Поймал как-то программист золотую рыбку, а она ему и говорит человеческим голосом: "Отпусти меня в синее море, я исполню любое твое желание". Программист ЦПУшечкой поскрипел, да и выдал техзадание. "Построй мне", – говорит, – "систему обработки неидемпотентных запросов, да чтоб она была высокопроизводительной, масштабируемой, гибкой и отказоустойчивой!". Охнула сперва золотая рыбка, но взяла себя в плавники и молвила: "Не печалься, ступай себе домой, код написан, система развернута. Отпускай меня уже». Удивился программист: «Да ладно? Ну, сейчас проверю и отпущу». "Нет", – возражает рыбка – "пока ты проверяешь, я уж засохну, и все волшебство исчезнет". Программист задумался: "Что же делать: сначала отпустить, а потом проверить, или сначала проверить, а потом сушеную рыбу к пиву получить?".

Мечта многих разработчиков – высокопроизводительная, масштабируемая, гибкая и устойчивая система обработки запросов. Казалось бы, для решения этой задачи есть мегабыстрая Apache Kafka (далее просто Kafka) в качестве брокера сообщений, супергибкий Python для реализации получателя/обработчика сообщений,и ещё какая-нибудь шустрая NoSQL база данных. По отдельности они все прекрасны, как три девицы под окном, но можно ли собрать из них один конвейер для обработки данных и не потерять их важные преимущества?
Семантики чтения: потерять нельзя повторить
Один из основополагающих вопросов, который в первую очередь придется решить при строительстве гибкой и безотказной системы – выбор семантики чтения сообщений. Работу Kafka и ее взаимодействие с консюмерами (т.е. приложениями, которые читают из Kafka сообщения) можно проиллюстрировать следующим примером. Рассмотрим некий проект с менеджером, распределяющим задачи от заказчика между своими сотрудниками (рис. 1).
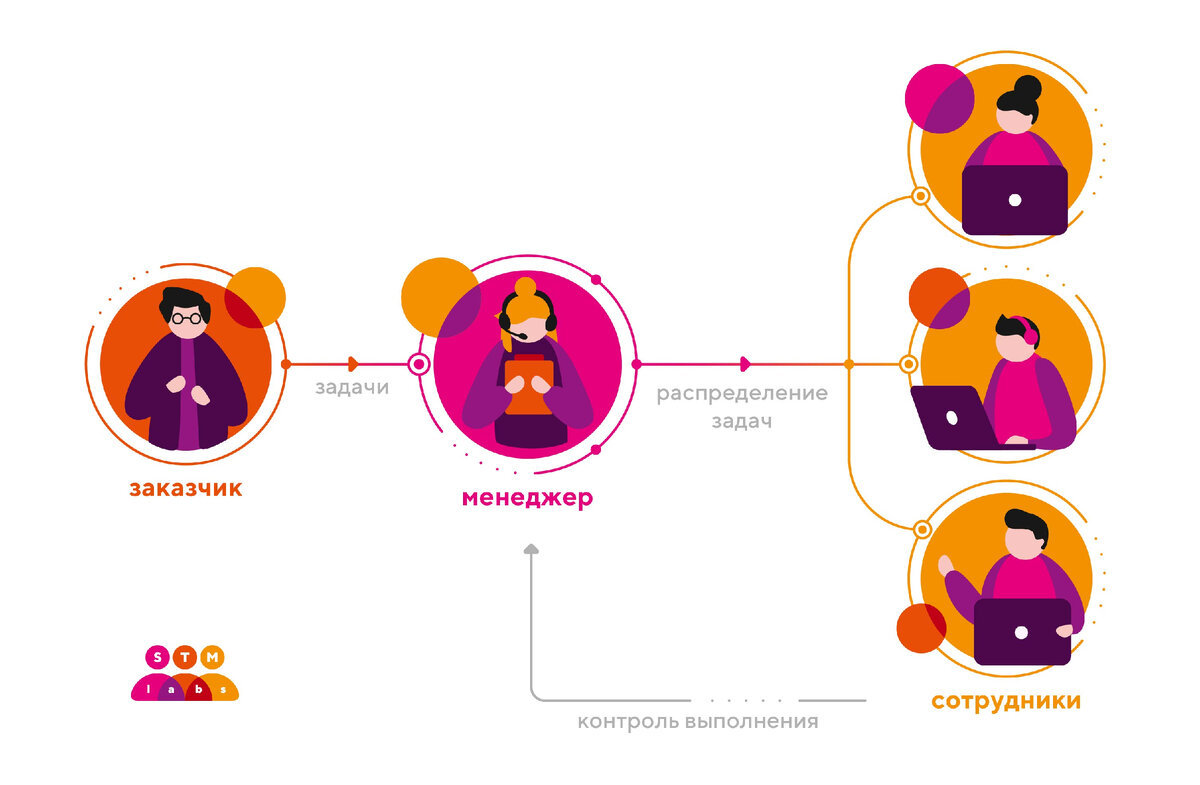
Сотрудник уведомляет менеджера о факте решения задачи, но если он не уложится в заявленный срок, то менеджер должен перекинуть задачу на другого сотрудника. Таким образом, гарантируется решение задачи даже в том случае, если какой-то из сотрудников выбывает из игры. Однако, если последний все же вернется к решению той же задачи, мы получим двойную работу.
