
Источник: Nuances of Programming
Pandas — одна из наиболее востребованных библиотек Python в повседневной работе с данными. Подобно Numpy она царствует в таких областях программирования, как наука о данных, МО, ИИ, опираясь на свои многочисленные искусно созданные методы, атрибуты и функции. Изо дня в день анализируя данные, мы сталкиваемся с разными незаурядными ситуациями, решения которых находятся сокровищнице встроенного API Pandas и реализуются посредством краткого и качественного кода.
В статье я поделюсь простыми, но очень эффективными приемами, которые превратят процесс программирования в удовольствие. Именно благодаря этим первоклассным функциям Pandas так полюбилась ученым по данным и инженерам МО.
Нижепредставленный датафрейм позволит прояснить ряд концепций, в других же примерах обойдемся без вспомогательных средств.
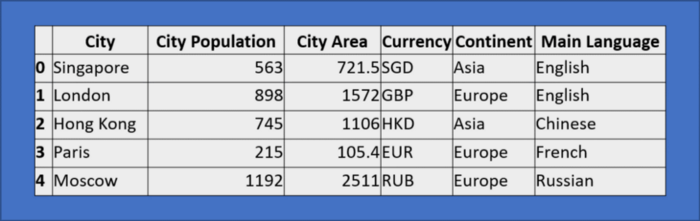
df = pd.DataFrame({'City': ['Singapore','London','HongKong','Paris','Moscow'],
'City Population': [563, 898, 745, 215, 1192],
'City Area': [721.5, 1572, 1106, 105.4, 2511],
'Currency':['SGD','GBP','HKD','EUR','RUB'],
'Continent':['Asia','Europe','Asia','Europe','Europe'],
'Main Language': ['English','English','Chinese','French','Russian']})
1. Сортировка данных по убыванию и возрастанию
В Pandas есть встроенная функция sort_values() для сортировки значений столбца или индекса в порядке возрастания или убывания. Отсортируем столбцы разными способами: один в порядке возрастания, а другой — убывания.
В следующем примере столбец “Continent” отсортирован по возрастанию, а “City Population” — по убыванию (второй уровень сортировки работает с соответствующими значениями первого уровня).
df.sort_values(by = ['Continent','City Population'], ascending=[True,False])
Аналогичным способом можно создать больше уровней сортировки, перечислив в одном списке имена столбцов, а в другом — соответствующий порядок. Используйте ключевые слова “by” и “ascending”, как показано ниже (имя каждого столбца в первом списке соотносится с порядком сортировки во втором).
df.sort_values(by = ['Continent','Main Language','City Population'], ascending=[True,False,True])
2. shift() для смещения данных
Допустим, ситуация требует сместить все строки в датафрейме или отобразить в нем цену акций предыдущего дня. Перед нами может стоять задача вывести среднюю температуру последних трех дней. Так вот shift() идеально подходит для всех этих целей.
Данная функция в Pandas сдвигает индекс на желаемое число периодов. Она принимает скалярный параметр под названием период, который представляет число сдвигов по требуемой оси. shift() пригодится для работы с данными временных рядов. Можно воспользоваться fill_value для заполнения за пределами граничных значений.
import pandas as pd
import numpy as np
df = pd.DataFrame({'DATE': [1, 2, 3, 4, 5],
'VOLUME': [100, 200, 300,400,500],
'PRICE': [214, 234, 253,272,291]})
print(df)
DATE VOLUME PRICE
0 1 100 214
1 2 200 234
2 3 300 253
3 4 400 272
4 5 500 291
df.shift(1)
DATE VOLUME PRICE
0 NaN NaN NaN
1 1.0 100.0 214.0
2 2.0 200.0 234.0
3 3.0 300.0 253.0
4 4.0 400.0 272.0
# с fill_Value = 0
df.shift(1,fill_value=0)
DATE VOLUME PRICE
0 0 0 0
1 1 100 214
2 2 200 234
3 3 300 253
4 4 400 272
При необходимости вывести цену акций предыдущего дня в новом столбце применяем shift() следующим образом:
df['LAST_3_DAYS_AVE_PRICE'] = (df['PRICE'].shift(1,fill_value=0) +
df['PRICE'].shift(2,fill_value=0) +
df['PRICE'].shift(3,fill_value=0))/3
Мы можем легко вычислить среднюю цену акций за три последних дня и создать новый столбец, как показано ниже:
df['LAST_3_DAYS_AVE_PRICE'] = (df['PRICE'].shift(1,fill_value=0) +
df['PRICE'].shift(2,fill_value=0) +
df['PRICE'].shift(3,fill_value=0))/3
Датафрейм приобретает такой вид:
DATE VOLUME PRICE LAST_3_DAYS_AVE_PRICE
0 1 100 214 0.000000
1 2 200 234 71.333333
2 3 300 253 149.333333
3 4 400 272 233.666667
4 5 500 291 253.000000
Можно пойти дальше и получить значение из следующего временного интервала или ряда:
df['TOMORROW_PRICE'] = df['PRICE'].shift(-1,fill_value=0)
В этом случае датафрейм будет выглядеть так:
DATE VOLUME PRICE TOMORROW_PRICE
0 1 100 214 234
1 2 200 234 253
2 3 300 253 272
3 4 400 272 291
4 5 500 291 0
Более подробная информация о данной функции доступна в документации Pandas.
