До сих пор мы наблюдали развитие основных абстракций, которые присутствуют в ОС. Мы видели, как взять один физический процессор и превратить его в несколько виртуальных процессоров, тем самым создавая иллюзию одновременного запуска нескольких программ. Мы также видели, как создать иллюзию большой частной (private) виртуальной памяти для каждого процесса; эта абстракция адресного пространства позволяет каждой программе вести себя так, как будто у нее есть своя собственная память, когда на самом деле ОС тайно мультиплексирует адресные пространства в физической памяти (а иногда и на диске).
В этой заметке мы вводим новую абстракцию для одного запущенного процесса: абстракцию потока (thread). Вместо нашего классического представления об одной точке выполнения в программе (т. e. об одном PC (или Program Counter), с которого извлекаются и выполняются инструкции), многопоточная программа имеет более одной точки выполнения (т. е. PCs или (Program Counters), каждый из которых извлекается и выполняется). Возможно, другой способ думать об этом заключается в том, что каждый поток очень похож на отдельный процесс, за исключением одного отличия: они используют одно и то же адресное пространство и, следовательно, могут получать доступ к одним и тем же данным.
Таким образом, состояние одного потока очень похоже на состояние процесса. Каждый поток имеет свой собственный частный набор регистров, которые он использует для вычислений; таким образом, если на одном процессоре работают два потока, при переключении с одного (T1) на другой (T2) должно произойти переключение контекста. Переключение контекста между потоками очень похоже на переключение контекста между процессами, так как состояние регистра T1 должно быть сохранено, а состояние регистра T2 восстановлено перед запуском T2. С процессами мы сохраняли состояние в блоке управления процессом (PCB); теперь нам понадобится один или несколько блоков управления потоками (TCBs) для хранения состояния каждого потока процесса. Однако есть одно существенное отличие в переключении контекста, которое мы выполняем между потоками по сравнению с процессами: адресное пространство остается прежним (т. е. нет необходимости переключать, используемую страницу памяти).
Еще одно важное различие между потоками и процессами касается стека. В нашей простой модели адресного пространства классического процесса (который теперь мы можем назвать однопоточным процессом) имеется один стек, обычно расположенный в нижней части адресного пространства (рис. 26.1, слева).
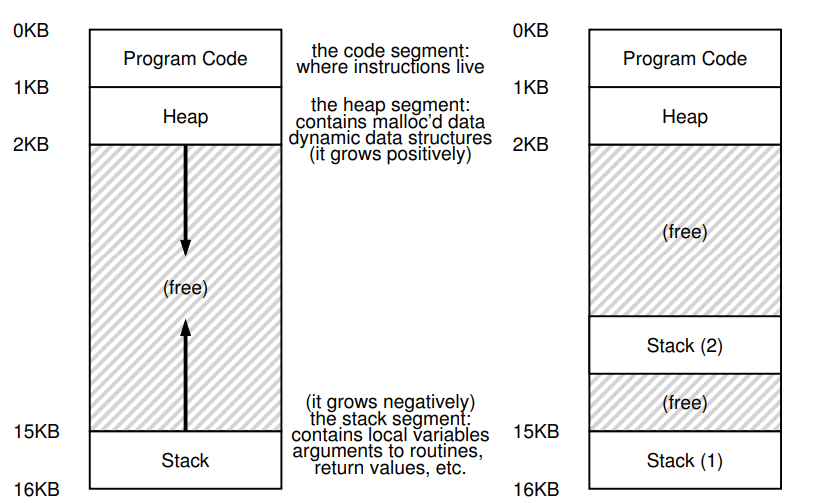
Однако в многопоточном процессе каждый поток выполняется независимо и, конечно, может вызывать различные процедуры для выполнения любой выполняемой им работы. Вместо одного стека в адресном пространстве будет по одному на поток. Допустим, у нас есть многопоточный процесс, в котором есть два потока; результирующее адресное пространство выглядит по-другому (рис. 26.1, справа).
