7-битная схема ASCII стала недостаточной для поддержки символов других языков. Поэтому были предложены различные модели кодирования символов, такие как Unicode, UTF-8, UTF-16, UTF-32 и т. д. Часто задаваемые вопросы по Unicode — интересное место, где можно получить более подробную информацию о них.
Различные языки программирования имеют свою собственную схему кодирования символов. Например, Java изначально использует UTF-16 для отображения между последовательностями шестнадцатибитных кодовых единиц UTF-16 и последовательностями байтов. Go, с другой стороны, использует UTF-8. Оба они являются многобайтовыми кодировками символов. Первоначально UTF-8 был разработан Робом Пайком и Кеном Томпсоном, теми же людьми, которые разработали Go. Строки Go значительно отличаются от строк C и не работают на том же низком уровне, что и C. На самом деле строки Go работают на гораздо более высоком уровне. В отличие от C/C++ и Java или Python, где строки являются постоянными типами последовательностей символов фиксированной длины, строки Go имеют переменную ширину, где каждый символ представлен одним или несколькими байтами в соответствии со схемой кодирования UTF-8. Хотя они ведут себя как массив или фрагмент байтов,
Здесь мы обсудим несколько моментов, связанных со строковым типом и управлением им в Go.
Перейти к строковым функциям
В Golang есть встроенная функция len , которая возвращает длину строки или длину строки в байтах. По схеме массива мы можем получить доступ к i-му байту, где 0<=i<=len(theString). Обратите внимание на следующий фрагмент кода:
theString := "Любовь проявляется в приятном служении"
fmt.Println(len(theString))
Следующий код приведет к панике, потому что мы пытаемся получить доступ к индексу за пределами границ:
fmt.Println(theString[0], " ", theString[len(theString)]) //паника
Вместо этого мы хотели бы написать приведенный выше код следующим образом:
fmt.Println(theString[0], " ", theString[len(theString)-1]) // 76, 101 - (L, e)
В Go есть сокращение для извлечения подстроки. Например, мы могли бы написать:
строка[i:j] (где i<=j)
чтобы получить новую строку, состоящую из байтов исходной строки, начиная с индекса i и заканчивая индексом j-1 . Строка будет содержать ji байт. Следующие результаты приводят к тому же результату, потому что мы можем опустить значения i и j , которые Go считает по умолчанию 0 и len(theString) соответственно.
fmt.Println(theString[0:len(theString)]) // Любовь проявляется в приятном служении
fmt.Println(theString[:len(theString)]) // Любовь проявляется в приятном служении
fmt.Println(theString[0:]) // Любовь проявляется в приятном служении
fmt.Println(theString[:]) // Любовь проявляется в приятном служении
Чтобы извлечь подстроку, мы можем написать следующий код:
fmt.Println(theString[2:8]) // человек
fmt.Println(theString[:8]) // Люблю мужчину
fmt.Println(theString[6:]) //представляется в приятном сервисе
Неизменные характеристики строк Go гарантируют, что строковое значение никогда не может быть изменено, хотя мы можем присвоить новое значение или объединить новое значение, не изменяя исходное значение. Например:
str1 :="пример текста"
str2 := str1 // образец текста
str1 += ", другой образец" // образец текста, другой образец
Но если мы попытаемся изменить исходное строковое значение, это помечает ошибку времени компиляции, потому что нарушает неизменные ограничения строк Go:
str1[4] = 'A' // ошибка!
