В этой статье речь пойдет о приемах, которые открывают двери в мир парсинга сложных строк, их использование может значительно сократить ваши муки при разборе таких конструкций.
Отмена вывода группы
Создадим демонстрационные строки, подключим библиотеку re и напишем простейшее регулярное выражение:
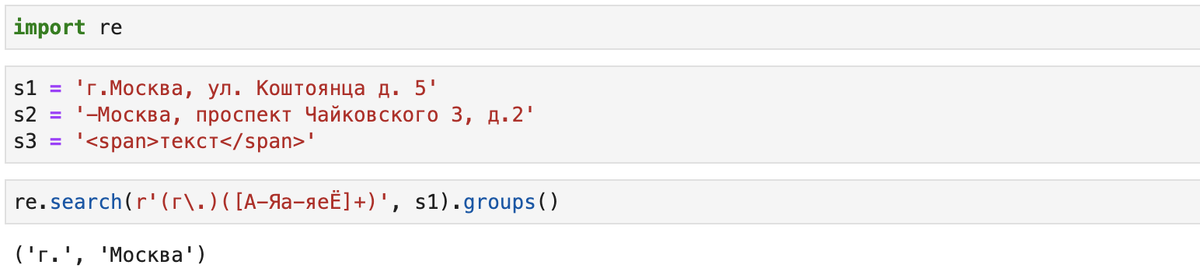
Как мы видим, все, что заключено в круглые скобки включается в итоговый вывод. Но так как эти скобки также используются для группировки выражений, такой поведение не всегда желательно. Если мы хотим отменить вывод следует после открывающейся скобки добавить два следующих символа ":?":

Условный поиск
В регулярных выражениях можно задавать разные конструкции поиска в зависимости от нахождения шаблона. В общем виде это выглядит так:
(?(id или name шаблона)вариант1|вариант2)
Вот пример работы для наших двух строк в зависимости от наличия в них символов "г.":
Обратите внимание, если убрать в строке s2 символ "-", то получим ошибку, так как регулярное выражение требует, чтобы при условии отсутствия "г." в строке имелось "-М":
Именование частей
Исключительную пользу при работе со сложными регулярными выражениями представляет именование групп поиска, которое задается после открывающейся скобки символами "?P<имя>". Впоследствии именованные группы можно получить в виде словаря посредством метода groupdict. Перепишем способ поиска по условной конструкции с включением именования:
Ссылки на поисковые вхождения
На группы вхождения можно ссылаться в последующих частях регулярного выражения, что полезно, например, при поиске в тегах. Для ссылки по id группы используется конструкция "\id", а по имени (?P=name):