3. Добавление нового столбца в заданном месте датафрейма
С помощью Pandas мы довольно часто создаем новые столбцы для датафрейма. По умолчанию каждый такой столбец добавляется к нему с конца. Создадим новый столбец со значениями плотности населения для представленных в датафрейме городов (“City Population” / “City Area”). Новое поле по умолчанию будет выглядеть так:
df['Population density'] = df['City Population']/df['City Area']
При необходимости создать столбец в определенном месте датафрейма, например между “City Area” и “Currency”, воспользуемся функцией insert.
df.insert(loc=3, column='Population density', value=(df['City Population']/df['City Area']))
4. value_counts() для нахождения уникальных значений
Функция Pandas value_counts() возвращает объект, содержащий число уникальных значений. Полученный объект можно отсортировать по убыванию или возрастанию, включая или исключая NA посредством управления параметрами. Данная функция применяется с индексом или сериями Pandas.
a = pd.Index([3,3,4,2,1,3, 1, 2, 3, 4, np.nan,4,6,7])
a.value_counts()
#Вывод
3.0 4
4.0 3
1.0 2
2.0 2
7.0 1
6.0 1
dtype: int64
Ниже представлен пример серии:
#Ввод
b = pd.Series(['ab','bc','cd',1,'cd','cd','bc','ab','bc',1,2,3,2,3,np.nan,1,np.nan])
b.value_counts()
#Вывод
bc 3
cd 3
1 3
3 2
ab 2
2 2
dtype: int64
Можно воспользоваться опцией bin вместо подсчета уникальных значений и разделить индекс в указанном количестве полуоткрытых интервалов.
Более подробная информация о данной функции представлена в документации Pandas.
5. Выбор столбца на основе типа данных
Во многих случаях требуется выбрать или выполнить определенные операции на основе типа данных столбцов. Допустим, наша задача — применить маску ко всем целым числам с плавающей точкой или преобразовать все столбцы с символьными данными в верхний регистр. В Pandas для этой цели существует один эффективный подход — встроенная функция select_dtypes. У нее есть опции include (включение)и exclude (исключение), и в форме списка мы можем задавать несколько их вариантов.
Сначала с помощью встроенного атрибута dtypesвыясним, какие типы данных присутствуют в датафрейме.
Теперь выберем только столбцы, содержащие значения float, воспользовавшись select_dtypes, как показано ниже:
Также можно воспользоваться exclude для выбора всех типов данных, кроме исключенных. Например, в этом примере уберем все типы данных object:
Исключение или включение нескольких типов данных происходит посредством списка. Помимо этого, допускаются комбинации этих операций.
df.select_dtypes(exclude=['int64','float64'])
df.select_dtypes(include='number',exclude='float64')
6. mask() для условия if-else
Метод mask() представляет собой применение условия if-then для каждого элемента серий или датафрейма. Если cond равно True, то используется значение из other (значение по умолчанию — NaN), в противном случае сохраняется исходное значение. Данный метод аналогичен where().
Обратимся к датафрейму, в котором нужно изменить знак всех элементов, кратных двум без остатка.
Эта задача легко решается с помощью функции mask().
df = pd.DataFrame(np.arange(15).reshape(-1, 3), columns=['A', 'B','C'])
print(df)
#Вывод
A B C
0 0 1 2
1 3 4 5
2 6 7 8
3 9 10 11
4 12 13 14
#С помощью mask проверяем делится ли элемент на 2 без остатка.
