
Модель Бокса — Дженкинса (Авторегрессионная интегрированная скользящая средняя, англ. Autoregressive Integrated Moving Average, ARIMA) – Алгоритм (Algorithm) Машинного обучения (ML), позволяющий делать прогнозы на основе Временных рядов (Time Series), т.е. исторических наблюдений.
Если у организации есть возможность лучше прогнозировать объемы продаж продукта, она будет в более выгодном положении для оптимизации уровней запасов. Это может привести к увеличению ликвидности денежных резервов организаций, уменьшению оборотных средств и повышению удовлетворенности клиентов за счет уменьшения количества невыполненных заказов.
В области машинного обучения существует определенный набор методов и приемов, которые особенно хорошо подходят для прогнозирования значения зависимой переменной в зависимости от времени. В этой статье мы рассмотрим Авторегрессионная интегрированная скользящая средняя (ARIMA).
Мы называем ряд точек данных, проиндексированных (т.е. нанесенных на график) в хронологическом порядке временными рядами. Временной ряд можно разбить на 3 компонента.
- Тенденция (Trend): движение данных вверх и вниз в течение длительного периода времени (например, повышение стоимости дома).
- Сезонность (Seasonality): сезонные скачки (например, рост спроса на мороженое летом).
- Шум (Noise): всплески и спады через случайные промежутки времени
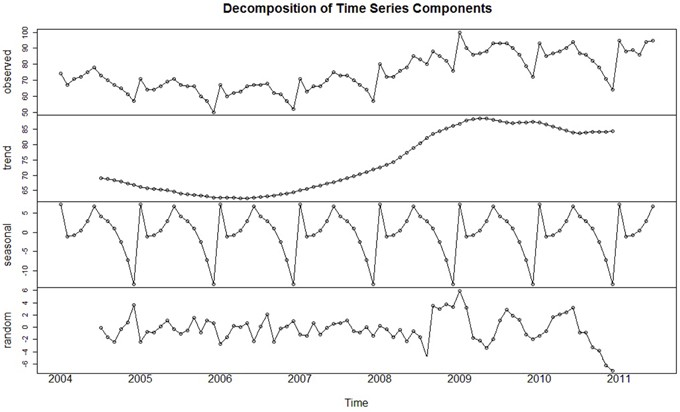
Прежде чем применять какую-либо статистическую модель к временному ряду, мы хотим убедиться, что в нем есть Стацинарность (Stationarity):
Чтобы некоторый временной ряд был классифицирован как стационарный, он должен удовлетворять трем условиям:
- Постоянная Дисперсия (Variance)
- Постоянная ковариация между периодами одинакового расстояния. То есть мера линейной зависимости между периодами времени одинаковой длины (скажем, 10 дней / часов / минут) должна быть идентична ковариации некоторого другого периода такой же длины.
Если временной ряд является стационарным и имеет определенное поведение в течение заданного временного интервала, то можно с уверенностью предположить, что он будет иметь такое же поведение в какой-то более поздний момент времени. Большинство методов статистического моделирования предполагают или требуют, чтобы временные ряды были стационарными.
Стационарность
Библиотека statsmodels предоставляет набор функций для работы с временными рядами. Для начала импортируем необходимые библиотеки:
Мы будем работать с набором данных, который содержит количество пассажиров самолета в определенный день:
Отобразим динамику на графике:
Убедимся, что временной ряд стационарен. Есть два основных способа определить, является ли данный временной ряд таковым:
- Скользящие среднее и Стандартное отклонение (Stabdard Deviation): временные ряды являются стационарными, если эти метрики остаются постоянными во времени (невооруженным глазом видно, являются ли линии прямыми и параллельными оси x).
- Расширенный Тест Дики-Фуллера (ADF): временной ряд считается стационарным, если P-значение (P-Value) низкое в соответствии с Нулевой гипотезой (Null Hypothesis), а критические значения Доверительными интервалами (Confidence Intervals) 1%, 5%, 10% максимально близки к статистике ADF.