На этом рисунке вы можете видеть два стека, распределенных по всему адресному пространству процесса. Таким образом, любые выделенные стеком переменные, параметры, возвращаемые значения и другие вещи, которые мы помещаем в стек, будут помещены в то, что иногда называют локальным хранилищем потока (thread-local storage), т. е. в стек соответствующего потока.
Вы также можете заметить, как это разрушает нашу прекрасную планировку адресного пространства. Раньше стек и куча могли расти независимо, и проблемы возникали только тогда, когда у вас заканчивалось место в адресном пространстве. Здесь у нас больше нет такой приятной ситуации. К счастью, обычно это нормально, так как стеки обычно не должны быть очень большими (исключение составляют программы, которые интенсивно используют рекурсию).
26.1 Зачем использовать потоки?
Прежде чем углубляться в детали потоков и некоторые проблемы, с которыми вы можете столкнуться при написании многопоточных программ, давайте сначала ответим на более простой вопрос. Зачем вообще использовать потоки?
Как оказалось, есть по крайней мере две основные причины, по которым вам следует использовать потоки. Первая проста: параллелизм. Представьте, что вы пишете программу, которая выполняет операции с очень большими массивами, например, складывает два больших массива вместе или увеличивает значение каждого элемента в массиве на некоторую величину. Если вы работаете только на одном процессоре, задача проста: просто выполните каждую операцию и все будет готово. Однако, если вы выполняете программу в системе с несколькими процессорами, у вас есть возможность значительно ускорить этот процесс, используя процессоры для выполнения каждой части работы. Задача преобразования вашей стандартной однопоточной программы в программу, которая выполняет такую работу на нескольких процессорах, называется распараллеливанием (parallelization), и использование потока на процессор для выполнения этой работы является естественным и типичным способом ускорения работы программ на современном оборудовании.
Вторая причина немного более тонкая: чтобы избежать блокировки выполнения программы из-за медленного ввода-вывода. Представьте, что вы пишете программу, которая выполняет различные типы ввода-вывода: либо ожидает отправки или получения сообщения, либо завершения явного дискового ввода-вывода, либо даже (неявно) завершения page fault. Вместо того чтобы ждать, ваша программа может захотеть сделать что-то еще, в том числе использовать центральный процессор для выполнения вычислений или даже выдавать дополнительные запросы ввода-вывода. Использование потоков - естественный способ избежать застревания; в то время как один поток в вашей программе ожидает (т. е. блокируется в ожидании ввода-вывода), планировщик ЦП может переключиться на другие потоки, которые готовы к запуску и делают что-то полезное. Потоковая передача позволяет совмещать операции ввода-вывода с другими действиями в рамках одной программы, подобно многопрограммированию (ориг. multiprogramming) для процессов в разных программах; в результате многие современные серверные приложения (веб-серверы, системы управления базами данных и т.п.) используют потоки в своих реализациях.
Конечно, в любом из упомянутых выше случаев вы можете использовать несколько процессов вместо потоков. Однако потоки совместно используют адресное пространство и, таким образом, упрощают обмен данными, и, следовательно, являются естественным выбором при создании программ такого типа. Процессы являются более разумным выбором для логически отдельных задач, где требуется небольшое совместное использование структур данных в памяти.
26.2 Пример: создание потока
Давайте разберемся в некоторых деталях. Допустим, мы хотели запустить программу, которая создает два потока, каждый из которых выполняет некоторую независимую работу, в данном случае печатая “A” или “B”. Код показан на рисунке 26.2

Основная программа создает два потока, каждый из которых будет запускать функцию mythread(), хотя и с разными аргументами (строка A или B). Как только поток создан, он может сразу же начать выполняться (в зависимости от прихотей планировщика); с другой стороны, он может быть переведен в состояние “готов”, но не “запущен” и, следовательно, еще не запущен. Конечно, на многоядерном процессоре потоки могут даже выполняться одновременно, но давайте пока не будем беспокоиться об этой возможности.