В случае семантики "at least once" ("не менее одного раза"), сотрудник сообщает менеджеру, что задача решена только тогда, когда она действительно решена. Плюс в том, что потеря задачи исключена, но при этом мы обязаны смириться с тем, что есть вероятность повторного решения задачи.
В случае семантики "at most once" ("не более одного раза"), сотрудник берет на себя всю ответственность за решение задачи, уведомляя менеджера соответствующим образом сразу же после ее получения. В таком случае исключается вероятность делегирования менеджером этой же задачи другому сотруднику, но если первый исполнитель потерялся, то и задача теряется вместе с ним.
Еще одна семантика – "exactly once" ("ровно один раз") – предполагает, что решение задачи и уведомления о факте решения неотделимы друг от друга. Идеальный вариант – когда уведомление и является решением. Как, например, в формате: вопрос-ответ. Здесь исключены и повторы, и потери.
Очевидное – не значит оптимальное…
Как нам подсказывает Капитан Очевидность, в данной аналогии менеджер соответствует брокеру сообщений (в нашем случае, Kafka), заказчик – продюсеру, а сотрудник – консюмеру.
Консюмеры, реализованные на каком-то из языков программирования, считывают сообщения из брокера и обрабатывают их, записывая информацию в базу данных (рис. 2). Есть немало статей про устройство Kafka, поэтому в данной статье ограничимся лишь общим описанием, и в дальнейшем будем рассматривать конкретно реализацию консюмера на Python.
Продюсеры отправляют сообщения в Kafka в указанные ими топики – такие группы по интересам. Топики состоят из партиций – по сути файлов, куда записываются сообщения с соблюдением порядка (рис. 3). У каждого сообщения свой оффсет – смещение в партиции. Консюмеры считывают сообщения из партиций, подключаясь к ним при установке соединения с Kafka. При этом, если они объединены в группу (consumer group), то члены одной группы не могут читать из одной партиции.
Консюмер подтверждает обработку сообщения, выполняя коммит, т.е. сдвигая текущий оффсет в партиции до оффсета следующего сообщения (рис. 4). После этого он может считать новое сообщение.
Как видно из примера с менеджером, проблема выбора семантики теряет свою актуальность, если консюмер можно реализовать как подсистему Kafka: уместив в одну транзакцию всю обработку сообщения и ее подтверждение. В этом случае Kafka Streams обеспечивает, в том числе семантику "exactly-once", исключая повторы и потери. Однако здесь проблема в том, что невозможно вместить не вмещаемое, каким логика консюмера зачастую и является, да еще и не потерять при этом в скорости обработки. И тут уже остается выбирать между оставшимися двумя семантиками. Мы сейчас детально рассмотрим, что при этом нужно учесть, имея под рукой изящный, и богатый на готовые решения Python.
На первый взгляд семантика "at least once" выглядит предпочтительней: лучше обработать сообщение дважды, чем потерять его совсем. Но что, если нам нужно обрабатывать неидемпотентные запросы? К примеру, запрос на списание денег со счета клиента для оплаты каких-то услуг. И волею Kafka это списание внезапно начинает повторяться и повторяться.