#При соотвествии условию меняем знак элемента
df.mask(df % 2 == 0,-df)
#Вывод
A B C
0 0 1 -2
1 3 -4 5
2 -6 7 -8
3 9 -10 11
4 -12 13 -14
Более подробная информация о данном методе предоставлена в документации Pandas.
7. Фильтрация столбцов на основе частичного совпадения
Ежедневно обрабатывая данные, мы сталкиваемся с ситуациями, в которых нужно найти столбцы, связанные друг с другом совпадающими именами. При этом совпадение может быть не полным, а частичным. Допустим, необходимо вывести все столбцы, содержащие “date” или “amount”. В таких случаях не обойтись без функции filter. В рассматриваемом датафрейме найдем все столбцы, включающие “City”. При этом нужно обратить внимание на регистр сопоставляемых строк, так как он имеет значение.
Далее рассмотрим примеры, в которых мы получаем требуемые результаты:
df.filter(like='la', axis=1)
df.filter(like='Po', axis=1)
df.filter(like='tion', axis=1)
8. nlargest() для определения наибольших значений
Зачастую требуется найти три наибольших или пять наименьших значений в сериях или датафрейме (например, трех лучших студентов с их суммарным баллом или трех худших кандидатов с общим числом голосов, полученных на выборах).
Как раз для таких целей Pandas предоставляет nlargest() и nsmallest().
Далее следует пример, отображающий 3 наибольших значения высоты в датафрейме из 10 имеющихся результатов измерения:
import pandas as pd
import numpy as np
df = pd.DataFrame({'HEIGHT': [170,78,99,160,160,130,155,70,70,20],
'WEIGHT': [50,60,70,80,90,90,90,50,60,70]},
index=['A','B','C','D','E','F','G','H','I','J'])
print(df)
HEIGHT WEIGHT
A 170 50
B 78 60
C 99 70
D 160 80
E 160 90
F 130 90
G 155 90
H 70 50
I 70 60
J 20 70
dfl = df.nlargest(3,'HEIGHT')
print(dfl)
HEIGHT WEIGHT
A 170 50
D 160 80
E 160 90
При наличии повторяющихся значений опции first, last, all помогают выбрать нужные (по умолчанию first). Оставим все три полученных варианта и попробуем найти 2 наибольших значения высоты, как показано в примерах:
dfl = df.nlargest(2,'HEIGHT',keep='all')
print(dfl)
HEIGHT WEIGHT
A 170 50
D 160 80
E 160 90
Оставляем последнее значение с конца:
dfl = df.nlargest(2,'HEIGHT',keep='last')
print(dfl)
HEIGHT WEIGHT
A 170 50
E 160 90
Оставляем первое полученное значение:
dfl = df.nlargest(2,'HEIGHT',keep='first')
print(dfl)
HEIGHT WEIGHT
A 170 50
D 160 80
С более подробной информацией о данной функции можно ознакомиться в документации Pandas.
9. nsmallest()
nsmallest() работает аналогичным образом, но только в отношении наименьших значений. В следующих примерах найдем 2 наименьших значения веса:
import pandas as pd
import numpy as n
pdf = pd.DataFrame({'HEIGHT': [170,78,99,160,160,130,155,70,70,20],
'WEIGHT': [50,60,70,80,90,90,90,50,60,70]},
index=['A','B','C','D','E','F','G','H','I','J'])
print(df)
HEIGHT WEIGHT
A 170 50
B 78 60
C 99 70
D 160 80
E 160 90
F 130 90
G 155 90
H 70 50
I 70 60
J 20 70
dfs = df.nsmallest(3,'WEIGHT')
print(dfs)
HEIGHT WEIGHT
A 170 50
H 70 50
B 78 60
Документация Pandas содержит более подробную информацию о данной функции.
Заключение
Рассмотренные функции Pandas отличаются не только эффективностью, но также содержательностью, простой и краткостью. С течением лет API Pandas подвергся серьезной доработке и теперь предоставляет множество встроенных функций, требующих немало строк кода, или лямбда-функций для выполнения требуемых операций с данными. Надеюсь, материал был вам полезен.
Благодарю за внимание!
Читайте также:
Перевод статьи Baijayanta Roy: “9 Awesome Python Pandas Usages Every Data Scientists Should Know”