После создания двух потоков (назовем их T1 и T2) основной поток вызывает функцию pthread join(), которая ожидает завершения определенного потока. Он делает это дважды, тем самым гарантируя, что T1 и T2 будут запущены и завершены, прежде чем, наконец, позволить основному потоку снова запуститься; когда это произойдет, он напечатает “main: end” и завершит работу. В целом, во время этого запуска было задействовано три потока: основной поток, T1 и T2.
Давайте рассмотрим возможный порядок выполнения этой небольшой программы. На диаграмме выполнения (рис. 26.3) время увеличивается в направлении вниз, и каждый столбец показывает, когда выполняется другой поток (main, или Thread 1, или Thread 2).
Обратите внимание, однако, что этот порядок не является единственно возможным. На самом деле, учитывая последовательность инструкций, их довольно много, в зависимости от того, какой поток планировщик решает запустить в данный момент. Например, как только поток создан, он может быть запущен немедленно, что приведет к выполнению, показанному на рисунке 26.4
Мы также могли бы даже увидеть “B”, напечатанный перед “A”, если, скажем, планировщик решил запустить поток 2 первым, даже если поток 1 был создан ранее; нет оснований предполагать, что поток, созданный первым, будет запущен первым. На рисунке 26.5 показан этот окончательный порядок выполнения, при котором поток 2 начинает работу перед потоком 1.
Как вы можете видеть, один из способов думать о создании потока заключается в том, что это немного похоже на вызов функции; однако вместо того, чтобы сначала выполнить функцию, а затем вернуть управление в основной поток, система вместо создает новый поток выполнения для вызываемой процедуры, и он запускается независимо от вызывающего, возможно, он сразу после создания, но, возможно и намного позже. То, что будет выполняться дальше, определяется планировщиком операционной системы, и хотя планировщик, вероятно, реализует какой-то разумный алгоритм, трудно сказать, что будет выполняться в любой данный момент времени.
Как вы также можете понять из этого примера, потоки усложняют жизнь: уже трудно сказать, что и когда будет запущено! Компьютеры достаточно сложны для понимания без параллелизма. К сожалению, при параллелизме положение ухудшается. Сильно ухудшается.
26.3 Почему становится хуже: общие данные
Простой пример потока, который мы показали выше, был полезен для демонстрации того, как создаются потоки и как они могут выполняться в разных порядках в зависимости от того, как планировщик решает их запускать. Однако он не показывает вам, как потоки взаимодействуют, когда они получают доступ к общим данным.
Давайте представим простой пример, когда два потока хотят обновить глобальную общую переменную. Код, который мы будем изучать, показан на рисунке 26.6
Вот несколько заметок о коде. Во-первых, как предлагает Стивенс [SR05], мы завершаем создание потока и объединяем процедуры, чтобы просто выйти при сбое; для такой простой программы, как эта, мы хотим, по крайней мере, заметить, что произошла ошибка (если она произошла), но не делать ничего очень умного (например, просто выйти). Таким образом, Pthread_create() просто вызывает pthread_create() и проверяет, что код возврата равен 0; если это не так, Pthread_create() просто печатает сообщение и завершает работу.
Во-вторых, вместо того, чтобы использовать два отдельных тела функций для рабочих потоков, мы просто используем один фрагмент кода и передаем потоку аргумент (в данном случае строку), чтобы каждый поток мог печатать разные буквы перед своими сообщениями.
Наконец, и это самое главное, теперь мы можем посмотреть, что пытается сделать каждый работник: добавить число в счетчик общей переменной и сделать это 10 миллионов раз (1e7) в цикле. Таким образом, желаемый конечный результат: 20 000 000.
Теперь мы скомпилируем и запустим программу, чтобы посмотреть, как она себя ведет. Иногда все работает так, как мы могли бы ожидать:
К сожалению, когда мы запускаем этот код, даже на одном процессоре, мы не обязательно получаем желаемый результат. Иногда мы получаем:
Давай попробуем еще раз, просто чтобы посмотреть, не сошли ли мы с ума. В конце концов, разве компьютеры не должны выдавать детерминированные результаты, как вас учили?! Может быть, ваши профессора лгали вам? (вздох)
Каждый прогон не только неправильный, но и дает другой результат! Остается большой вопрос: почему это происходит?