Сравнение строк в Go
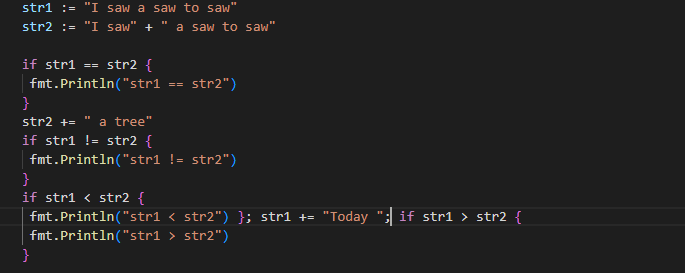
Как разработчикам, нам часто нужно сравнивать две строки, и Go поддерживает все распространенные операторы сравнения, включая == , != , < , > , <= и >= . Сравнение выполняется побайтно и следует естественному лексическому порядку в процессе сравнения. Вот краткий пример того, как сравнить две строки в Go:
Работа с пакетом strconv в Go
При работе со строками нам часто нужно преобразовать строковый тип в числовое значение. Пакет strconv содержит множество функций, которые преобразуют строковое значение для представления многих основных типов данных Go. Например, целочисленное значение может быть преобразовано из строкового представления следующим образом:
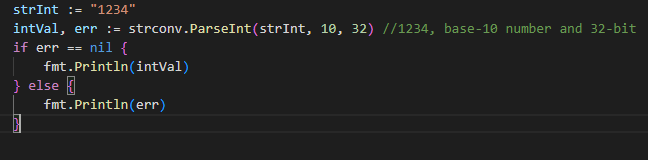
Функция strconv.ParseInt принимает три параметра — строковое значение для анализа, базовый тип и размер в битах. Существуют аналогичные функции для других базовых типов, таких как ParseFloat , ParseBool , ParseUint и ParseComplex для чисел с плавающей запятой, логических значений, целых чисел без знака и комплексных значений соответственно.
Мы также можем преобразовать обратно числовое значение в строку в Go, как показано в следующем примере кода:
floatVal := 3.1415
strFloat = strconv.FormatFloat(floatVal, 'E', -1, 64)
fmt.Println(strFloat)
Функции преобразования, предоставляемые strconv, более универсальны, чем аналогичные функции, такие как FormalBool , FormatInt , FormatUint и FormatComplex . Кроме того, быстрый способ преобразовать значение с плавающей запятой в строку в Go — использовать пакет fmt , как показано в этом примере кода:
f := 2.5678
strFloat := fmt.Sprintf("%f", f)
fmt.Println(strFloat)
Пакет strconv содержит множество функций преобразования, которые работают со строковыми значениями. Ознакомьтесь с документацией Go strconv для получения более подробной информации.
Пакет строк в Go
Пакет strings — еще один служебный пакет для работы со строками. Например, здесь у нас есть строка, содержащая дни недели в качестве данных, где каждый день недели разделен запятой (,). Мы можем разобрать строку и извлечь каждый день недели с помощью функции strings.Split следующим образом:
str := "sun,mon,tue,wed,thu,fri,sat"
weekdays := strings.Split(str, ",")
for _, day := range weekdays {
fmt.Println(day)
}
Таких служебных функций множество. Например, чтобы преобразовать строку в прописные или строчные буквы, мы можем использовать функцию strings.ToUpper(str) или strings.ToLower(str) соответственно. Существуют такие функции, как Trim , которые возвращают фрагмент строки с удаленными всеми начальными и конечными кодовыми точками Unicode в наборах сокращений. Дополнительные сведения см. в документации по строкам Go .
Пакет unicode/utf8 в Go
Пакет unicode/utf8 содержит множество функций для запроса и обработки строк и байтов UTF-8. Он предоставляет функции для перевода между рунами и последовательностями байтов UTF-8. Например, utf8.DecodeRuneInString() и utf8.DecodeLastRuneInString() возвращают первый и последний символы в строке. Вот краткий пример:
q := "A to Z"
fc, size1 := utf8.DecodeRuneInString(q)
fmt.Println(fc, size1)
lc, size2 := utf8.DecodeLastRuneInString(q)
fmt.Println(lc, size2)
Дополнительные сведения см. в документации по Go utf8 .
Заключительные мысли о строках в Go
Go предоставляет обширную поддержку для работы со строками. Существуют и другие пакеты, такие как unicode , которые предоставляют функции для запроса кодовых точек Unicode, чтобы определить, соответствуют ли они определенным критериям. Пакет regexp предоставляет функции для работы со строками с помощью регулярных выражений. Одна из важных вещей, которую нужно понять в отношении строки Go, заключается в том, что то, что мы условно называем отдельными элементами строки символом, на самом деле является последовательностью байтов UTF-8, называемых кодовыми точками, обычно представленными словом руна, которое является псевдонимом для типа int32 . Пакеты Go изобилуют функциями манипулирования строками, здесь мы только коснулись поверхности. Оставайтесь с нами, мы изучим больше.