Поэтому, прежде чем делать выводы о применимости той или иной семантики стоит рассмотреть саму ситуацию, приводящую к потерям сообщений, либо повторной обработке.
Как видно на рис. 5, сообщения 2 и 3 успели обработаться. Один из консюмеров подтвердил их обработку, а другой не успел, поскольку у него что-то пошло не так, и он аварийно перезапустился (рис. 6).
Когда какой-либо из обработчиков перестает подавать признаки жизни (не отправляет своевременно хартбиты в Kafka), Kafka выполняет ребаланс – перераспределение партиций между оставшимися в живых обработчиками. Это делается для того, чтобы не оставалось нечитаемых партиций, ведь поток сообщений от продюсеров не останавливается, и их кому-то нужно обрабатывать. Так осиротевшая партиция отдается единственному живому консюмеру (рис. 7).
В следующий момент времени второй консюмер перезагружается, переподключается к Kafka и запрашивает у нее новую задачу. Для оптимального распределения нагрузки на обработчиков при подключении консюмера Kafka снова выполняет ребаланс.
При этом Kafka все равно, какому консюмеру какую партицию отдавать, и это вполне стандартная ситуация, когда перераспределение партиций выполнилось как на рис. 8.
К чему это приводит? Консюмер, обработавший документ 5, пытается закоммитить новый оффсет, но происходит исключение, потому что партиция, к которой этот коммит относится, уже отдана другому консюмеру (рис. 9).
Чем больше консюмеров – тем выше вероятность таких некорректных коммитов и последующих исключений.
Мы должны обработать это исключение, чтоб избежать отключения консюмера. Теперь консюмер сможет прочитать новое сообщение из актуальной партиции, но велика вероятность, что оно уже было обработано ранее другими консюмерами. Просто они не успели закоммитить следующий оффсет до ребаланса. Поэтому мы получим повторную обработку сообщений, что для нас критично, если мы имеем дело с неидемпотентными запросами (рис. 10).
Помимо повторной обработки мы сталкиваемся еще с двумя проблемами. Во-первых, это отсутствие гибкости: пока консюмер обрабатывает одно сообщение, он не может параллельно или асинхронно заняться другими. По крайней мере, из той же партиции, пока не подтвердит обработку сообщения, закоммитив новый оффсет. Во-вторых, мы перегружаем нашего менеджера – брокера сообщений, не имея возможности оперативно его разгрузить за счёт какого-либо дополнительного буфера, например, локального буфера обработчика. Ситуация становится особенно критичной в случае переполнения брокера.
Мы в ответе за тех, кого… прочитали
Посмотрим, что нам даст альтернативное решение – семантика "at most once". Теперь, как только консюмер считал сообщение из Kafka, он должен снять с брокера ответственность за это сообщение, сразу же выполнив коммит. Такой подход позволяет нам распараллелить обработку сообщения внутри консюмера, т.е. он может забирать из Kafka следующее сообщение, не дожидаясь окончания обработки предыдущих.
Сообщения поступают в топик, распределяясь по партициям. Главный процесс консюмера считывает сообщения из Kafka в локальный буфер, в роли которого в нашем случае выступает мультипроцессинговый пул Python с асинхронным выполнением задач. После чего сразу же выполняется коммит (рис. 11).
Из локального буфера сообщение уже вытягивается и выполняется кем-то из дочерних процессов консюмера. Таким образом, сообщения из Kafka быстро перетекают в локальные буферы и процессы консюмеров, снимая нагрузку с брокера (рис. 12).
Конечно, при таком подходе без дополнительных доработок консюмер может сразу считать всё содержимое партиции, на которую он подписан, а далее потерять свою производительность, зависнуть и упасть. Поэтому следует сразу предусмотреть ограничение на заполненность мультипроцессингового пула по размеру его кэша. Чтоб не нарушать инкапсуляцию, мы добавим новый класс пула с возможностью доступа к кэшу, унаследовав это класс от стандартного multiprocessing.pool.Pool.
Поместив в один класс все необходимое для чтения сообщений из Kafka и передачи их в пул процессов для дальнейшей обработки, мы получим следующий прототип консюмера.