СОВЕТ: ЗНАЙТЕ И ИСПОЛЬЗУЙТЕ СВОИ ИНСТРУМЕНТЫ
Вы всегда должны изучать новые инструменты, которые помогут вам писать, отлаживать и понимать компьютерные системы. Здесь мы используем аккуратный инструмент, называемый дизассемблером. Когда вы запускаете дизассемблер для исполняемого файла, он показывает вам, какие инструкции по сборке составляют программу. Например, если мы хотим понять низкоуровневый код для обновления счетчика (как в нашем примере), мы запускаем objdump (Linux), чтобы увидеть код сборки:
prompt> objdump -d main
При этом создается длинный список всех инструкций в программе, аккуратно помеченный (особенно если вы скомпилированы с флагом -g), который включает информацию о символах в программе. Программа objdump - это лишь один из многих инструментов, которые вы должны научиться использовать; отладчик, такой как gdb, профилировщики памяти, такие как valgrind или purify, и, конечно, сам компилятор - это другие, на изучение которых вам следует потратить время; чем лучше вы используете свои инструменты, тем лучшие системы вы сможете построить.
26.4 Суть Проблемы: Неконтролируемое Планирование (Uncontrolled Scheduling)
Чтобы понять, почему это происходит, мы должны понимать последовательность кода, которую компилятор генерирует для обновления переменной counter. В этом случае мы хотим просто добавить число (1) к перем. counter. Таким образом, последовательность кода для этого может выглядеть примерно так (в x86);
В этом примере предполагается, что счетчик переменных расположен по адресу 0x8049a1c. В этой последовательности из трех команд инструкция x86 mov используется первой, чтобы получить значение памяти по адресу и поместить его в регистр eax. Затем выполняется команда add, добавляя 1 (0x1) к содержимому регистра eax, и, наконец, содержимое eax сохраняется обратно в память по тому же адресу. Давайте представим, что один из наших двух потоков (Поток 1) входит в эту область кода и, таким образом, собирается увеличить counter на единицу. Он загружает значение counter (скажем, для начала 50) в свой регистр eax. Таким образом, eax=50 для потока 1. Затем он добавляет единицу в регистр; таким образом, eax=51. Теперь происходит что-то неприятное: происходит прерывание; таким образом, ОС сохраняет состояние текущего запущенного потока (его PC, его регистры, включая eax и т. д.) В TCB потока.
Теперь происходит нечто худшее: для запуска выбирается поток 2, и он вводит этот же фрагмент кода. Он также выполняет первую инструкцию, получая значение счетчика и помещая его в свой eax (помните: каждый поток при запуске имеет свои собственные частные регистры; регистры виртуализируются кодом переключения контекста, который сохраняет и восстанавливает их). Значение счетчика на данный момент все еще равно 50, и, следовательно, поток 2 имеет eax=50. Давайте тогда предположим, что поток 2 выполняет следующие две инструкции, увеличивая eax на 1 (таким образом, eax=51), а затем сохраняя содержимое eax в счетчик (адрес 0x8049a1c). Таким образом, глобальная переменная counter теперь имеет значение 51.
Наконец, происходит еще одно переключение контекста, и поток 1 возобновляет выполнение. Напомним, что он только что выполнил перемещение и добавление, а теперь собирается выполнить последнюю инструкцию mov. Напомним также, что eax=51. Таким образом, последняя инструкция mov выполняется и сохраняет значение в памяти; счетчик снова устанавливается на 51.
Проще говоря, произошло следующее: код для увеличения счетчика был запущен дважды, но счетчик, который начинался с 50, теперь равен только 51. “Правильная” версия этой программы должна была привести к счетчику переменных, равному 52.