Для тех, кто не понимает разницу между средним и скользящим средним: 10-дневное скользящее среднее будет усреднять цены закрытия за первые 10 дней в качестве первой точки данных. Следующая запись исключит цену первого дня, но добавит цену 11-го день и возьмет среднее значение, и так далее, как показано ниже:
Как видите, скользящие среднее и стандартное отклонение со временем растут. Таким образом, можно сделать вывод, что временной ряд не является стационарным.
Статистика ADF далека от критических значений, а P-значение превышает пороговое значение (0,05). Таким образом, можно сделать вывод, что временной ряд не является стационарным.
Взятие логарифма – это простой способ снизить скорость увеличения скользящего среднего.
Давайте создадим функцию для запуска двух тестов, которые определяют, является ли данный временной ряд стационарным.
Есть несколько преобразований, которые мы можем применить к временному ряду, чтобы сделать его стационарным. Например, вычесть скользящее среднее:
Как мы видим, после вычитания среднего скользящее среднее и стандартное отклонение стали приблизительно горизонтальны. P-значение ниже порога 0,05, а статистика ADF близка к критическим значениям. Следовательно, временной ряд стал стационарным.
Модель авторегрессии (AR)
Модели авторегрессии основываются на предположении, что прошлые значения влияют на текущие. Такие методы обычно используются при анализе природы, экономики и других изменяющихся во времени процессов. Пока справедливо предположение, мы можем построить модель Линейной регрессии (Linear Regression), которая пытается предсказать значение зависимой переменной сегодня, учитывая значения, которые она "узнала" о предыдущих днях.
Модель скользящих средних (MA)
Предполагается, что значение зависимой переменной в текущий день зависит от Ошибки (Error) предыдущих дней.
Модель ARIMA, как Вы уже догададись, – это комбинация AR и MA.
ARIMA:
Модель ARIMA использует дифференцирование к модели ARMA. При дифференцировании текущее значение вычитается из предыдущего, и полученная разность используется для преобразования временного ряда в стационарный.
Три целых числа (p, d, q) обычно используются для параметризации ARIMA:
- p: количество членов авторегрессии
- d: количество несезонных различий
- q: количество условий скользящей средней
Стоит также познакомиться с двумя терминами, прежде чем приступить к моделированию будущего числа пассажиров.
Функция автокорреляции (ACF) – корреляция между наблюдениями в текущий момент времени и наблюдениями во все предыдущие моменты времени. Мы можем использовать ACF для определения оптимального количества условий скользящей средней. Количество элементов определяет порядок модели.
Функция частичной автокорреляции (PACF): как следует из названия, PACF является подмножеством ACF. PACF выражает корреляцию между наблюдениями, сделанными в два момента времени, с учетом любого влияния со стороны других точек данных. Мы можем использовать PACF, чтобы определить оптимальное количество элементов для использования в модели AR. Количество элементов определяет порядок модели.
Давайте посмотрим на пример. Горизонтальные фиолетовые пунктирные линии представляют уровни значимости. Вертикальные линии представляют значения ACF и PACF в определенный момент времени. Только вертикальные линии, которые превышают горизонтальные, считаются значимыми.
Таким образом, мы использовали предыдущие два дня в уравнении авторегрессии.
ACF можно использовать для определения наилучших параметров модели MA.
Таким образом, в уравнении скользящего среднего мы будем использовать только предыдущий день.
Возвращаясь к нашему примеру, мы можем создать и подогнать модель ARIMA:
Посмотрим, как модель сравнивается с исходным временным рядом:
Учитывая, что у нас есть данные за каждый месяц за 12 лет и мы хотим спрогнозировать количество пассажиров на следующие 10, мы используем параметр 264 – (12 * 12) + (12 * 10) = 264.
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Автор оригинальной статьи: Cory Maklin