тест 6
Метод ближайших соседей — простейший метрический классификатор, основанный на оценивании сходства объектов. Классифицируемый объект относится к тому классу, которому принадлежат ближайшие к нему объекты обучающей выборки.
Метод ближайшего соседа является, пожалуй, самым простым алгоритмом классификации. Классифицируемый объект относится к тому классу , которому принадлежит ближайший объект обучающей выборки .
Метод k ближайших соседей. Для повышения надёжности классификации объект относится к тому классу, которому принадлежит большинство из его соседей — ближайших к нему объектов обучающей выборки . В задачах с двумя классами число соседей берут нечётным, чтобы не возникало ситуаций неоднозначности, когда одинаковое число соседей принадлежат разным классам.
Метод взвешенных ближайших соседей. В задачах с числом классов 3 и более нечётность уже не помогает, и ситуации неоднозначности всё равно могут возникать. Тогда -му соседу приписывается вес , как правило, убывающий с ростом ранга соседа . Объект относится к тому классу, который набирает больший суммарный вес среди ближайших соседей.
Гипотеза компактности
Все перечисленные методы неявно опираются на одно важное предположение, называемое гипотезой компактности: если мера сходства объектов введена достаточно удачно, то схожие объекты гораздо чаще лежат в одном классе, чем в разных. В этом случае граница между классами имеет достаточно простую форму, а классы образуют компактно локализованные области в пространстве объектов. (Заметим, что в математическом анализе компактными называются ограниченные замкнутые множества. Гипотеза компактности не имеет ничего общего с этим понятием, и должна пониматься скорее в «бытовом» смысле этого слова.)
Метод потенциальных функций - метрический классификатор, частный случай метода ближайших соседей. Позволяет с помощью простого алгоритма оценивать вес («важность») объектов обучающей выборки при решении задачи классификации. При классификации объект проверяется на близость к объектам из обучающей выборки. Считается, что объекты из обучающей выборки «заряжены» своим классом, а мера «важности» каждого из них при классификации зависит от его «заряда» и расстояния до классифицируемого объекта.
----
Алгоритмы семейства FOREL - FOREL (Формальный Элемент) — алгоритм кластеризации, основанный на идее объединения в один кластер объектов в областях их наибольшего сгущения. Цель - Разбить выборку на такое (заранее неизвестное) число таксонов, чтобы сумма расстояний от объектов кластеров до центров кластеров была минимальной по всем кластерам. То есть наша задача — выделить группы максимально близких друг к другу объектов, которые в силу гипотезы схожести и будут образовывать наши кластеры.
Алгоритм кластеризации, основанный на понятии центра тяжести кластера
-------
Алгоритм К-средних (K-means) - Метод k-средних (англ. k-means) — наиболее популярный метод кластеризации. Был изобретён в 1950-х годах математиком Гуго Штейнгаузом[1] и почти одновременно Стюартом Ллойдом[2]. Особую популярность приобрёл после работы Маккуина[3].
Действие алгоритма таково, что он стремится минимизировать суммарное квадратичное отклонение точек кластеров от центров этих кластеров.
Алгоритм k-средних — это метод векторного квантования, целью которого является разбиение n наблюдений на k кластеров, в которых каждое наблюдение принадлежит кластеру с ближайшим средним/ближайшим центроидом, при этом k < n. Это наиболее широко известный и наиболее часто используемый алгоритм кластеризации.
По аналогии с методом главных компонент центры кластеров называются также главными точками, а сам метод называется методом главных точек[4] и включается в общую теорию главных объектов, обеспечивающих наилучшую аппроксимацию (замена одних объектов другими, в каком-то смысле близкими к исходным, но более простыми) данных.
-----------
Метод главных компонент (англ. principal component analysis, PCA) — один из основных способов уменьшить размерность данных, потеряв наименьшее количество информации. Изобретён Карлом Пирсоном в 1901 году. Применяется во многих областях, в том числе в эконометрике, биоинформатике, обработке изображений, для сжатия данных, в общественных науках[⇨].
Вычисление главных компонент может быть сведено к вычислению сингулярного разложения матрицы данных[⇨] или к вычислению собственных векторов и собственных значений ковариационной матрицы исходных данных[⇨]. Иногда метод главных компонент называют преобразованием Кархунена — Лоэва[1] или преобразованием Хотеллинга (англ. Hotelling transform).
Задача анализа главных компонент имеет, как минимум, четыре базовые версии:
- найти подпространства меньшей размерности, в ортогональной проекции на которые разброс данных (то есть среднеквадратичное отклонение от среднего значения) максимален;
- найти подпространства меньшей размерности, в ортогональной проекции на которые среднеквадратичное расстояние между точками максимально;
- для данной многомерной случайной величины построить такое ортогональное преобразование координат, в результате которого корреляции между отдельными координатами обратятся в нуль.
Первые три версии оперируют конечными множествами данных. Они эквивалентны и не используют никакой гипотезы о статистическом порождении данных. Четвёртая версия оперирует случайными величинами. Конечные множества появляются здесь как выборки из данного распределения, а решение трёх первых задач — как приближение к разложению по теореме Кархунена — Лоэва («истинному преобразованию Кархунена — Лоэва»). При этом возникает дополнительный и не вполне тривиальный вопрос о точности этого приближения.