Сайд-эффекты, и как с ними бороться
Теперь о том, как разобраться с неотъемлемым спутником решений, основанных на семантике "at most once", – потерями сообщений при отключении консюмера, в котором эти сообщения обрабатываются. Чтоб избежать потерь в случае управляемого отключения (рис. 13), мы добавляем механизм штатного останова: получив сигнал на выключение, приложение перестает тянуть запросы из Kafka и завершается, только когда закончит обработку всех сообщений, находящихся в пуле.
Для реализации механизма штатного останова пополним наш класс MsgConsumer соответствующим методом (не забыв импортировать модуль multiprocessing), который должен вызываться в случае выхода из метода run.
Радоваться, конечно, рано – может произойти аварийное отключение (рис. 14). Рассмотрим эту ситуацию детально.
Отключение консюмера, как мы помним, неизбежно приводит к ребалансу. Через какое-то время отключившийся консюмер перезагружается, переподключается к Kafka, запрашивает у нее новое сообщение, и снова возникает ребаланс. Вероятность некорректного коммита, который мы имели счастье наблюдать ранее, очень мала. Дело в том, что коммит делается практически сразу после считывания сообщения, и, чтобы произошло исключение, ребаланс должен произойти как раз в доли секунды между чтением и коммитом. Если исключение все же случается (рис. 15), мы его обрабатываем и тянем из актуальной партиции новое сообщение.
При этом исключается возможность того, что оно уже было кем-то обработано ранее, т.к. при выбранной нами семантике повторы, в принципе, исключены. К этому, собственно, мы и стремились.
Вернемся к проблеме потери сообщений, находившихся в мультипроцессинговом пуле в момент аварийного отключения консюмера. На этот случай, у нас должна быть предусмотрена обратная связь по каждому сообщению в заявленный срок (рис. 16). Сообщения, по которым до таймаута отсутствует отклик, должны быть переотправлены продюсером повторно.
Выбор зависит от условий
Итак, давайте подведем итог. Решение на основе семантики “at most once” с использованием мультипроцессингового пула в условиях неидемпотентности запросов и возможности организации обратной связи между консюмером и продюсером дает следующие возможности:
· Во-первых, позволяет консюмерам обрабатывать сразу несколько сообщений параллельно или асинхронно;
· Во-вторых, позволяет динамически подключать и отключать консюмеров с минимальной вероятностью исключения из-за ребаланса;
· В-третьих, не требует затрат на предотвращение повторной обработки сообщений в случае ребаланса, т.к. повторы исключены;
· В-четвертых, позволяет быстрее разгрузить Kafka за счет ресурсов подключаемого консюмера при масштабировании. В частности, благодаря тому же мультипроцессинговому пулу;
· В-пятых, учитывая, что продюсер (он же заказчик, он же, к примеру, фронтенд) и так должен предусматривать возможность переотправки сообщений (например, если в сети произошёл сбой, и сообщение вообще не дошло до бэкенда), в консюмере оказывается достаточно минимальной логики предотвращения потерь на основе механизмов обработки исключений и штатного останова, чтобы вся система работала надёжно. Естественно, как уже было сказано, консюмер должен уведомлять продюсера об успешной обработке очередного сообщения.
Неожиданно данный подход – «at most once» – решая сразу три проблемы, добавляет ещё и пару преимуществ. Конечно же, приведённое решение ни в коем случае не претендует на роль оптимальной универсальной стратегии на все случаи обработки данных. Например, если условия таковы, что предотвращать потери запросов необходимо исключительно средствами бэкенда – лучше избрать стратегию, основанную на семантике «at least once». Поэтому в общем случае, выбор стратегии далеко неоднозначен. Но там, где семантика «at most once» применима, она позволит в наиболее полной мере использовать важнейшее преимущество Kafka перед другими брокерами – скорость. В купе с другими преимуществами это позволит вам построить систему высокопроизводительной, масштабируемой, гибкой и отказоустойчивой… Прямо, как в сказке.
…Решил программист все-таки сперва золотую рыбку отпустить: жалко же, если такой уникальный экземпляр на закуску пойдет. А не исполнит она желание – ничего, в следующий раз попадется. Махнула рыбка хвостом и уплыла восвояси. Пошел программист домой, проверил... Чудеса! Все написано, настроено и работает как надо. Ай да рыбка, не обманула! Порадовался программист, но недолго. Работать надо: хоть система и сказочная, а мэйнтенанса требует...