Давайте рассмотрим подробную трассировку выполнения, чтобы лучше понять проблему. Предположим, для этого примера, что приведенный выше код загружен по адресу 100 в память, как в следующей последовательности (примечание для тех из вас, кто привык к хорошим наборам инструкций, подобным RISC: x86 имеет инструкции переменной длины; эта инструкция mov занимает 5 байт памяти, а add только 3):
С учетом этих предположений, что происходит, показано на рисунке 26.7. Предположим, что counter начинается со значения 50, и проследите этот пример, чтобы убедиться, что вы понимаете, что происходит.
То, что мы продемонстрировали здесь, называется состоянием гонки (или, более конкретно, гонкой данных): результаты зависят от времени выполнения кода. При некотором невезении (т. e. при переключении контекста, которое происходит в несвоевременные моменты выполнения) мы получаем неправильный результат. Фактически, каждый раз мы можем получать другой результат; таким образом, вместо хорошего детерминированного вычисления (к которому мы привыкли) мы называем этот результат неопределенным, когда неизвестно, каким будет результат, и он действительно, вероятно, будет отличаться в разных запусках.
Поскольку несколько потоков, выполняющих этот код, могут привести к состоянию гонки, мы называем этот код critical section. Critical section - это фрагмент кода, который обращается к общей переменной (или, в более общем смысле, к общему ресурсу) и не должен выполняться одновременно более чем одним потоком.
То, что мы действительно хотим для этого кода, - это то, что мы называем взаимным исключением (mutual exclusion). Это свойство гарантирует, что если один поток выполняется в критической секции, другим это будет запрещено. Кстати, практически все эти термины были придуманы Эдсгером Дейкстрой, который был пионером в этой области и действительно получил премию Тьюринга за эту и другие работы; см. его статью 1968 года “Сотрудничающие последовательные процессы” (Cooperating Sequential Processes) [D68] для удивительно четкого описания проблемы. Мы узнаем больше о Дейкстре в этом разделе книги.
СОВЕТ: ИСПОЛЬЗУЙТЕ АТОМАРНЫЕ ОПЕРАЦИИ
Атомарные операции являются одним из наиболее мощных базовых методов построения компьютерных систем, начиная с компьютерной архитектуры и заканчивая параллельным кодом (то, что мы здесь изучаем), файловыми системами (которые мы изучим достаточно скоро), системами управления базами данных и даже распределенными системами [L+93].
Идея лежащая в основе атомарности выражается фразой “все или ничего”; это должно выглядеть либо так, как будто все действия, которые вы хотите сгруппировать, произошли, либо что ни одно из них не произошло, без видимого промежуточного состояния. Иногда группировка многих действий в одно атомарное действие называется транзакцией, идея, детально разработанная в мире баз данных и обработки транзакций [GR92].
В нашей теме изучения параллелизма мы будем использовать примитивы синхронизации для превращения коротких последовательностей инструкций в атомарные блоки выполнения, но идея атомарности гораздо шире, как мы увидим. Например, файловые системы используют такие методы, как ведение журнала или копирование при записи, для атомарного перехода в состояние на диске, что имеет решающее значение для правильной работы в условиях системных сбоев. Если это пока не имеет смысла для вас, не волнуйтесь — это произойдет в какой-нибудь будущей главе.
26.5 Стремление к атомарности
Одним из способов решения этой проблемы стало бы наличие более мощных инструкции, которые за один шаг делали бы именно то, что нам нужно, и таким образом устраняли возможность несвоевременного прерывания. Например, что, если бы у нас была супер-инструкция, которая выглядела бы так:
Предположим, что эта инструкция добавляет значение в ячейку памяти, и аппаратное обеспечение гарантирует, что она выполняется атомарно; когда инструкция будет выполнена, она выполнит обновление по желанию. Она не может быть прервана в середине инструкции, потому что это именно та гарантия, которую мы получаем от аппаратного обеспечения: когда происходит прерывание, либо инструкция вообще не выполняется, либо она выполняется полностью; промежуточного состояния нет. Оборудование может быть прекрасной вещью, не так ли?