---------------------------------
Задачей кластеризации наз-ся Задача автоматической классификации с обучением без учителя в нестрогой постановке
Обучение без учителя при решении задачи классификации предполагает Отсутствие обучающей выборки
При оценке качества процедуры кластерного анализа с помощью величины объясненной доли общего разброса необходимо рассчитать:
Общее рассеивание, Межклассовый разброс, Внутриклассовый разброс
-------------
Расстояние Хэмминга - Расстояние, широко используемое для характеристики объектов с бинарными признаками
Расстоя́ние Хэ́мминга (кодовое расстояние) — число позиций, в которых соответствующие символы двух слов одинаковой длины различны[1]. В более общем случае расстояние Хэмминга применяется для строк одинаковой длины любых q-ичных алфавитов и служит метрикой различия (функцией, определяющей расстояние в метрическом пространстве) объектов одинаковой размерности.
Первоначально метрика была сформулирована Ричардом Хэммингом во время его работы в Bell Labs для определения меры различия между кодовыми комбинациями (двоичными векторами) в векторном пространстве кодовых последовательностей: в этом случае расстоянием Хэмминга {\displaystyle d(x,y)} между двумя двоичными последовательностями (векторами) {\displaystyle x} и {\displaystyle y} длины {\displaystyle n} называется число позиций, в которых они различны. В такой формулировке расстояние Хэмминга вошло в словарь алгоритмов и структур данных национального института стандартов и технологий США (англ. NIST Dictionary of Algorithms and Data Structures). Расстояние Хэмминга является частным случаем метрики Минковского
В математике евклидово расстояние между двумя точками евклидова пространства - это длина отрезка прямой между этими двумя точками. Его можно вычислить по декартовым координатам точек, используя теорему Пифагора, поэтому иногда его называют пифагоровым расстоянием. Эти названия происходят от древнегреческих математиков Евклида и Пифагора, хотя Евклид не представлял расстояния в виде чисел, и связь теоремы Пифагора с вычислением расстояния была установлена только в 18 веке.
Евклидова метрика (евклидово расстояние) — метрика в евклидовом пространстве — расстояние между двумя точками евклидова пространства, вычисляемое по теореме Пифагора.

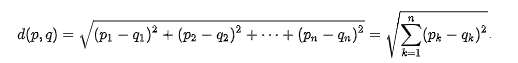
Расстояние Махалано́биса — мера расстояния между векторами случайных величин, обобщающая понятие евклидова расстояния.
Предложено индийским статистиком Махаланобисом в 1936 году[1]. С помощью расстояния Махаланобиса можно определять сходство неизвестной и известной выборки. Оно отличается от расстояния Евклида тем, что учитывает корреляции между переменными и инвариантно к масштабу.
тест 8
Алгоритм, реализующий численную реализацию гипотезы классификации, которая выделяет подмножества или классы, называется:
Классификатором, Алгоритмом классификации
ROC-кривая - Графическая характеристика качества бинарного классификатора, которая отражает зависимость доли верных положительных классификаций от доли ложно положительных классификаций.
График, позволяющий оценить качество бинарной классификации, отображает соотношение между долей объектов от общего количества носителей признака, верно классифицированных как несущие признак, и долей объектов от общего количества объектов, не несущих признака, ошибочно классифицированных как несущие признак при варьировании порога решающего правила.
Задача классификации предполагает, что каждый объект имеет метку Признак принадлежности к некоторому классу
Ошибка классификатора, определяемая как «ошибка ложной тревоги» для бинарного классификатора: Определяет число объектов класса 2, ошибочно признанных за объекты класса 1
Задача классификации, как задача обучения с учителем, предполагает, что:
Множество ответов учителя является конечным, и такие ответы называются метками классов
Предсказательная способность гипотезы классификации обычно оценивается по: Вероятности ошибочной классификации
AdaBoost (сокращение от англ. adaptive boosting) — алгоритм машинного обучения, предложенный Йоавом Фройндом[en] и Робертом Шапире[en]. Может использоваться в сочетании с несколькими алгоритмами классификации для улучшения их эффективности. Алгоритм усиливает классификаторы, объединяя их в ансамбль. Является адаптивным в том смысле, что каждый следующий ансамбль классификаторов строится по объектам, неверно классифицированным предыдущими комитетами. AdaBoost чувствителен к шуму в данных и выбросам. Однако он менее подвержен переобучению по сравнению с другими алгоритмами машинного обучения.
AdaBoost вызывает слабые классификаторы в цикле {\displaystyle t=1,\ldots ,T}. После каждого вызова обновляется распределение весов {\displaystyle D_{t}}, которые отвечают важности каждого из объектов обучающего множества для классификации. На каждой итерации веса каждого неверно классифицированного объекта возрастают, таким образом новый комитет классификаторов «фокусирует своё внимание» на этих объектах.
Алгоритм для задачи построения бинарного классификатора
Два основных действия (шага) алгоритма AdaBoost:
Отбор простых решателей, Комбинирование отобранных решателей
Бэггинг - Извлечение большого количества порций данных из генеральной совокупности, построение предсказательной модели по каждой обучающей выборке и усреднение полученных предсказаний – это:
Бэггинг (от англ. bootstrap aggregating, бутстрэп-агрегирование) — ансамблевый метаалгоритм, предназначенный для улучшения стабильности и точности алгоритмов машинного обучения, используемых в задачах классификации и регрессии. Алгоритм также уменьшает дисперсию и помогает избежать переобучения. Хотя он обычно применяется к методам машинного обучения на основе деревьев решений, его можно использовать с любым видом метода. Бэггинг является частным видом усреднения модели.