Атомарно, в данном контексте, означает “как единое целое”, которое иногда мы воспринимаем как “все или ничего”. То, что мы хотели бы, - это выполнить последовательность из трех команд атомарно:
Как мы уже говорили, если бы у нас была единственная инструкция для этого, мы могли бы просто выполнить эту инструкцию и все было бы сделано. Но в общем случае у нас не будет такой инструкции. Представьте, что мы строим параллельное B-tree и хотим его обновить; действительно ли мы хотели бы, чтобы оборудование поддерживало инструкцию “атомарное обновление B-tree”? Вероятно, нет, по крайней мере, в разумном наборе инструкций.
Таким образом, вместо этого мы попросим аппаратное обеспечение предоставить несколько полезных инструкций, на основе которых мы сможем построить общий набор того, что мы называем примитивами синхронизации. Используя эту аппаратную поддержку в сочетании с некоторой помощью операционной системы, мы сможем создавать многопоточный код, который получает доступ к критическим разделам синхронизированным и контролируемым образом и, таким образом, надежно выдает правильный результат, несмотря на сложный характер параллельного выполнения. Довольно круто, правда?
Именно эту проблему мы будем изучать в этом разделе книги. Это замечательная и трудная проблема, и она должна вызвать в вашем мозгу боль (немного). Если это не так, то вы не понимаете! Продолжайте работать, пока у вас не заболит голова; тогда вы поймете, что движетесь в правильном направлении. В этот момент сделайте перерыв; мы не хотим, чтобы у вас слишком сильно болела голова.
ПРОБЛЕМА: КАК ОБЕСПЕЧИТЬ СИНХРОНИЗАЦИЮ
Какая поддержка нам нужна от аппаратного обеспечения для создания полезных примитивов синхронизации? Какая поддержка нам нужна от операционной системы? Как мы можем правильно и эффективно построить эти примитивы? Как программы могут использовать их для получения желаемых результатов?
26.6 Еще Одна Проблема: Ожидание Другого
В этой главе рассматривается проблема параллелизма, как если бы между потоками происходил только один тип взаимодействия - доступ к общим переменным и необходимость поддержки атомарности для критических разделов. Как выясняется, возникает еще одно общее взаимодействие, когда один поток должен дождаться, пока другой завершит какое-либо действие, прежде чем оно продолжится. Это взаимодействие возникает, например, когда процесс выполняет дисковый ввод-вывод и переводится в спящий режим; когда ввод-вывод завершается, процесс необходимо вывести из спящего режима, чтобы он мог продолжить.
Таким образом, в следующих главах мы будем изучать не только то, как создать поддержку примитивов синхронизации для поддержки атомарности, но и механизмы поддержки этого типа взаимодействия во время сна/бодрствования, которое часто встречается в многопоточных программах. Если это не имеет смысла прямо сейчас, то все в порядке! Это произойдет достаточно скоро, когда вы прочтете главу о condition variables. Если к тому времени этого не произойдет, что ж, тогда это менее нормально, и вам следует читать эту главу снова (и снова), пока она не обретет смысл.
СРЕДИ ПРОЧЕГО: КЛЮЧЕВЫЕ ТЕРМИНЫ КОНКУРЕНТНОСТИ
CRITICAL SECTION, RACE CONDITION, INDETERMINATE, MUTUAL EXCLUSION
Эти четыре термина настолько важны для параллельного кода, что мы подумали, что стоит назвать их явно. Смотрите некоторые из ранних работ Дейкстры [D65, D68] для получения более подробной информации.
Критический раздел (critical section) - это фрагмент кода, который обращается к общему ресурсу, обычно к переменной или структуре данных
Состояние гонки (или гонка данных [NM92]) (race condition) возникает, если несколько потоков выполнения входят в критическую секцию примерно в одно и то же время; оба пытаются обновить общую структуру данных, что приводит к неожиданному (и, возможно, нежелательному) результату.
Неопределенная (indeterminate) программа состоит из одного или нескольких условий гонки; выходные данные программы варьируются от запуска к запуску, в зависимости от того, какие потоки выполнялись и когда. Таким образом, результат не является детерминированным, чего мы обычно ожидаем от компьютерных систем.
Чтобы избежать этих проблем, потоки должны использовать какие-то примитивы взаимного исключения (mutual exclusion); это гарантирует, что только один поток когда-либо войдет в критическую секцию, что позволит избежать гонок и приведет к детерминированным выводам программы
26.7 Резюме: Почему в классе операционных систем
Прежде чем завершить, у вас может возникнуть один вопрос: почему мы изучаем это на уроке про операционные системы? “История” - это ответ из одного слова; ОС была первой параллельной программой, и для использования в ОС было создано множество методов. Позже, с многопоточными процессами, прикладным программистам также пришлось учитывать такие вещи.
Например, представьте себе случай, когда запущены два процесса. Предположим, что они оба вызывают write() для записи в файл, и оба хотят добавить данные в файл (т. е. добавить данные в конец файла, тем самым увеличив его длину). Для этого оба должны выделить новый блок, записать в индекс файла, в котором находится этот блок, и изменить размер файла, чтобы отразить новый больший размер (среди прочего; мы узнаем больше о файлах в третьей части книги). Поскольку прерывание может произойти в любое время, код, который обновляет эти общие структуры (например, растровое изображение для выделения или индекс файла), является критическими разделами; таким образом, разработчики ОС с самого начала внедрения прерывания должны были беспокоиться о том, как ОС обновляет внутренние структуры. Несвоевременное прерывание вызывает все проблемы, описанные выше. Неудивительно, что таблицы страниц, списки процессов, структуры файловой системы и практически каждая структура данных ядра требуют тщательного доступа с соответствующими примитивами синхронизации для правильной работы.
Ссылки
[D65] “Solution of a problem in concurrent programming control” by E. W. Dijkstra. Communications of the ACM, 8(9):569, September 1965. Pointed to as the first paper of Dijkstra’s where he outlines the mutual exclusion problem and a solution. The solution, however, is not widely used; advanced hardware and OS support is needed, as we will see in the coming chapters.
[D68] “Cooperating sequential processes” by Edsger W. Dijkstra. 1968. Available at this site: http://www.cs.utexas.edu/users/EWD/ewd01xx/EWD123.PDF. Dijkstra has an amazing number of his old papers, notes, and thoughts recorded (for posterity) on this website at the last place he worked, the University of Texas. Much of his foundational work, however, was done years earlier while he was at the Technische Hochshule of Eindhoven (THE), including this famous paper on “cooperating sequential processes”, which basically outlines all of the thinking that has to go into writing multi-threaded programs. Dijkstra discovered much of this while working on an operating system named after his school: the “THE” operating system (said “T”, “H”, “E”, and not like the word “the”)
[GR92] “Transaction Processing: Concepts and Techniques” by Jim Gray and Andreas Reuter. Morgan Kaufmann, September 1992. This book is the bible of transaction processing, written by one of the legends of the field, Jim Gray. It is, for this reason, also considered Jim Gray’s “brain dump”, in which he wrote down everything he knows about how database management systems work. Sadly, Gray passed away tragically a few years back, and many of us lost a friend and great mentor, including the co-authors of said book, who were lucky enough to interact with Gray during their graduate school years.
[L+93] “Atomic Transactions” by Nancy Lynch, Michael Merritt, William Weihl, Alan Fekete. Morgan Kaufmann, August 1993. A nice text on some of the theory and practice of atomic transactions for distributed systems. Perhaps a bit formal for some, but lots of good material is found herein.
[NM92] “What Are Race Conditions? Some Issues and Formalizations” by Robert H. B. Netzer and Barton P. Miller. ACM Letters on Programming Languages and Systems, Volume 1:1, March 1992. An excellent discussion of the different types of races found in concurrent programs. In this chapter (and the next few), we focus on data races, but later we will broaden to discuss general races as well.
[SR05] “Advanced Programming in the UNIX Environment” by W. Richard Stevens and Stephen A. Rago. Addison-Wesley, 2005. As we’ve said many times, buy this book, and read it, in little chunks, preferably before going to bed. This way, you will actually fall asleep more quickly; more importantly, you learn a little more about how to become a serious UNIX programmer.